The ever-increasing connectivity in the world is generating ever-increasing levels of data. Machine learning, when applied correctly, can learn to extract patterns and interactions within this data. FPGA technology can help.
Machine learning is a branch of artificial intelligence (AI) where algorithms and data are used to create a system that can perform a certain task. The accuracy of the system is slowly improved as more data is processed, referred to as training. Once accurate enough this system can be considered trained and then deployed in other environments. Here the same learned algorithm is used to infer the statistical probability of an outcome. This is referred to as inference.
Neural networks form the foundation of most machine learning tasks. These consist of multiple compute layers whose interactions are based on coefficients learned during training. This whitepaper focuses on the inference of neural networks on FPGA devices, illustrating their strengths and weaknesses.
Dive Deeper into Machine Learning
Read the CNN White Paper
See how convolutional neural networks can be accelerated using FPGA accelerator products from BittWare
At the heart of neural networks are huge numbers of multiply accumulate calculations. These calculations simulate the interaction of thousands of neurons, producing a statistical likelihood of something occurring. For image recognition this is a confidence factor that the network is observing a particular object. It can of course be wrong. For example, humans regularly see human faces in inanimate objects! Any system will therefore require a certain tolerance to incorrect results. The statistical nature of these results provides opportunities to vary the dynamic range of the computations, so long as the final answer remains within a satisfactory level of accuracy defined by the tolerance of the application. Consequentially inference provides opportunities to be creative with data types used.
Data widths can often be reduced to 8-bit integers and in some cases can be decreased to a single bit. FPGAs can be configured to process data types of almost any size, with little or no loss in compute utilization.
In respect to neural network inference, ASICs, CPUs, GPUs and FPGAs have their advantages and disadvantages. Custom chips (ASICs) offer the highest performance and lowest cost, but only for targeted algorithms – there is no flexibility. In contrast, CPUs offer the greatest programming flexibility, but at lower compute throughput. GPU performance is typically much higher than a CPU and improved further when using a large batch number, i.e. processing many queries in parallel. In latency critical real-time systems, it is not always possible to batch input data. This is one area where FPGAs are somewhat unique, allowing neural networks to be optimized for a single query, while still achieving a high-level compute resource utilization. When an ASIC does not exist, this makes FPGAs ideal for latency critical neural network processing.
Inline Processing
Figure 1 illustrates the typical accelerator offload configuration for an FPGA. Here coefficient data is updated load to attached deep DDR or HBM memory and accessed by the AI inference engine when processing data transferred from the host. GPUs typically outperform FPGAs for high batch numbers, however if small batch sizes or low latency are the overriding constraints of a system, then FPGAs offer an attractive alternative.
Figure 1 : FPGA Inference offload
Where FPGAs particularly excel is in the combination of AI inference with other real-time processing requirements. FPGAs’ reconfigurable IO can be customized for different connectivity problems, from high-speed Ethernet to Analog sensor data. This makes FPGAs unique for performing complex inference at the edge, when an ASIC does not exist. Devices can also use the same IO to connect multiple FPGAs together in a configuration best suited to the application or to fit within existing server connectivity. Connections can be bespoke or follow standards such as Ethernet.
Figure 2 : An example of using inference within a data pipeline line
For inline processing, a neural network need only be capable of processing data at line rate. In this case the FPGA will only use the resources necessary to keep up with the desired throughput and no more. This saves power and leaves extra FPGA real-estate for other tasks such as encryption.
Encryption
There are significant opportunities for machine learning in areas where data privacy is important. For example, medical diagnostics could benefit from cloud acceleration. However, patient data is confidential and disaggregated across multiple sites. Any data passed between sites must at least be encrypted. The FPGA can decrypt, perform AI processing, and encrypt all with very low latency. Crucially no decrypted data would leave the confines of the FPGA.
Figure 3 : Using an FPGA to perform inference with decryption and encryption logic in the cloud
Ultimately, Homomorphic encryption would be the desired approach for processing such sensitive data, for which FPGA’s are showing promise.
Optimizing for different neural network topologies
There are many different types of neural networks. Three of the most common are convolutional neural networks (CNNs), recurrent neural networks (RNNs) and more recently Transformer based networks such as Google’s BERT. CNNs are mostly used for image recognition applications and are in essence matrix processing problems. RNNs and BERT are frequently used for problems such as speech recognition and are less efficient than CNN models on SIMD processers like a GPU.
FPGA logic can be reconfigured to best fit a neural networks processing demands, rather than fitting the algorithm around the hardware, such as on a GPU. This particularly important for low batch numbers, where increasing the batch size is often a solution to handling networks with awkward dependencies on GPUs.
Balancing compute and memory bandwidth
Resnet is a commonly cited neural network that consists of many convolutional layers. However, most of these layers use stencils of only a single cell (1×1), a common requirement. The final layers of Resnet require a very high ratio of weights to data calculations, as the small stencil size reduces the amount of data reuse possible. This is exacerbated if trying to achieve the lowest possible latency, i.e. a batch size of 1. Balancing compute to memory bandwidth is critical to achieving best performance. Fortunately, FPGAs support a wide range of external memories, including DDR, HBM, GDDR and internal SRAM memory, allowing the perfect combination of bandwidth to compute to be selected for a given workload if the correct device is chosen.
