This is Sean Gibb, vice-president of engineering at Eideticom. In this video, we will demonstrate the use of Eideticom’s Query Processing Unit, or QPU, for formatting and filtering stock-ticker data stored in a comma-separated text format.
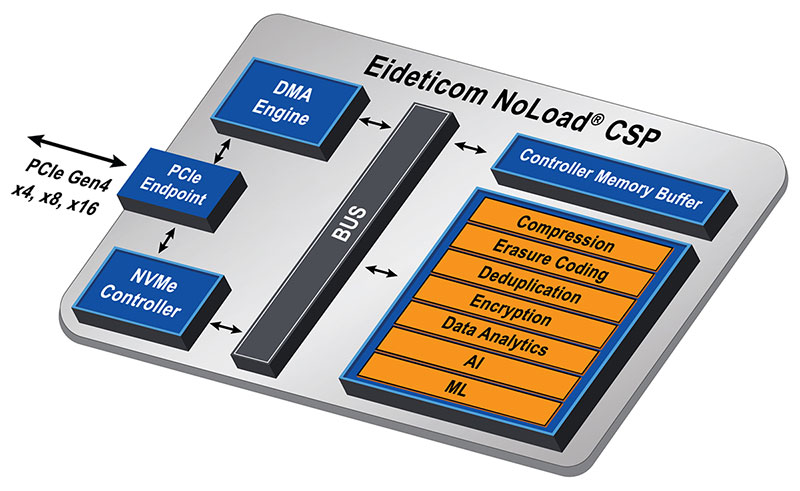
The embedded processors in Eideticom’s QPU are software programmable using C or C++, allowing you to dynamically program your filtering functions.
In addition to the embedded processors, easy to use, high-throughput, hardware co-processors (that perform common tasks like packet capture analysis, conversion from text to binary formats, and simple filtering) are available to your embedded software to accelerate your query workloads.
In this example, we use the text-to-binary formatter to convert CSV to binary data, perform a runtime-configurable hardware filter (to filter out specific stock symbols and low-volume trades), and then perform a software filter to remove all trades where the day closes lower than it opens.
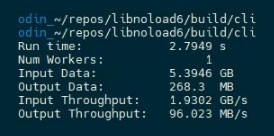
We compile the software using a GCC compiler to produce an executable that we can load through our software stack into the embedded processors. Once the software’s loaded, we run 5GB of CSV data through the Query Engine, filtering for all Microsoft stocks with a volume that exceeds 10 million.
You can see here that a single Query Engine is capable of sustaining 2GB/s of text input. We can tile down multiple Query Engines and, thanks to Eideticom’s software stack, saturate the PCIe interface to the FPGA card with the same host software.
This is just one example of what Eideticom’s software-programmable, hardware-accelerated QPU can do for you.