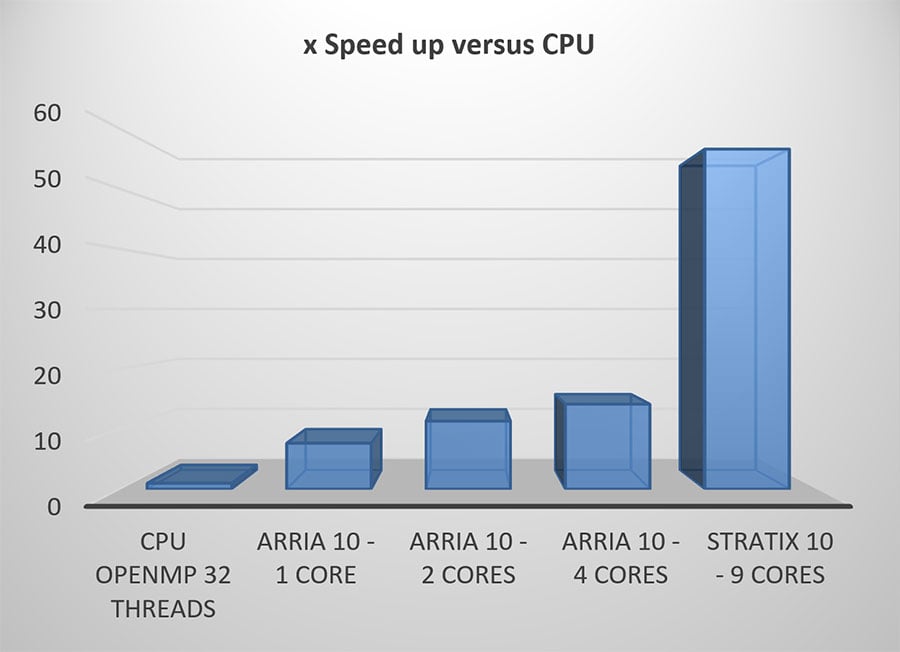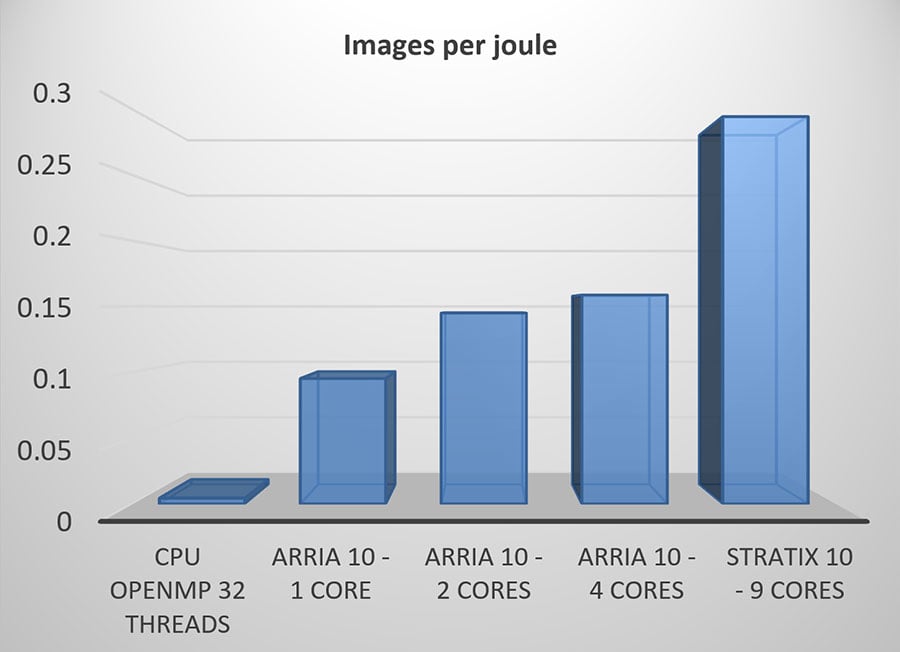


FPGA Optimizations
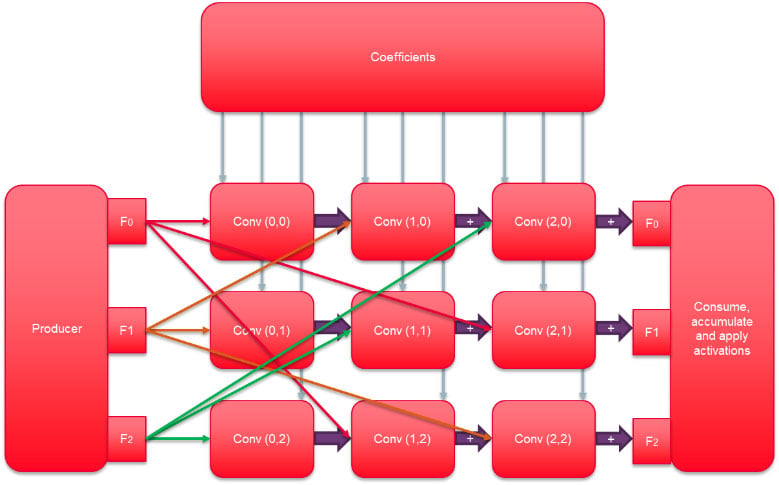
Firstly, binarization of the weights reduces the external memory bandwidth and storage requirements by a factor of 32. The FPGA fabric can take advantage of this binarization as each internal memory block can be configured to have a port width ranging from 1 to 32 bits. Hence, the internal FPGA resource for storage of weights is significantly reduced, providing more space for parallelization of tasks.
