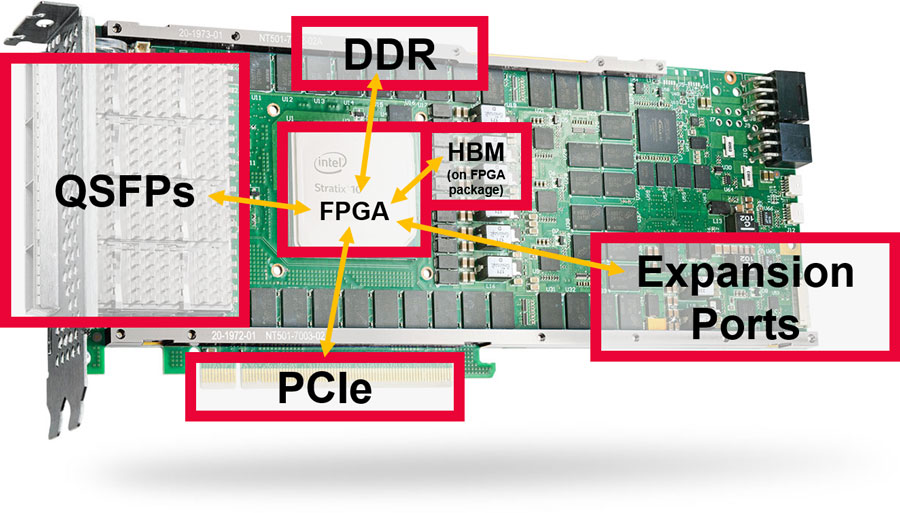
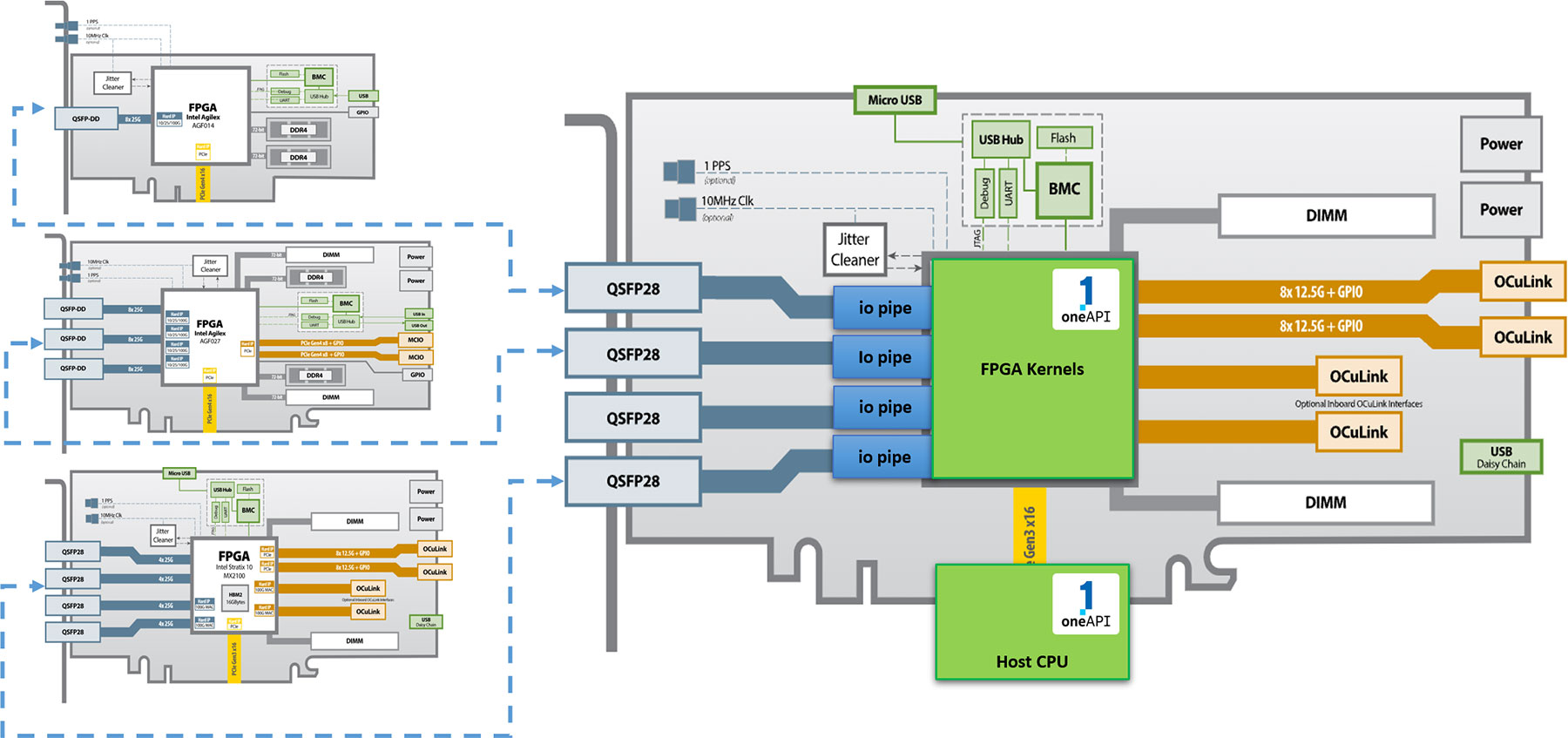
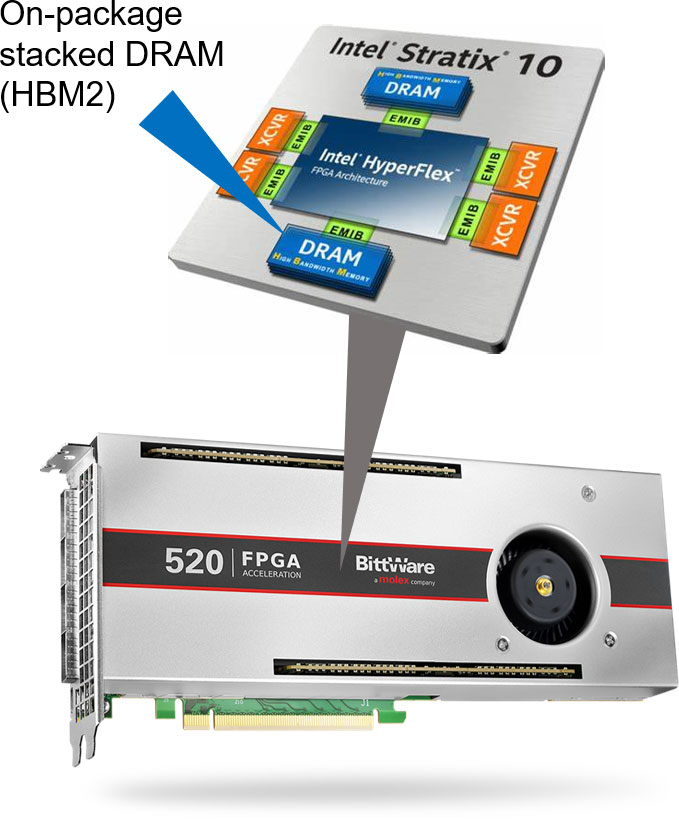
大型FPGA,如英特尔的Stratx 10和Agilex系列,具有大量的I/O接口。BittWare提供的卡通过提供QSFPs、PCIe、板载DDR4和GDDR6内存和扩展端口等功能来利用这些接口。我们也有以FPGA为特色的卡,并配有HBM2。
