BittWare 网络研讨会
使用下一代英特尔®Agilex™ FPGA的高性能计算
以巴塞罗那超级计算中心的一个应用实例为特色
现在可以点播(包括录制的问答)。
由于FPGA具有电源效率和对特定工作负载的适应性等优势,它正在进入更多的高性能计算应用。在本次网络研讨会上,我们将重点介绍最新的Intel®Agilex™ FPGA,包括下一代I系列和M系列器件。
本次网络研讨会的特别嘉宾是César González,他将解释巴塞罗那超级计算中心在一个加速项目和最近发表的论文中对FPGA的使用。他对确定小分子结构的研究利用了OpenCL高级编程。César将与英特尔的Maurizio Paolini一起介绍将该代码移植到带有英特尔Agilex FPGA的BittWare IA-840f卡上的结果,实现233倍的速度提升。

我们还将研究下一代Agilex FPGA,包括那些带有PCIe Gen5、CXL和HBM2e的FPGA以及支持这些器件的BittWare卡。
如果您正在从事HPC工作,或者对最新的FPGA如何提供新的加速性能感兴趣,请务必参加我们的网络研讨会!
立即点播观看,包括与我们的小组成员一起录制的问答!

发言人

Christian Stenzel |英特尔欧洲、中东和非洲地区技术销售专家

Craig Petrie | BittWare营销副总裁

Maurizio Paolini | 英特尔欧洲、中东和非洲地区云和企业加速部门现场应用工程师

César González | 巴塞罗那超级计算中心,加泰罗尼亚高级化学研究所 - CSIC
视频转述
Marcus)
大家好,欢迎参加我们的网络研讨会,"利用下一代英特尔 Agilex FPGA 实现高性能计算"。我们将介绍巴塞罗那超级计算中心的一个应用实例。我是 BittWare 的主持人Marcus Weddle。
让我们先来认识一下主讲人和他们的演讲内容。
第一位是来自英特尔的Christian Stenzel。他在赛灵思(Xilinx)工作了16年,担任过从FAE到客户管理和业务开发等一系列职务,并于2015年加入Altera。在英特尔被收购后,他转任云计算和企业技术销售专家,负责在欧洲、中东和非洲地区的云计算和企业市场推动英特尔FPGA加速战略。Christian将从为什么要将FPGA用于HPC?他还将介绍英特尔 Agilex 系列器件。
下一位是来自 BittWare 的Craig Petrie。他在FPGA领域拥有数十年的经验,从工程师做起,到领导产品管理和战略,如今他是销售和营销副总裁。Craig 将带领我们了解 BittWare 采用 Agilex FPGA 的产品、对 oneAPI 的支持、BittWare 的新合作伙伴计划,最后他还将介绍 CXL。
我们的高性能计算应用部分将由英特尔公司的 FAEMaurizio Paulini 和我们的特邀发言人Cesar Gonzalez 两位发言人主讲。Cesar 将介绍他在巴塞罗那超级计算中心 FPGA 应用方面的工作,而 Maurizio 将详细介绍 oneAPI,包括最近将 Cesar 的应用移植到带有 Agilex 的 BittWare 卡上的 oneAPI。
如果您正在收看我们的直播会议,请务必使用 "提问 "功能提问,我们将在会议结束时向小组成员提问。
好的,让我们从英特尔公司的克里斯蒂安-斯坦泽尔开始!
