Building a Butterfly Crossbar Switch to Solve Resource Sharing in FPGAs
The Shared Resource Problem
FPGA cards usually have many high-performance memory and I/O interfaces.
No built-in cache
No hardcode arbitration logic
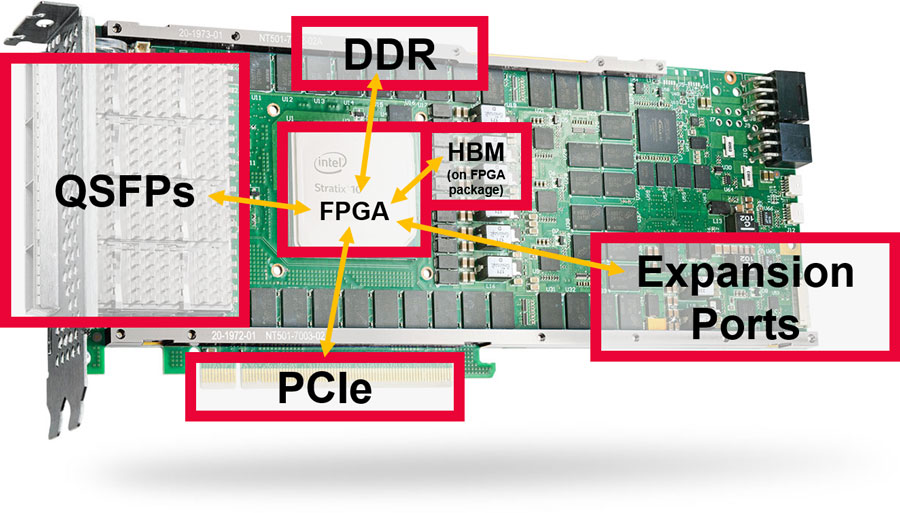
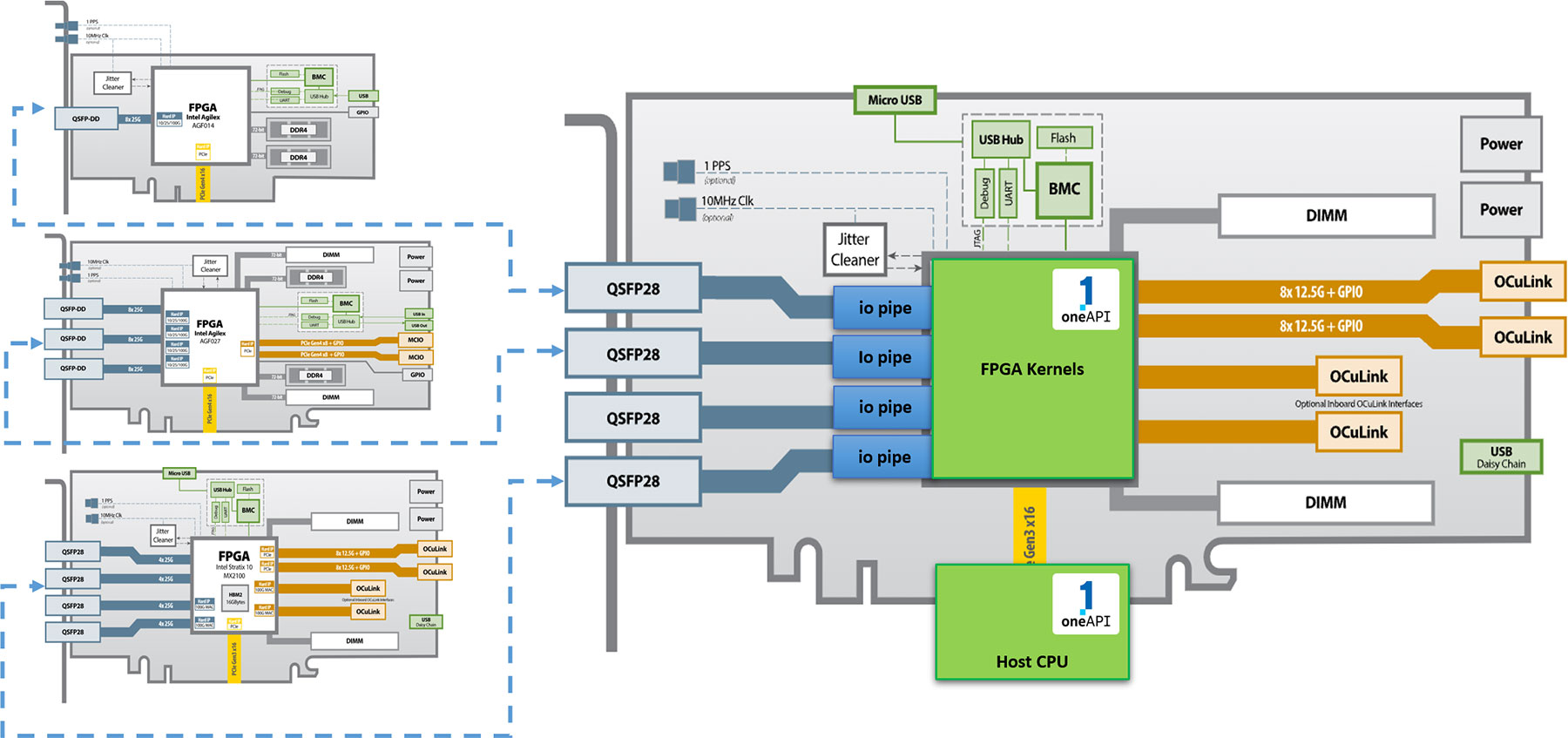
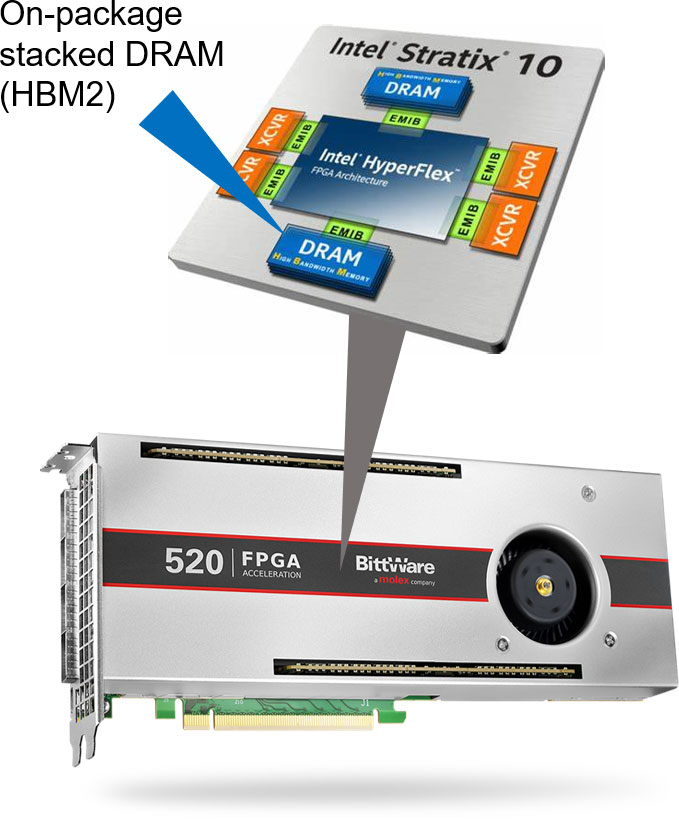
Large FPGAs, such as the Stratx 10 and Agilex series from Intel, feature a wide array of I/O interfaces. BittWare provides cards that make use of these by providing features like QSFPs, PCIe, on-card DDR4 and GDDR6 memory and expansion ports. We also have cards featuring FPGAs with on-package HBM2.
Accessing all these interfaces is not simple, particularly if resources are required to be shared between multiple kernels. FPGAs have no built-in cache or arbitration logic beyond basic memory controllers—arbitration is the responsibility of the user.
Our Solution to the Shared Resource Problem:
Create a CROSSBAR SWITCH in FPGA logic
We built a Butterfly Crossbar Switch using Intel® oneAPI.
By using oneAPI, a high-level tool, instead of low-level RTL, we get an easy-to-configure solution that’s easily optimized for different uses
We targeted the 520N-MX card; the code can be used on other BittWare cards using oneAPI
One solution to sharing connectivity between multiple kernels and multiple interfaces is a crossbar switch. This can be creating using FPGA native programming, of course. However, if we use a high-level programming language like oneAPI we can easily optimize it to be as efficient as possible based on the number of connections required and the width of the interfaces.