访问所有这些接口并不简单,特别是在需要在多个内核之间共享资源的时候。除了基本的存储器控制器,FPGA没有内置的缓存或仲裁逻辑--仲裁是用户的责任。
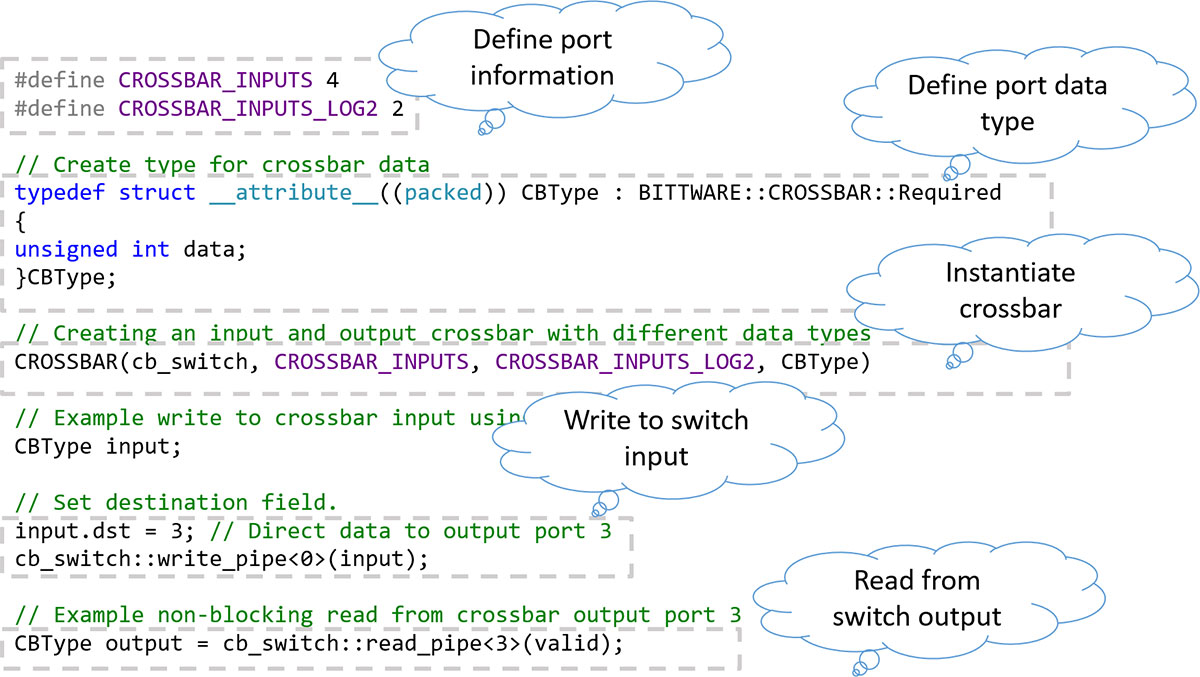
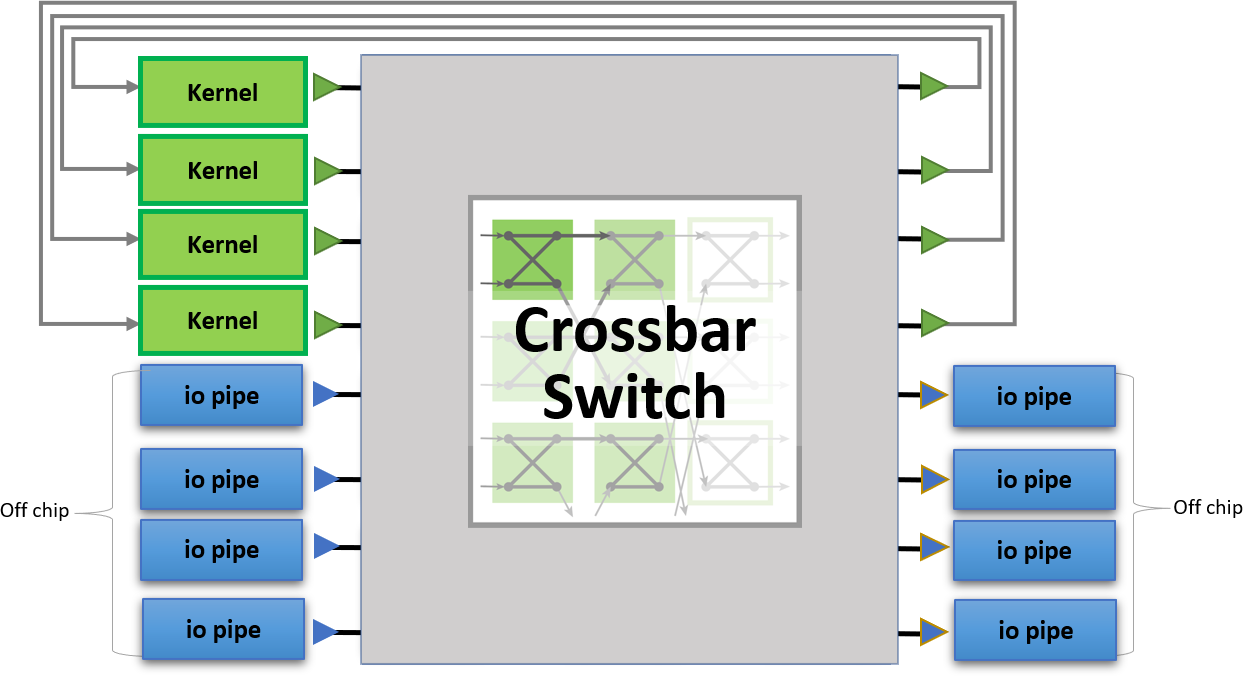
在多个内核和多个接口之间共享连接的一个解决方案是一个交叉条开关。当然,这可以使用FPGA本地编程来创建。