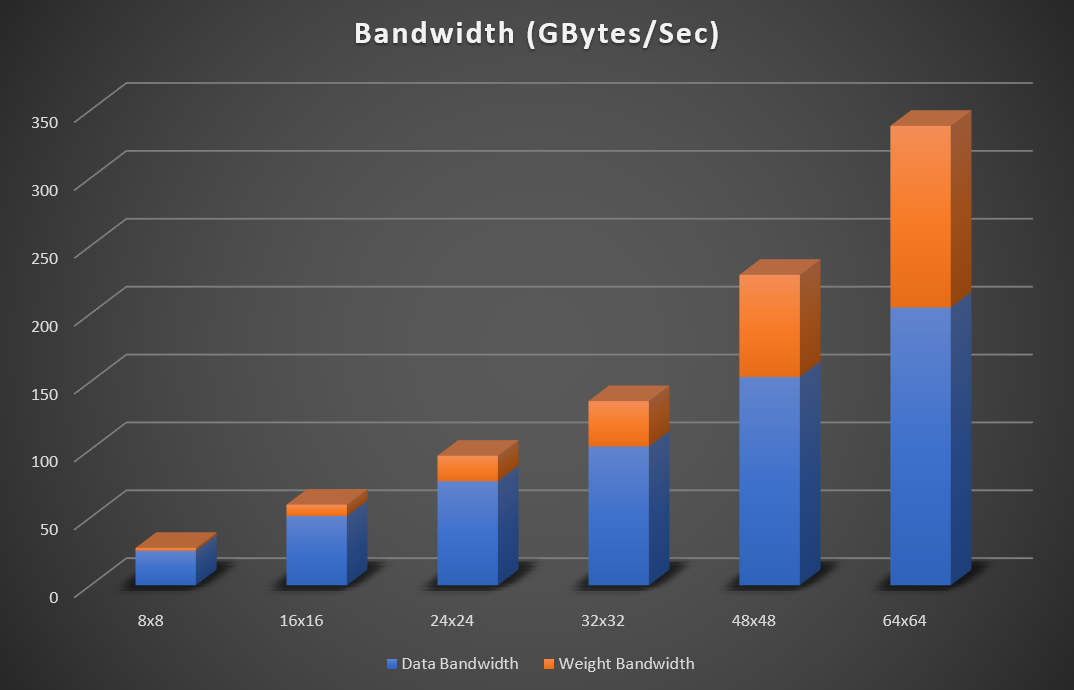
Figure 4: Resnet (224×224) peak bandwidth requirement (32bit Floating point data) for increasing matrices sizes
Figure 4 illustrates the increasing peak bandwidth requirements for matrix sizes of 8×8, 16×16, 24×24, 32×32, 48×48 and 64×64 for Resnet 50. The bandwidth assumes weight, input and output data are read and written to external memory. On-chip SRAM memory is used to store temporary accumulations. If the network fits within FPGA memory, then there is no need to consistently read and write feature data to and from memory. In this case the external data bandwidth becomes negligible. For int8 implementations the required bandwidth figures can be divided by 4.
FPGA Vendors
Bittware is vendor agnostic and supports Intel, Xilinx and Achronix FPGA technologies. All FPGA vendors perform well at low latency and low batch number implementations, however each device has subtle differences in the application of the configurable logic.
Achronix Speedster 7t
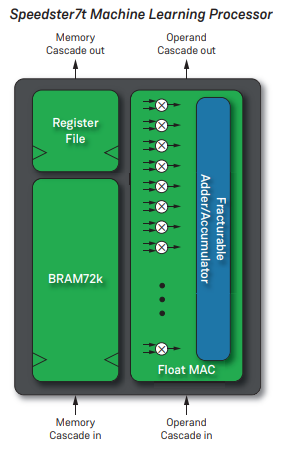
The latest FPGA from Achronix also features IP designed to accelerate neural network processing. Each machine learning processor (MLP) one the device processes 32 multiply accumulators (MACs), that support 4 to 24 bit calculations. Non-standard floating-point formats are supported, such as Bfloat16. A key distinction between the Achronix MPL and the Intel tensor component, is a tightly coupled SRAM memory with the intention of ensuring higher clock speeds versus decoupled SRAM.
The Bittware S7t-VG6 features the Speedster7t with 2,560 MLPS giving a total theoretical peak performance of 61 TOps (int8 or bfloat16).