(基督教)
谢谢你,马库斯,感谢你邀请我参加今天的会议。首先,我需要向大家介绍一下英特尔的法律免责声明,大家可以在方便的时候阅读。
现在,让我们来谈谈高性能计算。高性能计算市场广阔,可用于更好地了解最大但也是最小的事物。从探索宇宙、清洁能源研究、天气和气候建模到量子物理、生物信息学、分子动力学、核研究等等,不一而足。
研究人员和科学家面临的问题越来越复杂,数据量越来越大,需要更多的计算能力来处理数据和运行模拟。换句话说,高性能计算客户正在进行一场性能竞赛。
在典型的高性能计算数据中心中,CPU 是运行计算的默认选项,而 GPU 则是解决并行问题的头号加速器。现在,有了 FPGA,HPC 系统就有了第三种补充,可以解决 CPU 和 GPU 不擅长的问题,而且总有一些工作负载在 FPGA 上运行得最好。
一直以来,FPGA 都很难编程,需要特殊的 RTL 编程技能。Maurizio 将在稍后的会议中讲述 oneAPI 如何使 FPGA 编程无需 RTL 技能。
让我们来看看 FPGA 的独特功能。
如前所述,性能在高性能计算中至关重要。与 CPU 或 GPU 不同的是,CPU 或 GPU 的架构几乎是固定的,这就决定了数据的处理方式,或者特定算法需要根据架构进行调整,而 FPGA 则提供了充分的灵活性。FPGA 的内部硬件架构可以构建(我们称之为 "配置"),以最适合相关算法,从而提供更低的延迟和更高的性能。例如,通过以太网线路传入的数据或直接从内存传入的数据可以在不调用主机 CPU 的情况下进行实时处理。这就是内联或 "线中碰撞 "加速用例。或者,一个完整的算法可以卸载到 FPGA,并将结果写回主机 CPU。这就是旁观加速用例。
通过更换 FPGA 和/或使用现场可编程功能,可以实现高级可扩展性,从而随时改变工作负载。FPGA 还可以并行运行多个工作负载,而不会相互干扰。FPGA 本身具有丰富的 IO,而加速卡则有许多不同的接口。使用 FPGA 集群可将工作负载分配到多个 FPGA 上,或利用高速芯片间通信实现阶段处理,从而提高性能。
我们的英特尔开放加速堆栈(Intel Open Acceleration Stack)可以轻松地在现有服务器上安装 FPGA 加速卡,并提供简单的系统配置方法来加速应用程序,从而提高了生产率。
在高性能计算数据中心,功耗至关重要。与 CPU 和 GPU 相比,FPGA 允许硬件以更少的时钟周期和更低的时钟频率执行功能,从而降低功耗。降低功耗意味着节约能源,这反过来又意味着可以减少运营支出(OpEx)和总拥有成本(TCO)。
其次是价格。标准集群的 FPGA 加速卡有多种选择。安装 FPGA 加速卡以提高集群的性能,比升级或更新集群以达到性能目标更具成本效益。
移至幻灯片 4 - Agilex:面向以数据为中心的世界的 FPGA
现在,让我们来看看基于 10 纳米工艺技术的 FPGA 系列 Agilex。首先,我们都受到了全球供应紧张的影响。Agilex 是在英特尔工厂生产的。其次,大家可能已经看到英特尔宣布投资建设晶圆厂,以减少依赖性。
回到 Agilex。Agilex 有不同的子系列,具有不同的功能,我今天没有时间深入介绍。如需了解更多信息,请联系我们或访问 intel.com/agilex。
与上一代 FPGA 相比,Agilex 的性能提高了 40%,功耗降低了 40%,还能实现更高的收发器数据速率。Agilex 还提供高达 40 TFLOPS 的 DSP 性能。Agilex 支持 DDR5、下一代 HBM 以及 PCIe Gen5 和 Compute Express Link (CXL),这对 HPC 客户来说尤其重要。
最后,以我提到的关键信息结束我的演讲:高性能计算客户正在进行一场性能竞赛。FPGA 可以通过提供独特的功能对系统进行补充,从而提高性能并降低总体拥有成本。
现在,Agilex FPGA 无法单独用于数据中心,当然还必须有一个企业级板卡来承载 FPGA,并在板卡上配备所有必要的接口和所需的元件,例如内存。在 BittWare 的帮助下,市场上出现了基于 Agilex 的加速卡,以提高数据中心的性能。现在,克雷格,交给你了。