The BittWare Butterfly Crossbar Switch was developed on our 520N-MX card, which features HBM2 memory and multiple network ports.
Why use a crossbar?
A crossbar is a collection of switches arranged in a matrix. It reduces the connections required between a group of inputs/outputs.
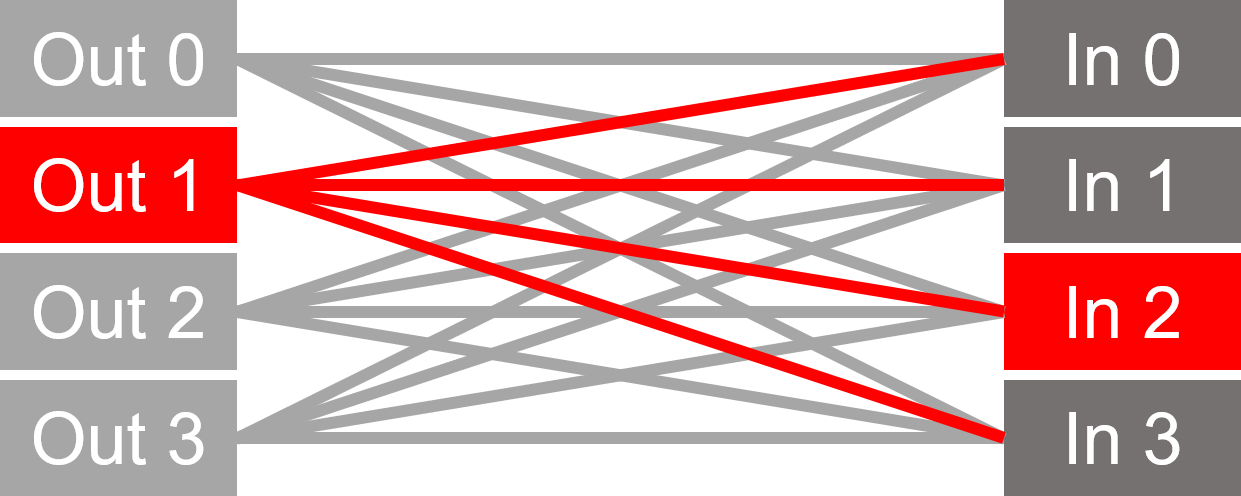
Without Switch:
Multiplexer: all ins/outs interconnected.
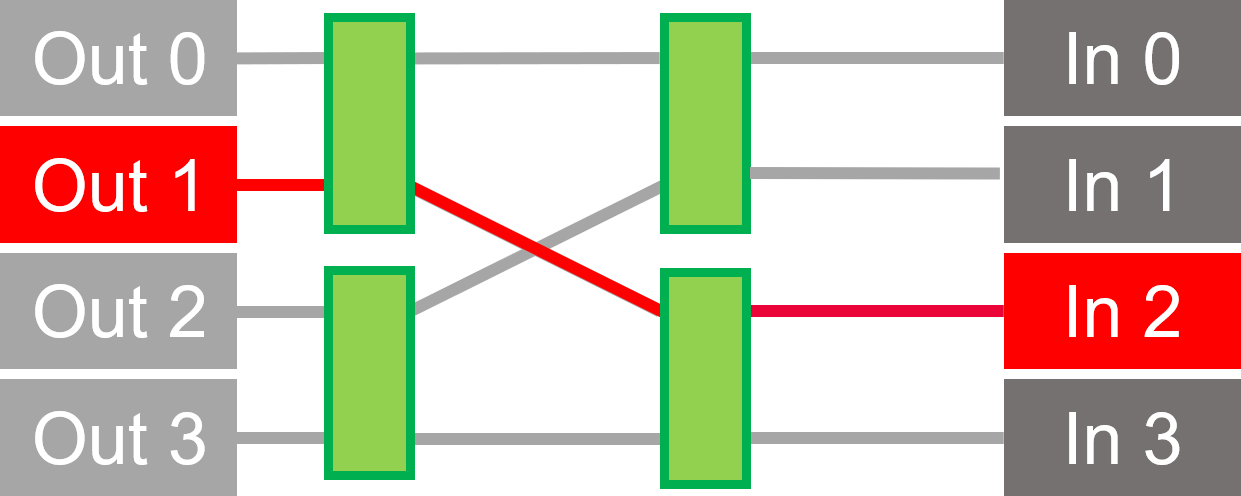
With Crossbar Switch
Switches route signals using fewer connections.