然而,如果我们使用像oneAPI这样的高级编程语言,我们可以很容易地根据所需的连接数和接口的宽度对其进行优化,使其尽可能地高效。
BittWare Butterfly Crossbar Switch是在我们的520N-MX卡上开发的,它具有HBM2内存和多个网络端口。
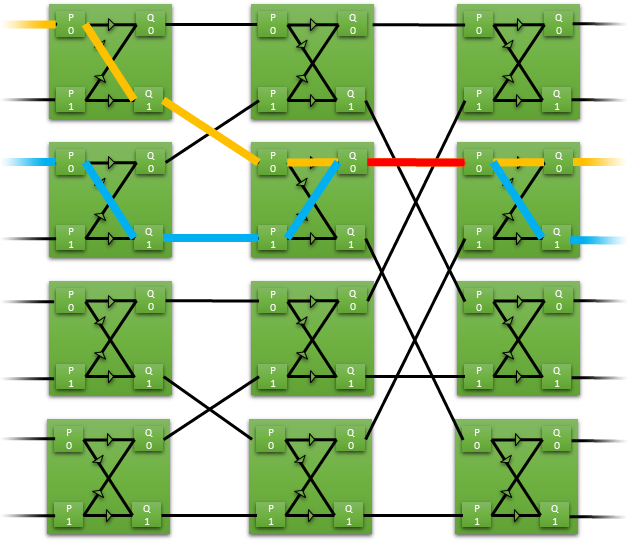
横梁是一组排列成矩阵的开关。它减少了一组输入/输出之间的连接要求。