(克雷格)
谢谢你,克里斯蒂安,欢迎大家收看今天的网络研讨会。
Molex 是全球最大的设计和制造公司之一,为包括高性能计算在内的一系列市场的主要客户提供服务。
BittWare 是 Molex 数据中心集团的一部分。
BittWare 设计和制造企业级加速产品,采用最新最先进的 FPGA,今天的网络研讨会我们将重点介绍英特尔 Agilex FPGA。
这些高性能可编程加速器使我们的客户能够快速、低风险地开发和部署基于英特尔 FPGA 的解决方案。
我们的产品用于快速原型开发和基准测试,但最终还是要用于具有成本效益的批量部署。
当我们考虑高性能计算时,我们会将其细分为三个主要应用领域:计算、网络和存储。
其中,有许多工作负载非常适合 FPGA。例如,自然语言识别、推荐引擎、网络监控、推理、安全通信、分析、压缩、搜索等等。
在 BittWare,我们努力降低在英特尔 FPGA 上实现这些工作负载的成本、工作量和风险。
我们的第一种方法是利用 FPGA 设备(本例中为英特尔 Agilex FPGA)创建平台产品。
这些主要是 PCI Express 卡,外形尺寸包括 HHHL、FHHL 和双插槽 GPU,但我们也支持一些存储外形尺寸,包括 U.2。
每个卡或模块都符合官方规范,以确保与现有和新的基础设施兼容。
可以单独购买板卡,也可以将板卡重新集成到经过 FPGA 优化的服务器中,我们称之为 TeraBoxes。通常情况下,我们会利用领先供应商提供的服务器,如幻灯片中列出的供应商。
如图所示,我们目前正在发运三款英特尔 Agilex 产品。
GPU 尺寸的 IA-840f 显卡是我们目前的旗舰产品。它采用 AGF-027、四组 DDR4 内存、网络端口和扩展端口。我们的 Stratix 10 MX 卡支持 oneAPI 已经有几年时间了,但 840f 是我们第一款支持 oneAPI 工具流的基于 Agilex 的卡。
英特尔的 oneAPI 是一项大胆而受欢迎的举措,旨在引入统一的软件编程模型。通过使用 oneAPI,我们的客户能够从单一的代码库中进行编程,并在不同的体系结构中实现本地高级语言的性能。
oneAPI 包括一种直接编程语言:数据并行 C++ 和一套基于 API 的编程库,使跨架构开发变得更容易。
Data Parallel C++ 基于熟悉的 C++,并结合了 Khronos Group 的 SYCL。这大大简化了代码在多种架构中的重复使用,并可对加速器进行定制调整。
从根本上说,它向通常使用 x86 或 GPU 技术的软件客户开放了 FPGA。任何希望在 Agilex 上使用 oneAPI 进行开发和基准测试的客户都应考虑使用 BittWare '840f 卡。
BittWare 率先在英特尔 Stratix 10 卡上支持 oneAPI。在这些实施中,我们使用 OpenCL 层作为板卡支持包。设计示例和白皮书可在网站的资源部分找到。
对于基于英特尔 Agilex 的产品,我们的 oneAPI 实施采用了英特尔开放 FPGA 堆栈(或称 "OFS")。
对于那些希望完全放弃 FPGA 编程的客户,您可以通过 BittWare 合作伙伴计划购买我们的 FPGA 加速卡,该卡预编程有 Atomic Rules、Edgecortix 和 Eideticom 等领域专家提供的应用代码。
展望 2023 年及以后的新技术,对于高性能计算的未来而言,没有比 CXL 更重要的了。
CXL 是 Compute Express Link 的缩写,是新的加速器链接协议。它以现有的 PCIe 协议为基础,在其基础上增加了额外的功能,允许主机与加速器之间进行连贯通信。在本例中,它指的是英特尔 Agilex FPGA。这使得 CXL 链接在与用于异构计算的侧视或内联加速器一起使用时,能够实现高效、低延迟、高带宽的性能。
BittWare 发布了三款支持 CXL 的新型 FPGA 加速卡。440i 和 640i 是单宽 HHHL 和 FHHL 卡,支持 I 系列 Agilex FPGA。