In an FPGA, fewer connections = easier routing, higher clock frequency and better performance
There are Multiple Types of Crossbar Switches
Two examples are full crossbar and butterfly:
Full Crossbar:
The matrix is equal to the number of inputs multiplied by the number of outputs.
Butterfly Crossbar
Matrix size is N x log2(N) / 2, where N is number of inputs.
We chose Butterfly because it uses less FPGA resources. However, it can have reduced throughput in some cases.
More details:
BittWare’s Butterfly Crossbar Switch
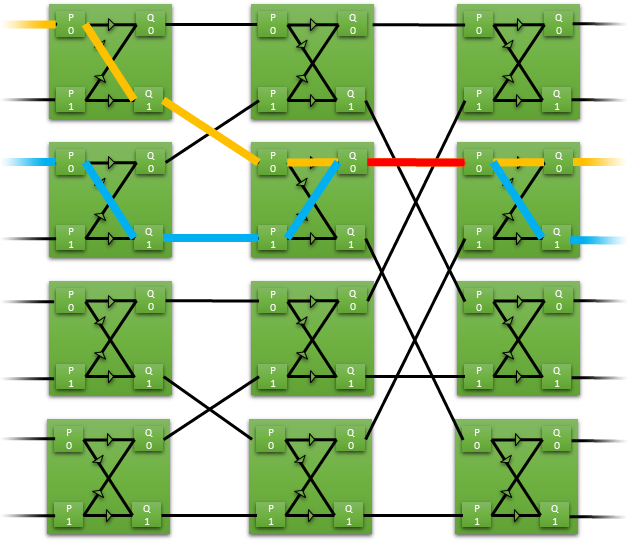
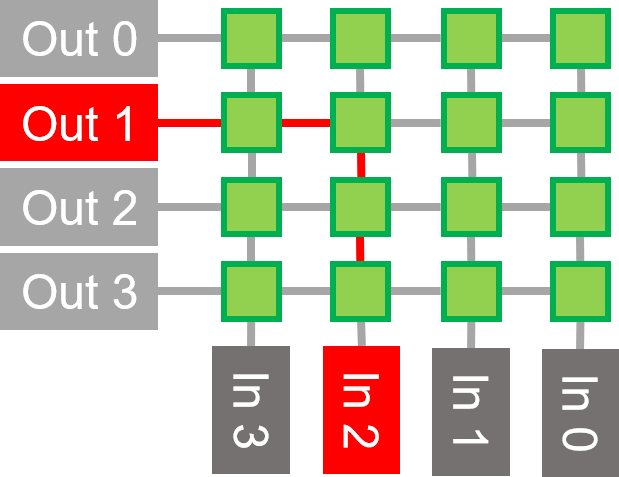
Example: 8 input to 8 output crossbar
Example clash on port routes 0-2 and 2-3
Arbitration uses a simple ping pong scheme, although more sophisticated schemes could easily be implemented if required
Click the image to animate the example clash on port routes 0-2 and 2-3.
In this example of a butterfly crossbar, 8 inputs are routed to 8 outputs using just 12 switches. Each switch has two inputs and two outputs. The data is routed straight through or switched to the opposite route.
If only one path is switched, then there can be a clash at an output and the switch must arbitrate who has access to the path. Arbitration uses a simple ping pong scheme by default, although more sophisticated schemes could easily be implemented if required.
Using High-Level Design Tools (oneAPI DPC++)
By utilizing high level languages (DPC++), the crossbar switch can be tailored for a particular application requirement—for example:
The number of parallel kernels (input ports)
The width of the data paths
Multiple different crossbars in the same design
This allows designs to be optimized for resource. Power is kept to a minimum by removing the need for an always active built-in generic switch.