矩阵等于输入的数量乘以输出的数量。
矩阵大小为N x log2(N) / 2,其中N为输入数。
我们选择Butterfly是因为它使用较少的FPGA资源。然而,在某些情况下,它的吞吐量会降低。
更多细节:
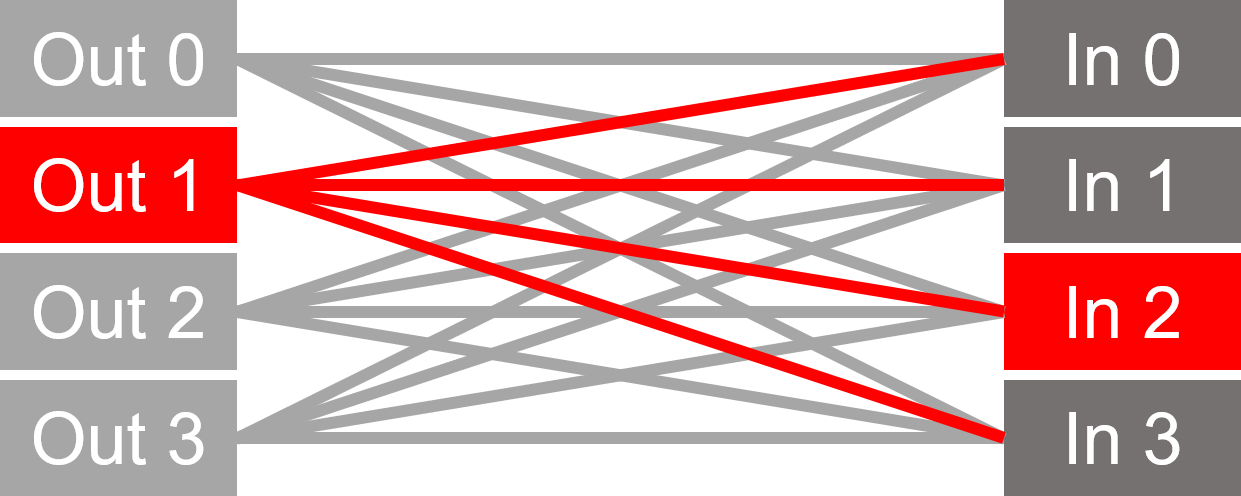
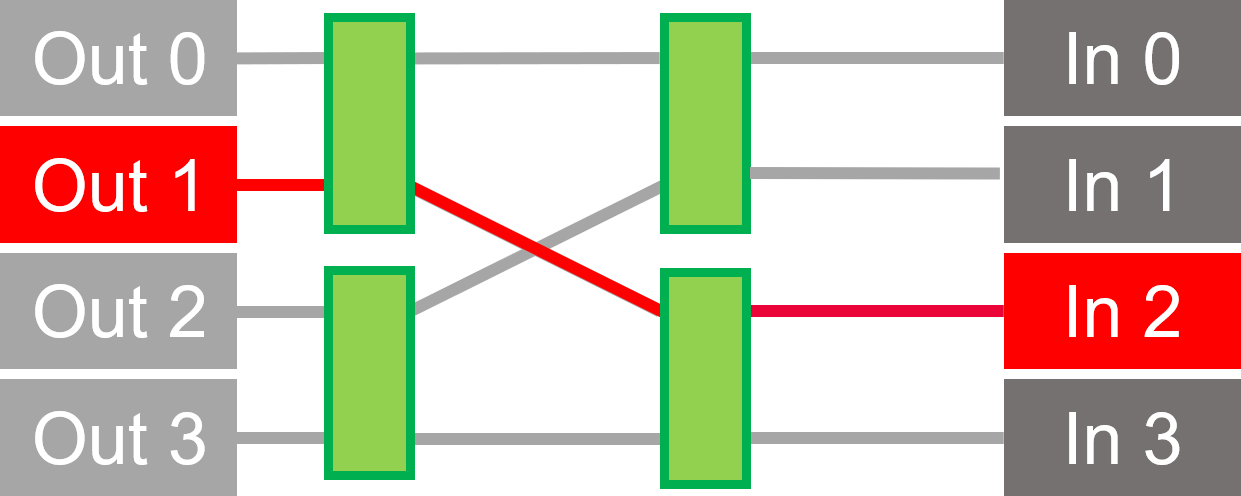
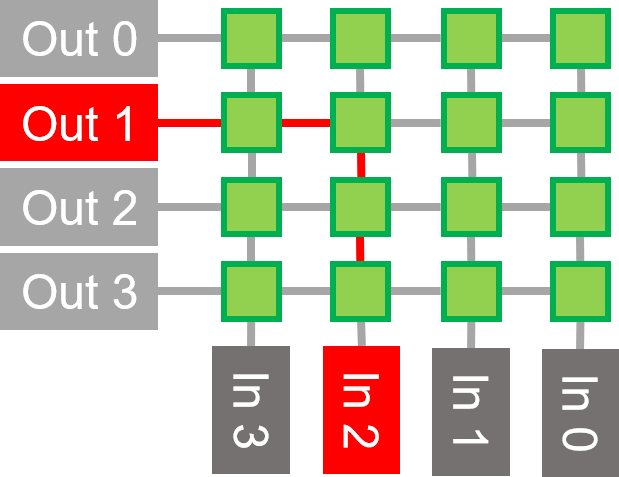