我们充分利用了 F-Tile 对 400 千兆位以太网的支持和 R-Tile 对 PCI Express Gen 5 x16 的支持。
GPU 大小的 '860m 卡采用了突破性的 M 系列 Agilex FPGA,封装内支持高达 32GB 的 HBM2 内存,外部支持 DDR5 内存。这对于高性能计算,尤其是需要内存的应用来说,是一款不可多得的设备。
BittWare 能够支持 CXL,是因为 Agilex I 系列和 M 系列 FPGA 系列都采用了硬 IP,允许支持第 5 代 x16 配置的全部带宽,同时最大限度地减少了对 FPGA 资源的使用。
我们有望在 2023 年第一季度交付首批支持 CXL 的 FPGA 卡。
那么,为什么 CXL 如此重要呢?我们的客户已经明确表示,他们需要更高的性能、更好的能效以及在应用中访问不同存储器的计算能力。
大家一致认为,CXL 将使采用 FPGA 的异构计算架构的性能达到一个新水平。
与同类解决方案相比,英特尔 Agilex FPGA 每个端口提供 4 倍的 CXL 带宽,每个端口提供 2 倍的 PCIe 带宽。
随着云计算越来越普及,客户需要不断改进其架构,以提供更快、更高效的数据处理。
这意味着我前面提到的三大应用领域的创新。具体来说,就是将用于计算密集型工作负载的加速器技术、网络区域内可即时处理数据的智能网卡以及存储平面内可静态处理大量数据的计算存储紧密结合在一起。
计算、网络和存储技术已经通过 PCI Express 进行连接,但要实现应用性能的飞跃,它们需要利用 CXL 的优势。
CXL协议描述了CXL连接设备的三种使用配置。
类型 1 设备可用于流媒体和低延迟应用,如智能网卡,在这种应用中,加速器需要连贯访问处理器内存,而主机无需访问自身内存。
类型 2 设备的实现最为复杂,因为它能处理所有三个 CXL 子协议:这种类型适用于人工智能推理、数据库分析或智能存储等复杂任务。
第 3 类设备允许主机连贯地访问连接到 CXL 设备的任何存储器。在这种情况下,FPGA 仍能通过实施特殊的 FPGA 逻辑(如独特的压缩和加密算法)提供有价值的优势。
对于那些不了解情况的人来说,英特尔 FPGA CXL IP 是硬 IP 和软 IP 的组合。
为了设计使用英特尔 CXL IP 的应用,客户需要购买单独的 IP 许可。
激活英特尔 CXL 许可后,您就可以在 Quartus Prime 工具中找到英特尔 IP。
一旦Agilex R-Tile的CXL硬IP被激活,那么适当的软IP将被添加到设计中。
请注意,BittWare PCIe 卡上的 Agilex I 系列 FPGA 具有 CXL 1.1 和 2.0 功能。
展望未来,英特尔制定了支持 CXL 3.0 的路线图,该路线图与 PCIe Gen 6 规范紧密相连。
因此,CXL 将变得非常重要。任何观看本次网络研讨会的人,如果其工作涉及了解和评估新技术,就必须考虑 CXL。
为了帮助客户实现这一目标,BittWare 正在开发一个完整的 CXL 开发和基准测试平台。
它包括一个 2U 机架式服务器,采用英特尔蓝宝石急速至强 CPU。此外,还预集成了 BittWare 的英特尔 Agilex I 系列 FPGA 卡。
将预装 Linux 操作系统以及开始开发所需的英特尔 Quartus 和 CXL 许可证。
我们希望客户能够快速上手,因此该捆绑包将包括一个利用 CXL 的应用示例参考设计。
在提供技术支持服务的同时,还提供涵盖服务器和 FPGA 硬件的技术支持和全面保修服务。
这只是我们所提供服务的一个缩影。完整的详细信息将在适当的时候公布。同时,请联系 BittWare 了解更多详情。
下面,我请毛里齐奥为大家介绍网络研讨会的下一部分内容。谢谢大家。
(Maurizio)
谢谢你,克雷格。
现在让我们来看看本案例研究中使用的编程模型 oneAPI。