Figure 5 : Achronix MLP 3
Figure 6 : BittWare S7t-VG6
Intel Stratix 10 NX and Agilex
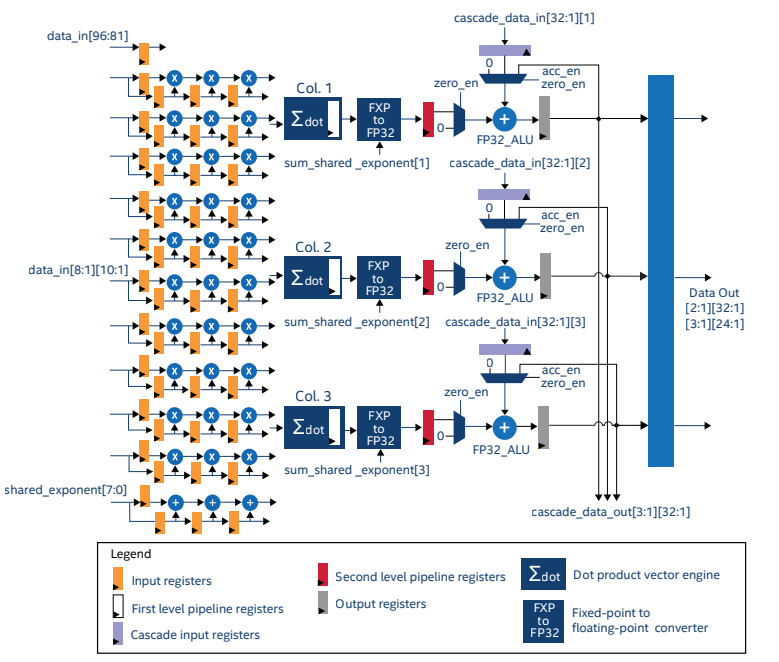
The Intel Stratix 10 NX was the first FPGA from Intel to feature dedicated tensor arithmetic blocks. The tensor IP is optimised to perform a tensor operation on a 10×3 block of data (Figure 5). The IP can be configured to work, fully utilised, with int4, int8, Block FP12 and Block FP16 data types.
Figure 7: Stratix 10 Tensor IP1
The theoretical peak throughput of the Startix10 NX device is shown in Table 1.
The Stratix 10 NX also has HBM2 memory providing as much as 512 GB/s aggregate bandwidth, ensuring there is enough bandwidth to feed all the available processing.
Precision
Performance
INT4
286 TOPS
INT8
143 TOPS
Block FP12
286 TFLOPS
Block FP16
143 TFLOPS
Table 1: Stratix 10 Theoretical Peak Throughput
The Stratix 10 NX is at the heart of the Bittware 520NX accelerator card. The card has up to 600 Gbps board-to-board bandwidth for connecting multiple cards together or for communication to sensor data.
The Intel Agilex Series does not have tensor DSP components; however, its DSPs have been improved from Stratix 10 to support more data types, increasing lower precision arithmetic throughput. The Intel Agilex M-Series has a theoretical Resnet-50 performance of 88 INT TOPS.2
Figure 8 : BittWare 520NX
AMD Xilinx Versal
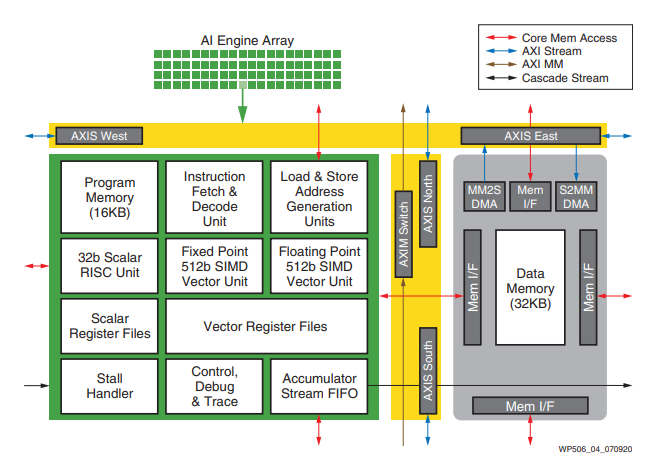
The Xilinx Versal device has separate AI engines not integrated into the FPGA programmable logic. The versal AI engine is closely coupled to the FPGA but runs independently to the rest of the FPGA. Data is passed between the AI engines and FPGA logic using a Network On Chip (NOC).
Figure 9 : Versal AI engine
BittWare currently has an ACAP early access program with concepts including a double-width PCIe Gen5 accelerator card featuring AMD Xilinx®’s 7nm Versal Premium ACAP devices. Learn more on our Versal information page.
Programming FPGAs for Neural Networks
AI engineers use many different high-level tools to describe neural networks such as, PyTorch, TensorFlow, Caffe, etc. Fortunately, there are API’s available that compile AI codes to FPGA’s allowing engineers to continue to use existing tool flows.
Bittware has partner companies with this capability:
EdgeCortix
EdgeCortix Dynamic Neural Accelerator (DNA), is a flexible IP core for deep learning inference with high compute capability, ultra-low latency and scalable inference engine on BittWare cards featuring Agilex FPGAs.
Megh Computing
VAS Suite from Megh Computing is an intelligent video analytics solution for security and system integrators who need actionable insights with enterprise class performance, while managing TCO considerations.
Conclusion
Modern FPGAs are very capable AI processors that excel at low latency, small batch size inference. When combined with other processing requirements, they provide a powerful platform on which to create uniquely capable AI systems. Depending upon the demands of the system one FPGA vendor may prove more suitable than the other. BittWare are ready to assist customers on selecting the appropriate FPGA system based on power, processing and IO requirements.