点击图片,对端口路由0-2和2-3的例子冲突进行动画处理。
在这个蝶形横梁的例子中,8个输入被路由到8个输出,只用了12个开关。每个开关有两个输入和两个输出。数据被直接路由或被切换到相反的路由。
如果只有一条路径被切换,那么在输出端可能会出现冲突,交换机必须对谁有权限访问该路径进行仲裁。仲裁默认使用一个简单的乒乓方案,尽管如果需要,可以很容易地实现更复杂的方案。
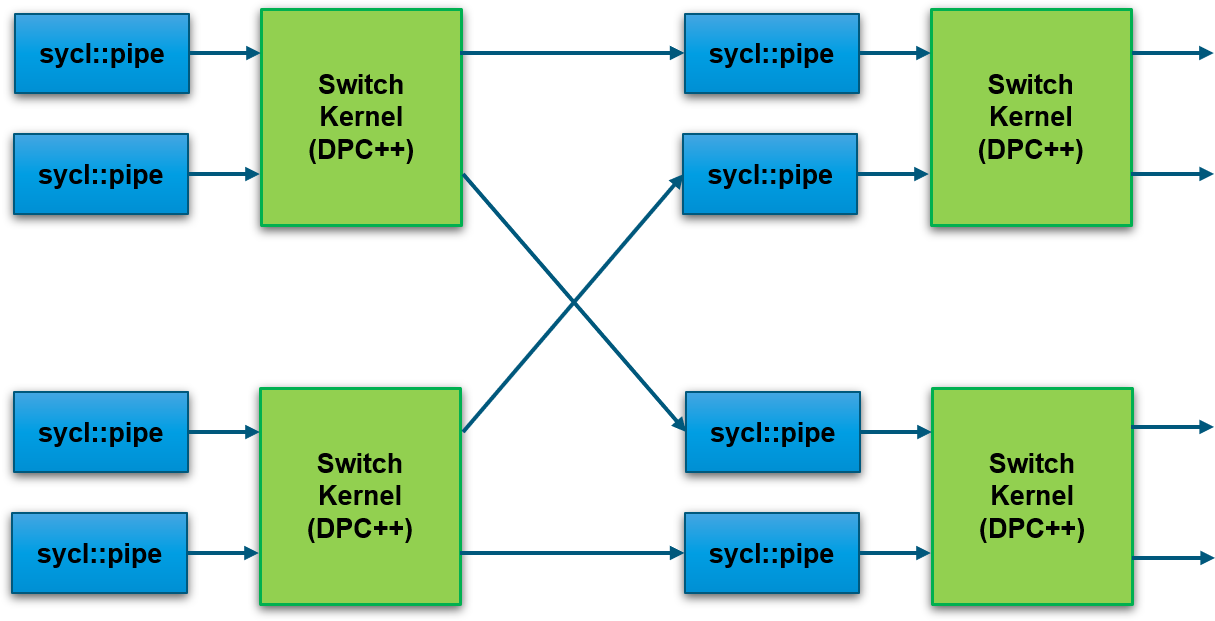