IA-840f 等可编程加速卡是异构计算架构的强大构件。异构架构在高性能计算领域正变得越来越流行,因为并非所有的工作负载都是一样的,而且没有一种单一的计算架构--无论是 CPU、GPU、FPGA 还是专用加速器--能适合所有的工作负载。采用异构架构后,程序员可以从吞吐量、延迟和能效方面为每种工作负载选择最合适的架构。
然而,为异构架构开发代码并不是一项简单的任务,它意味着巨大的挑战。如今,每种以数据为中心的架构都需要使用不同的语言和库进行编程。这意味着必须维护独立的代码库,而跨平台移植则需要付出巨大的努力。此外,跨平台的工具支持不一致意味着开发人员必须浪费时间学习不同的工具集。
简而言之,为每种硬件平台开发软件都需要单独投资,而且几乎无法针对不同的架构重复使用这些工作。
英特尔对这一问题的解决方案是 oneAPI,该项目旨在提供跨 CPU 和加速器架构的统一软件开发环境。
这不是一个专有项目。相反,它基于一个开放的行业倡议,旨在联合开发规范,在整个生态系统中开发兼容的实施方案。
随后,英特尔公司将该编程模型作为一套工具包加以实施,并将在下一张幻灯片中加以介绍。
oneAPI 编程语言是数据并行 C++。这是一种专为提高数据并行编程效率而设计的高级语言。它以 C++ 语言为基础,具有广泛的兼容性,并通过 GPU 软件开发人员熟悉的编程模型,简化了从专有语言迁移代码的过程。
该语言的起点是由行业联盟 Khronos Group 开发的 SYCL。英特尔和社区正在通过扩展来弥补语言上的不足,我们将把这些扩展纳入标准。
数据并行 C++ 允许在不同的硬件目标上重复使用代码:CPU、GPU 或 FPGA。不过,仍然需要针对每种架构进行调整,以最大限度地提高性能。
如前所述,英特尔的 oneAPI 参考实现是一套工具包。
工具包包括
- 这是一款针对 CPU、GPU 和 FPGA 的数据并行 C++ 编译器,利用了久经考验的 LLVM 编译器技术以及英特尔在编译器领域的领先历史。
- 源代码到源代码的移植工具,可帮助使用 CUDA 编写现有代码的开发人员轻松过渡到 DPC++。
- 对于基于应用程序接口(API)的编程,一系列性能库涵盖了多个工作负载领域,可从加速中获益,其中库函数是为每个目标架构定制的,因此当开发人员在支持的架构之间迁移代码时,无需对开发人员进行调整。
- 最后是分析和调试工具,包括增强版的 VTune Profiler 和 Advisor 性能工具。
请注意,到目前为止,基于 API 的 FPGA 编程支持还很有限。
要开始在 FPGA 上构建和运行数据并行 C++ 代码,用户需要下载并安装由以下部分组成的开发软件栈:
- 英特尔 oneAPI 基础工具包通过生成报告为代码仿真和静态性能分析提供支持。
- 用于 oneAPI 基本工具包(包括 Intel Quartus Prime)的 Intel FPGA 附加组件,支持 FPGA 比特流编译和在 FPGA 上执行代码。
- 最后,还要为所使用的板卡提供板卡支持包。这是由板卡供应商提供的。就本案例研究中使用的 IA-840f 卡而言,板卡支持包由 BittWare 提供。
oneAPI 开发堆栈为不熟悉传统 FPGA 基于 RTL 的设计方法的软件编程人员提供了访问 FPGA 平台的便捷途径。RTL 设计意味着要深入了解 FPGA 架构细节和时序闭合等高级主题。使用 oneAPI,这些细节将由编译器和 BSP 处理,因此 FPGA 编程所需的工作量与任何其他平台相当。
现在有请 Cesar 介绍我们今天要讨论的案例研究。
(塞萨尔)
大家好,我是巴塞罗那超级计算中心的塞萨尔-冈萨雷斯(Cesar Gonzalez),我想向大家介绍一下我们正在使用 FPGA 设备进行的研究。
首先,我想向你们展示我们的超级计算机:"MareNostrum"。如果您来巴塞罗那,您可以参观它(当然,您也可以参观我们的古迹,如圣母百花大教堂)。
我们要做的事情:我们要确定任何其他系统都无法确定的小分子结构。我们将如何做到这一点:我们将利用这些分子的光谱来做到这一点。如果我们有了分子的光谱,如何才能找到结构呢?