Using oneAPI Tools (DPC++ and SYCL)
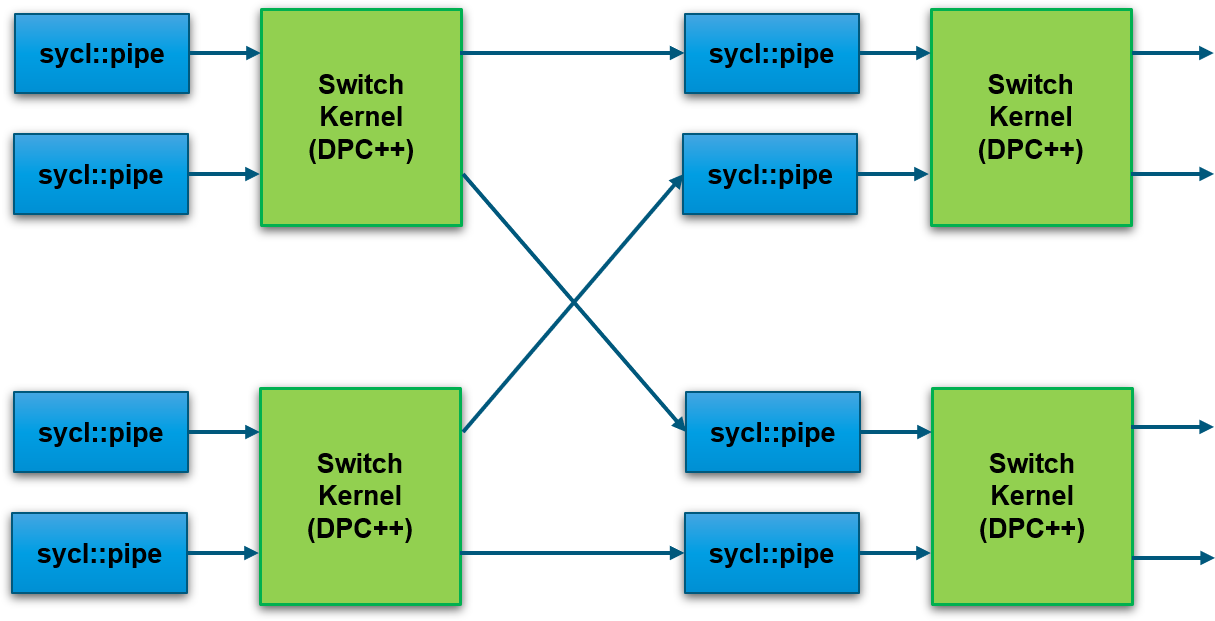
Each crossbar switch is a unique group of switch kernels
Switches are connected via SYCL pipes to create a crossbar with the required number of ports
The width of each switch is implied from the datatypes required
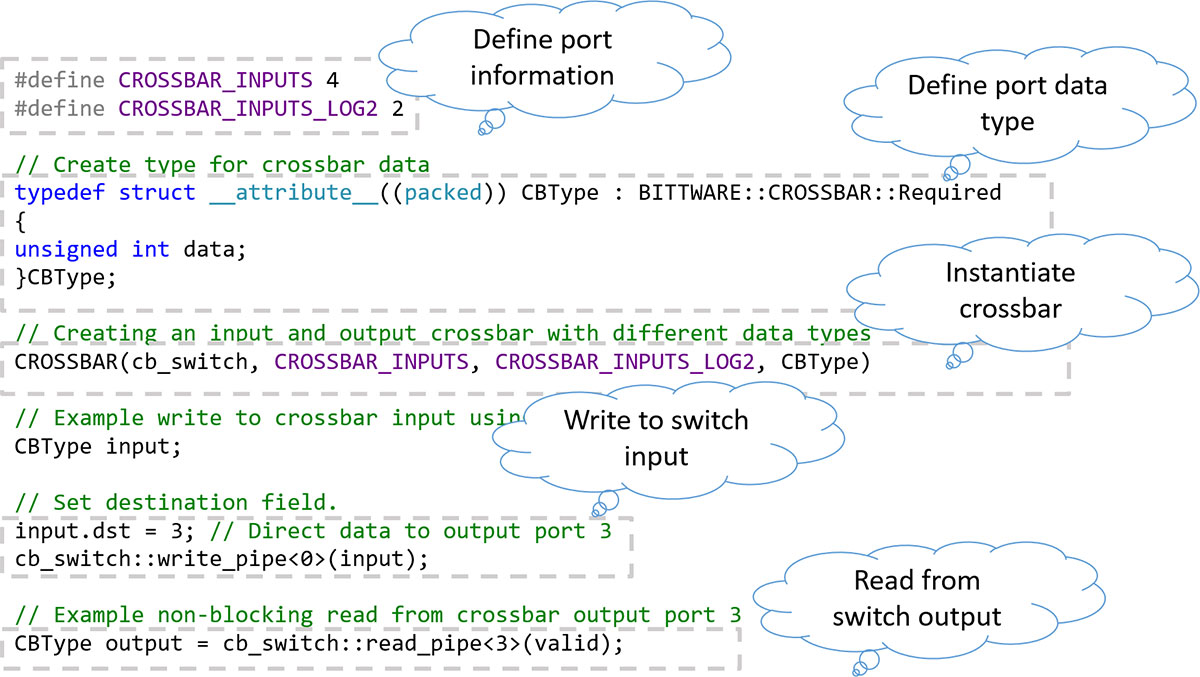
Number of ports must be power of 2
Unused ports get optimized away during synthesis
Data types must inherit switch metadata structure containing destination information
Ports are accessed using SYCL pipe methods, blocking or non-blocking as required
Using Crossbar in DPC++
Three Example Use Cases for BittWare's Crossbar Switch
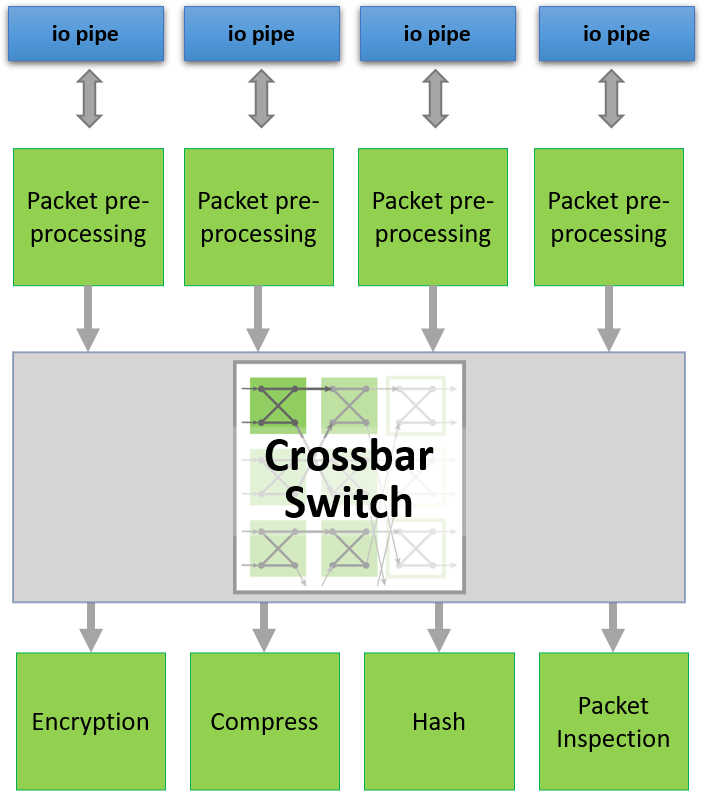
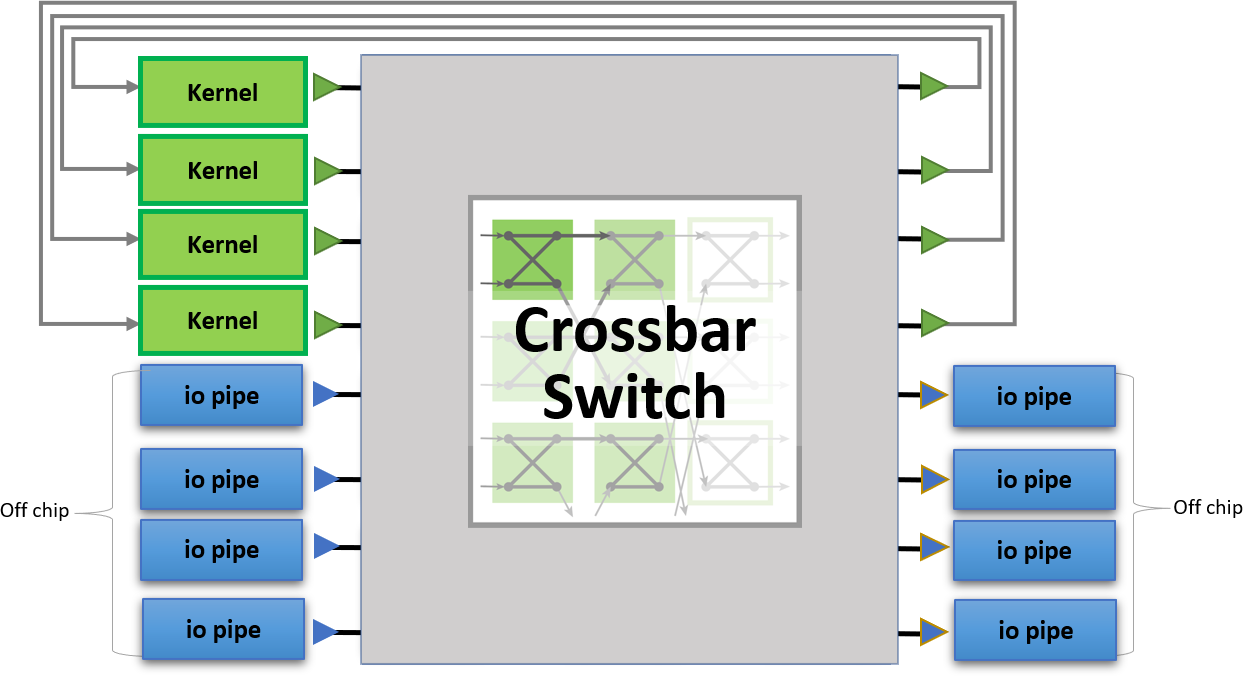