通过利用高级语言(DPC++),可以为特定的应用要求定制横梁开关--例如:
这使得设计可以针对资源进行优化。通过消除对始终处于活动状态的内置通用开关的需求,将功率保持在最低水平。
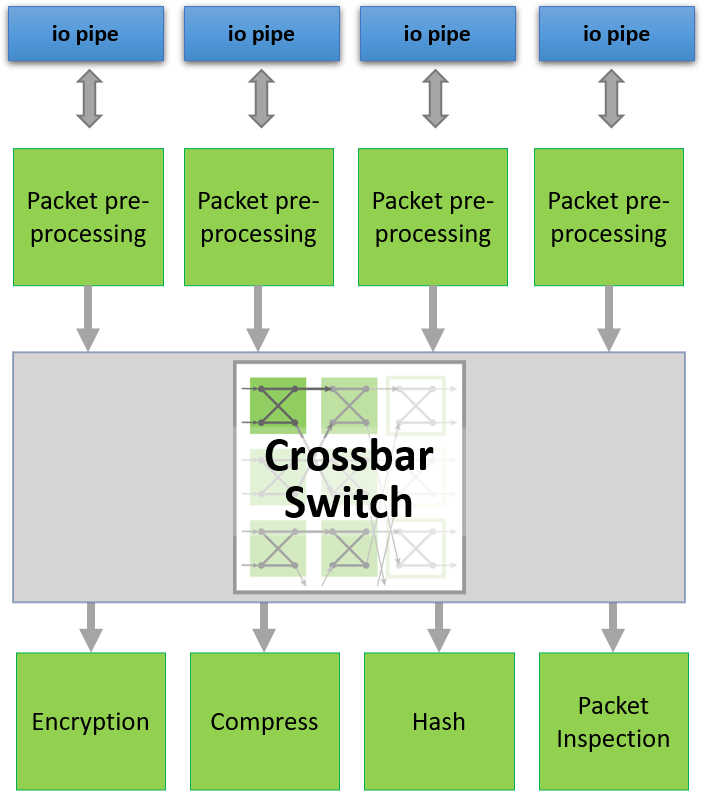
oneAPI抽象化了主机和FPGA之间的接口。带有外部I/O的接口(如图中的QSFPs)也使用oneAPI I/O管道进行抽象化。这使得设计可以扩展到多个支持oneAPI的BittWare FPGA卡。