The binarization of the network also allows the CNN convolutions to be represented as a series of additions or subtractions of input activations. If the weight is binary 0, the input is subtracted from the result; if the weight is binary 1, it is added to the result. Each logic element in an FPGA has additional carry chain logic that can efficiently perform integer additions of virtually any bit length. Utilizing these components efficiently allows a single FPGA to perform tens of thousands of parallel additions. To do so the floating point input activations must be converted to fixed precision. With the flexibility of the FPGA fabric, we can tune the number of bits used by the fixed additions to meet the CNN’s requirement. Analysis of the dynamic range of activations in various CNNs shows that only a handful of bits, typically 8, are required to maintain an accuracy to within 1% of a floating point equivalent design. The number of bits can be increased for more accuracy.
There are many different networks that could be investigated for BNN applications, and it is tempting to pick one of the many simpler networks such as AlexNet. However, to really understand the effectiveness of FPGAs for BWNN processing, it is better to use a state-of-the-art network, such as YOLOv3. This is a large convolution network with many convolution layers.
YOLOv3 is a deep network, and errors introduced due to fixed point rounding require more bits per addition than smaller networks like AlexNet. The advantage of FPGA technology is the ability to modify the precise number of bits required. For our design, we used 16 bits to represent the data transferred between layers.
Converting to fixed point for the convolution and removing the need for multiplications via binarization dramatically reduces the logic resources required within the FPGA. It is then possible to perform significantly more processing in the same FPGA compared to a single precision or half precision implementation, or free up FPGA logic for other processing.
Targeted Network Training
The YOLOv3 network is a large convolutional network with 106 layers that not only identifies objects, but also places bounding boxes around these objects. It is particularly useful in applications that require objects to be tracked.
Binary weighted networks reduce the accuracy of the YOLOv3 network only marginally if appropriately trained. The following table illustrates the results obtained for the retrained YOLOv3 network.

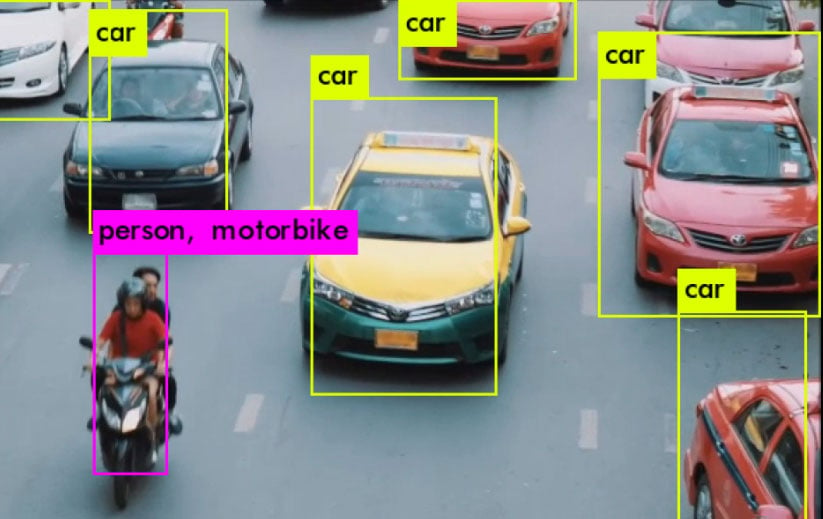
The average confidence in this image for bicycles was 76%, and for people was 82%. Compare that to the floating-point on the same image, which would achieve 92% average accuracy on bicycles (16% better) and 88% on people (6% better).
To achieve the best performance for the FPGA, it helps to target network features that map best to the FPGA. In this case not only was the network trained for binary weights, appropriate activation types were chosen that mapped efficiently to the FPGA logic.