oneAPI abstracts the interface between the host and FPGA. Interfaces with external I/O (such as QSFPs in the diagram) are also abstracted using oneAPI I/O pipes. This allows designs to be scaled out to multiple BittWare FPGA cards which support oneAPI.
A crossbar switch can be used to direct packets to or from network ports. Here, a small modification to the DCP++ code changes arbitration to be on network packet boundaries.
Use Case 2:
Kernel Sharing of HBM2
(With an Ethereum blockchain mining example)
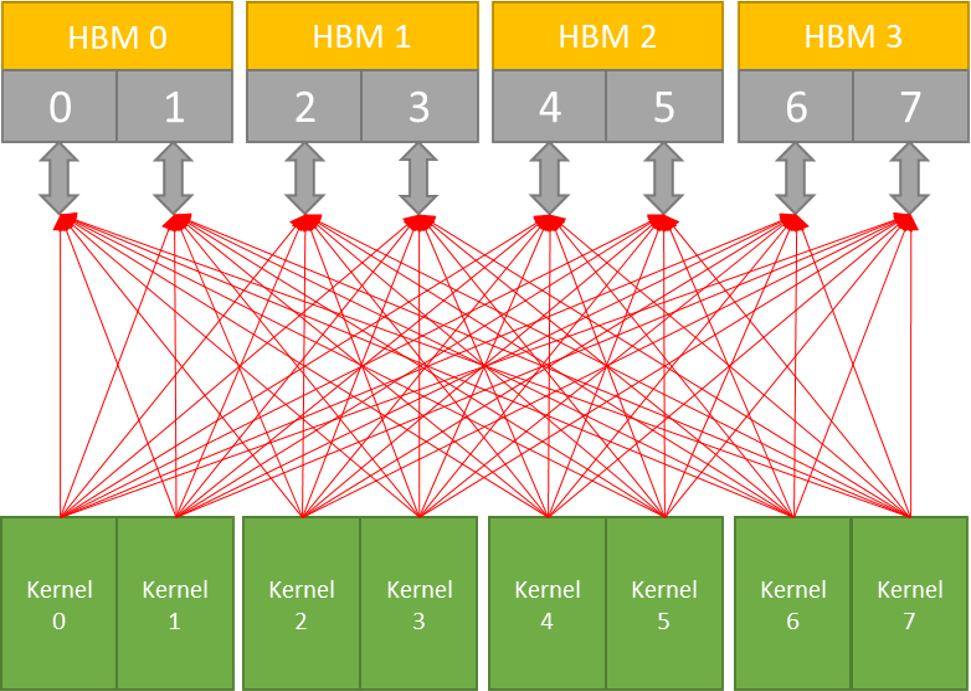
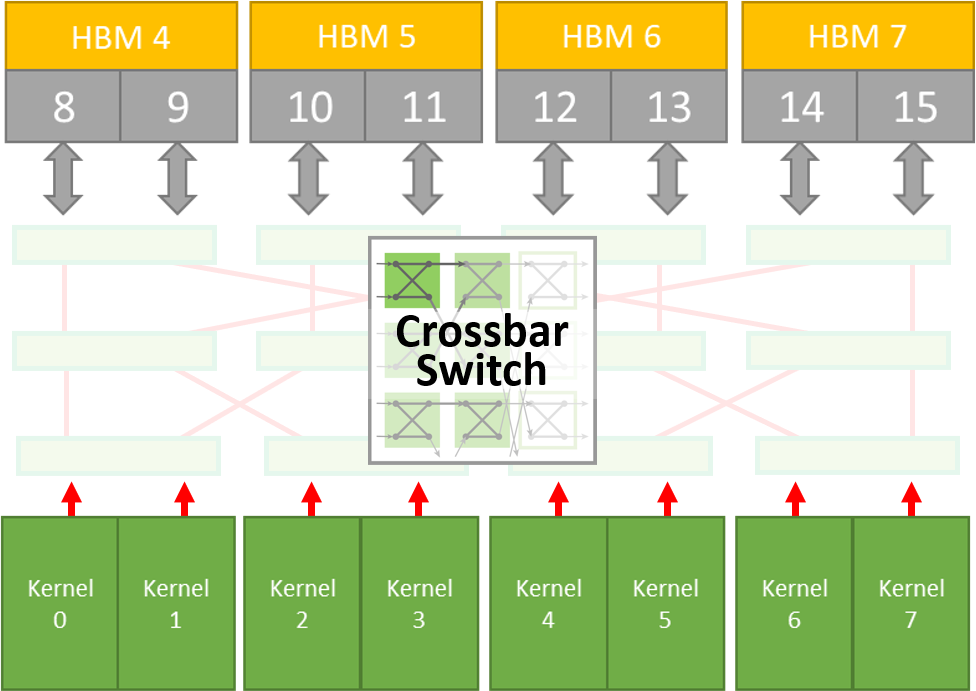
With the Crossbar Switch, we can optimize kernels that need to share access to HBM2 memory channels.
One use case for this is mining Ethereum.
Mining Ethereum with competitive performance requires multiple parallel kernels each with access to a large (4.5 GB currently) memory space called the DAG.