因此,我们利用--上个世纪已经证明了--可以在三维空间中建立分子模型,然后再建立该理论模型的光谱,并将该光谱与真实光谱进行比较。
如果光谱相同,就说明结构已经确定。如果不一致,您可以重新配置模型,计算新的光谱,看看是否与真实光谱一致。
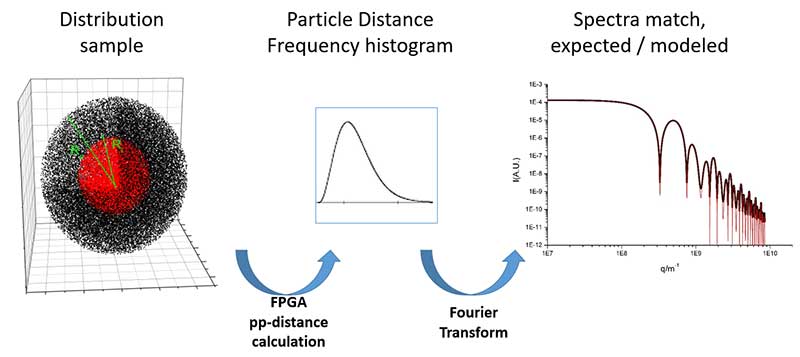
好吧,那我们第一次是为了什么?就是做个测试,看看它是不是......是不是真的。我们在双密度球中测试了两百万个电子,你可以在幻灯片上看到。
因此,既然我们知道这个双球体光谱的解析解,我们就可以计算出这个球体的理论光谱,然后与光谱的解析解进行比较。
因此,这里就是所有事情的关键所在:要计算这个模型的光谱(我们就像使用测试一样),我们必须计算出这个模型中两个粒子的所有距离。
这就是高性能计算的优势所在,因为当粒子数量非常多时,对所有距离进行计算的时间就非常非常长。因此,我们这里有 200 万个电子的样本分布,这就是我们的测试。
我们计算了这两个密度球模型的直方图。好的。
我们选取两个粒子,计算它们之间的距离,然后将[第一个]粒子的密度乘以第二个粒子的电子密度,并将这一权重置于直方图的距离位置。
以距离为 100 埃的两个粒子为例:把这对粒子的电子重量放在直方图的 100 埃......X[轴]......这里。好的。
因此,如果它们有 200 埃的距离,你就把它们放到另一边。如果又有一两个 200 埃的距离,则将其添加到直方图中,并绘制直方图。在这里,我们使用 FPGA 进行距离计算。
之后,当你得到完整的直方图后,进行傅立叶变换,你就可以看到你计算出的结果,也就是这里的红线,是否与解析解(也就是另一条线)相同,你可以看到这与解析解相吻合。因此,我们证明了上个世纪的理论是正确的。
因此,我们进入了另一个步骤,那就是取一个我们知道结构的真实分子,然后建立这个分子的理论模型,之后再看这些模型是否真的与分子的光谱相匹配。
这是山嵛酸银电池。这个电池有两个分子的山嵛酸银。我们制作这个电池是因为我们知道山嵛酸银的真实结构,然后再制作模型。这是模型,我们用了什么呢?就是把 25×25×3 的单元重复一遍。我们用 FPGA 进行了理论光谱分析,结果出来了。
这里有什么?
绿线是山嵛酸银的真实光谱。蓝色为哈特里-福克(Hartree-Fock)量子分布电子计算结果。
黑线是电子的随机分布,红线是用原子而不是电子来计算性能的装置。
我们使用的......也是另一种测试,只是为了看看我们是否与真实模型相匹配。因此,你可以看到,如果我们使用哈特里-福克的量子分布,匹配结果与设备完全一致。
我们将绿线上移,只是为了看看这些是否吻合,因为对我们来说最重要的是峰值的位置。如果山峰在各自的位置上,我们就能知道结构。
正如您所看到的,当我们使用随机电子分布时,图末的真实光谱与使用电子量子分布密度的哈特里-福克分布求解的光谱之间存在差异。
因此,我要感谢英特尔公司和我所在的加泰罗尼亚高级化学研究所,还要感谢阿尔巴同步加速器,我们一直在那里研究山嵛酸银的光谱。
感谢大家观看本次演讲,我还想邀请大家参阅我们的科学文章,大家可以参阅本 DOI 参考文献,也可以参阅我们在巴塞罗那超级计算中心的摘要集,了解我们的研究情况。谢谢,再见。
(Maurizio)
谢谢你,塞萨尔。
现在,让我们来看看本案例研究中采用的算法。 这种算法被称为粒子对距离算法或 pp-distance 算法,具体描述如下。
给定一组位于三维空间中的 N 个粒子,对于每一对可能的粒子,计算它们之间的距离。
在我们的案例研究中,每一对的功率密度都会被累积到与计算距离相对应的分区中。距离使用单精度浮点运算,然后转换为整数进行分选,累积则使用双精度浮点运算。
这个问题的复杂度是 N 的平方,因为 N 个点集合中点对的数量以相同的系数递增。
该算法最初用 OpenCL 实现,并在两种不同的可编程加速卡上进行了测试:英特尔 Arria 10 GX 卡(基于英特尔 Arria 10 1150 FPGA)和英特尔 D5005 卡(基于英特尔 Stratix 10 SX 2800 FPGA)。随后,该算法被移植到 DPC++ 中,并在 BittWare IA-840f 卡(基于英特尔 Agilex AGF027 FPGA)上实现。
