

FPGA优化
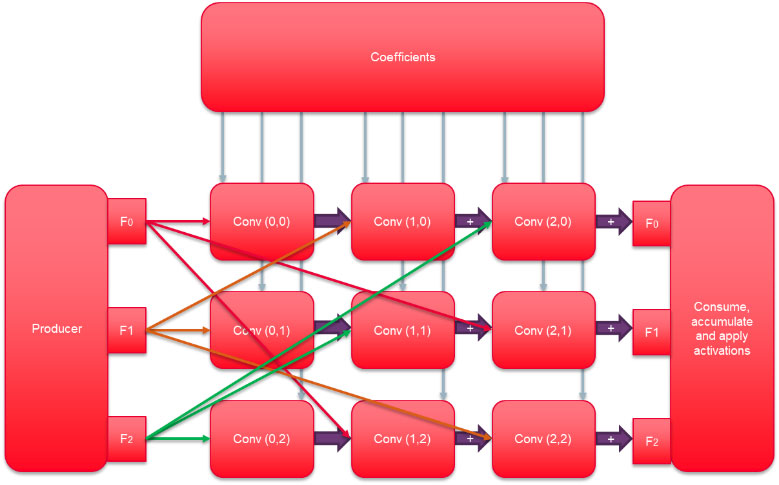
首先,权重的二进制化将外部存储器的带宽和存储要求降低了32倍。FPGA结构可以利用这种二进制化,因为每个内部存储器块可以被配置为具有1到32位的端口宽度。因此,用于存储权重的FPGA内部资源大大减少,为任务的并行化提供了更多空间。
网络的二进制化也允许CNN卷积被表示为输入激活的一系列加减法。如果权重是二进制的0,输入就会从结果中减去;如果权重是二进制的1,就会加到结果中。FPGA中的每个逻辑元件都有额外的携带链逻辑,可以有效地执行几乎任何比特长度的整数加法。有效利用这些元件可以使一个FPGA执行数以万计的并行加法。要做到这一点,浮点输入激活必须被转换为固定精度。利用FPGA结构的灵活性,我们可以调整固定加法所使用的比特数,以满足CNN的要求。对各种CNN中激活的动态范围的分析表明,只需要少量的比特,通常是8比特,就可以将精度保持在浮点等效设计的1%以内。位的数量可以增加,以获得更多的精度。
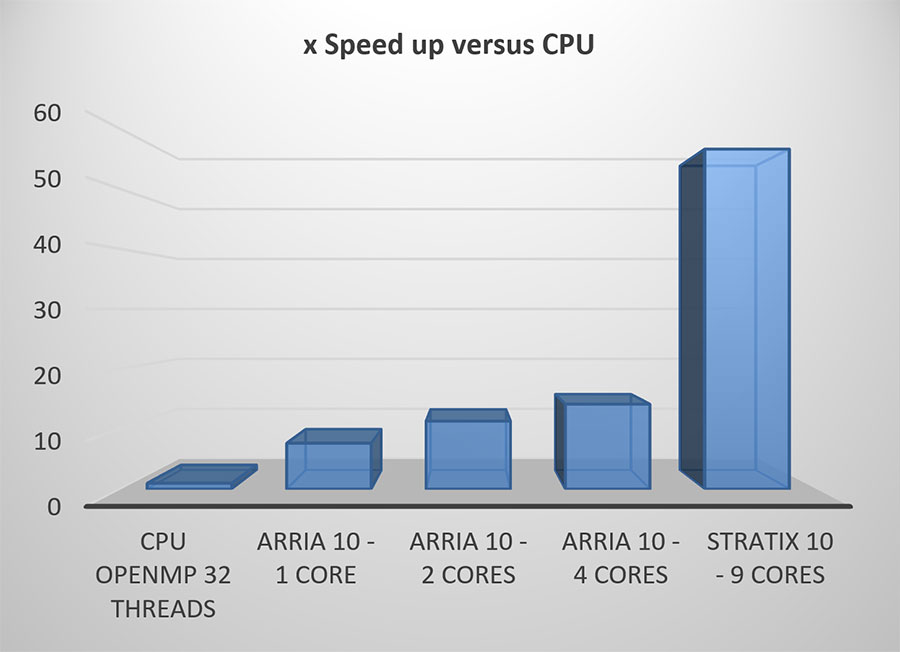
有许多不同的网络可以用于研究BNN的应用,从许多较简单的网络中挑选一个,如AlexNet,是很有诱惑力的。然而,为了真正了解FPGA对BWNN处理的有效性,最好使用最先进的网络,如YOLOv3。这是一个具有许多卷积层的大型卷积网络。