The bottleneck for Ethereum mining is memory bandwidth, so on-package HBM2 is an excellent fit for both the size and bandwidth requirements.
The Intel Stratix 10 MX FPGA has 32 independent HBM2 memory ports.
Each port has peak throughput of 12.8 GBytes/Sec.
Each port has access to only 512 MBytes of memory
16 GBytes in total
However, the FPGA has no built-in switch, plus high-level tools do not automatically concatenate or arbitrate multiple ports.
Our Crossbar Switch can address these problems to improve performance.
Example of sharing 8 HBM memories
Without Crossbar: Large number of routes using multiplexing approach (no arbitration).
Our Butterfly Crossbar Switch reduces routing and adds arbitration for higher performance.
Use Case 3:
Distributed Graph Processing
Large graphs require significant memory resources spread over multiple FPGAs.
The crossbar switch is an elegant solution to communicate between kernels local and off device.
Graph processing has many applications
Biology, Social Media, Finance and many more
Conclusion
FPGAs have unique capabilities which can be complex and challenging to use efficiently.
BittWare’s Butterfly Crossbar Switch IP provides a simple way to provide shared access between multiple memories or IO interfaces, simplifying some of these complexities.
High level languages such as DPC++, allow such IP to be easily customized for different use cases.
Request the Source Code
You can request the BittWare Butterfly Crossbar Switch by filling out this form. Our sales team will connect with you for the next steps to accept the license agreement and set up a log in to download the code.