交叉条开关可以用来引导数据包进入或离开网络端口。在这里,对DCP++代码的一个小修改将仲裁改为在网络包的边界上。
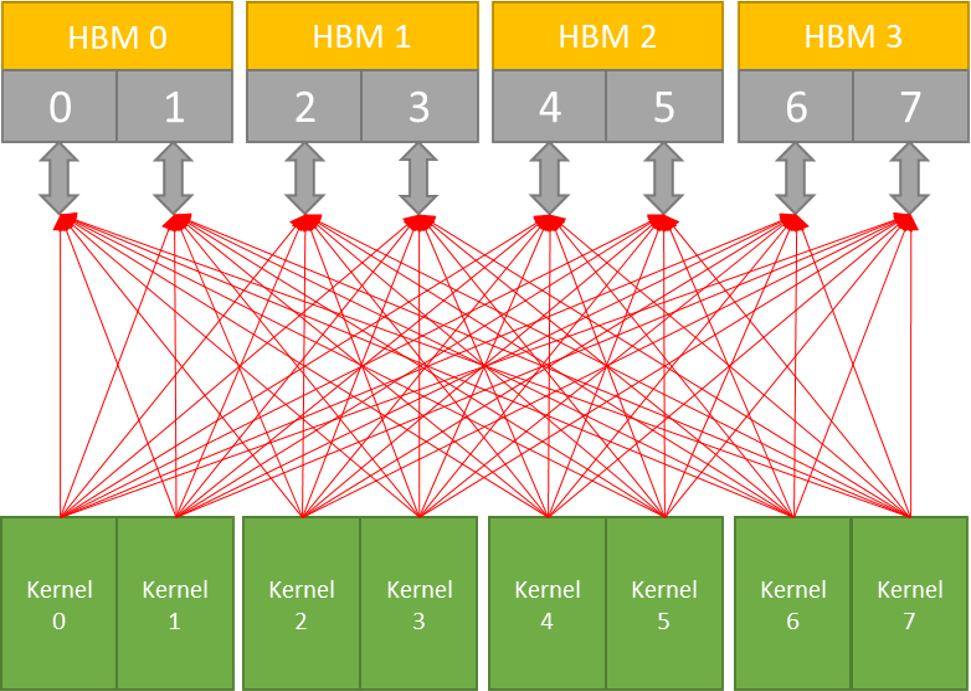
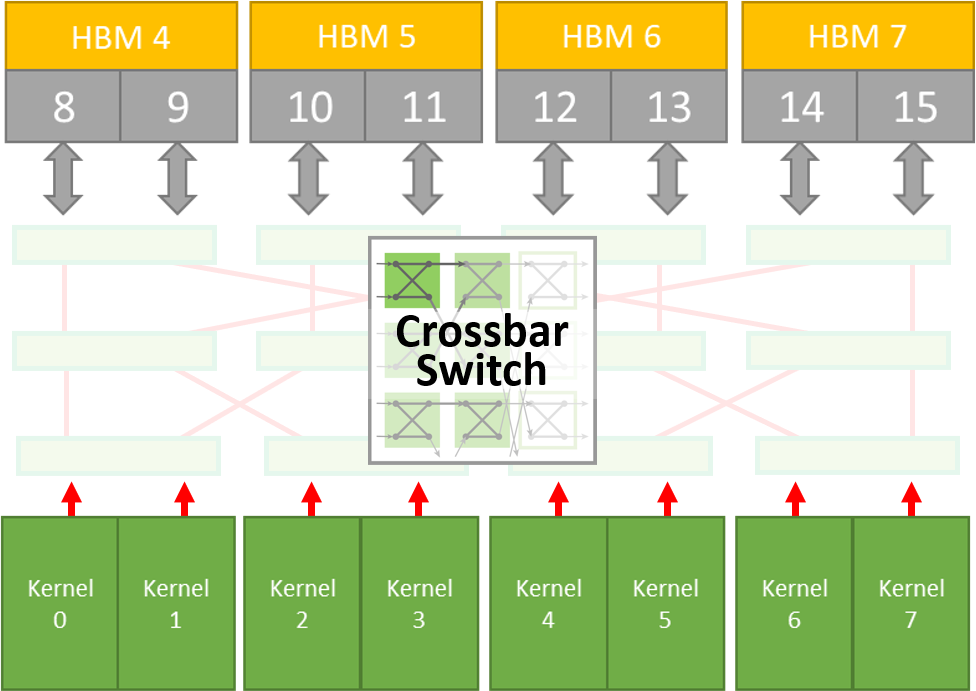
通过Crossbar Switch,我们可以优化那些需要共享访问HBM2内存通道的内核。
每个端口的峰值吞吐量为12.8GBytes/秒。
每个端口只能访问512MBytes的内存
总共16GBytes
我们的横梁式交换机可以解决这些问题以提高性能。
没有横梁:大量路由使用多路复用方法(无仲裁)。
我们的Butterfly Crossbar交换机减少了路由并增加了仲裁,以获得更高的性能。
你可以通过填写这个表格来申请BittWare Butterfly Crossbar Switch。我们的销售团队将与你联系,进行下一步的工作,接受许可协议,并设置登录,下载代码。
"*"表示必填项目