YOLOv3是一个深度网络,由于定点取整而引入的误差比AlexNet等较小的网络需要更多的位数来进行每次加法。FPGA技术的优势在于能够修改所需的精确比特数。在我们的设计中,我们用16位来表示层间传输的数据。
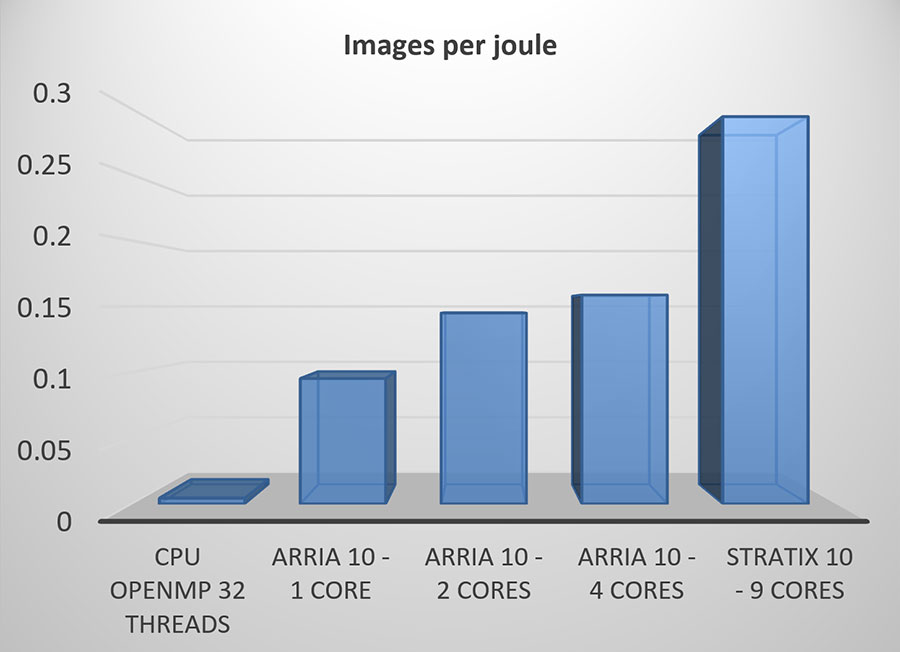
将卷积转换为定点,并通过二进制化消除对乘法的需求,大大减少了FPGA内所需的逻辑资源。因此,与单精度或半精度实现相比,在相同的FPGA中可以进行更多的处理,或者将FPGA逻辑释放出来用于其他处理。
有针对性的网络培训
YOLOv3网络是一个有106层的大型卷积网络,它不仅可以识别物体,还可以在这些物体周围放置边界框。它在需要跟踪物体的应用中特别有用。
如果经过适当的训练,二进制加权网络仅会略微降低YOLOv3网络的准确性。下表说明了重新训练的YOLOv3网络获得的结果。

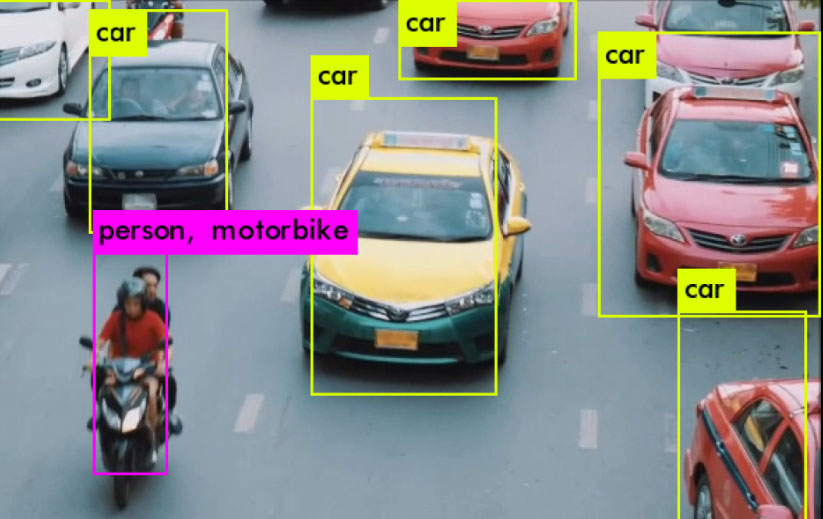
在这张图片上,自行车的平均置信度为76%,人的平均置信度为82%。与同一图像上的浮点法相比,它对自行车的平均准确度为92%(好16%),对人的平均准确度为88%(好6%)。
为了实现FPGA的最佳性能,将目标放在最适合FPGA的网络特征上是有帮助的。在这种情况下,不仅对网络进行了二进制权重训练,还选择了适当的激活类型,以有效地映射到FPGA逻辑。