本次实施使用的工具链是 oneAPI 2022.2 版和 Quartus Prime Pro 21.4 版。我们将在本演示文稿的稍后部分介绍上述所有配置所取得的结果。
现在,让我们快速了解一下该算法的参考实现。这是一个 OpenCL 内核,它的输入包括集合中的点数、结果所用的箱数以及存储点数据(坐标和相关功率)的数组指针,并返回累积结果数组。内核的核心是两个嵌套循环(红框内),其中计算点对的距离并进行功率密度累积。
上一张幻灯片中的参考实现在 FPGA 上运行之前已经过适当优化。正如克里斯蒂安在前面提到的,在 FPGA 中,内部架构是根据要实现的算法来配置的。
因此,为 FPGA 进行编码意味着要塑造计算数据路径的架构,这与 CPU 和 GPU 的情况不同,因为 CPU 和 GPU 的计算架构是固定的。在针对 FPGA 进行优化时,程序员会使用 oneAPI 工具链提供的信息(代码静态分析和动态剖析报告)来识别已实现数据路径中的性能瓶颈,并使用编码技术消除或缓解这些瓶颈。如果您有兴趣了解更多有关 FPGA 代码优化的信息,英特尔和 GitHub 网站上都提供了相关文档、培训材料、教程和设计示例。
我们对原始代码进行了多项优化,以提高内存访问和计算效率。结果,与原始代码相比,性能提高了一千倍以上。
我在上一张幻灯片中提到过,这段代码最初是用 OpenCL 编写的,后来移植到了 DPC++。现在,移植代码是一项相当简单的任务,所需的改动非常有限。基本上,内核代码架构必须适应 DPC++ 的编码风格,这意味着内核本身使用了 lambda 函数,定义了数据移动的访问器,并根据新语言调整了实用程序和属性的语法。另一方面,主机代码被大大简化,因为在 OpenCL 中必须明确管理的许多细节在 DPC++ 中都由运行时自动处理。因此,DPC++ 主机代码的大小只有 OpenCL 对应代码的一半。
现在让我们来看看结果。
请注意,FPGA 的代码是参数化的。这使得用户可以探索实现的架构空间,并在目标内核时钟和频率与数据并行性之间找到最佳权衡--这就是解卷因子。
表中的结果显示了每种情况下的最佳权衡结果。
第一行指的是在主机 CPU(即至强冰湖处理器)上以单线程代码运行的算法顺序实现。该算法在 9600 秒(即 2 小时 40 分钟)内处理了 200 万个点的数据集。
在 IA-840f 卡上运行的 DPC++ 实现,在以双精度浮点执行所有累加时,处理相同数量的数据只需 61 秒,比顺序实现快 157 倍。如果使用 40 位整数进行部分累加,处理时间将降至 41 秒,快 233 倍。
此外,与上一代高端 FPGA 相比,Agilex FPGA 允许更高的时钟频率和更高的数据并行性,从而使性能提高一倍。
本次演讲到此结束。感谢您关注我们。现在进入问答环节。
(马库斯)
好了,马库斯将回到我们的问答环节,在此之前,我想先回顾一下。我们已经收到了很多信息,也已经收到了一些问题。我只想提醒大家,如果你有问题想问我们的专家组成员,请使用提问功能把问题打出来,我们会把它发给我们的专家组成员。
我一定要特别感谢莫里齐奥和塞萨尔对高性能计算中心工作的介绍和细节......他们在巴塞罗那超级计算中心的高性能计算工作。
新的Agilex系列FPGA集性能和功能于一身,非常适合高性能计算工作负载。我们还讨论了使用oneAPI编程模型的问题,这是任何从事高性能计算的人都至少应该考虑的,因为它允许代码的可移植性、灵活性,以及Maurizio所谈到的那些东西。
我们看到,代码从基于 Arria 10 的显卡移植到 Stratix 10,两者都使用 OpenCL,然后 Maurizio 将 oneAPI 移植到 BittWare 的新 IA-840f Agilex 显卡上......使用 oneAPI,这只是一个非常快速、流畅的工作流程变化--这就是优势之一。
最后,我们还听到了性能。Agilex 设备在高性能计算工作负载上的性能和加速度数据令人印象深刻。
然后我们还听到了 CXL,所以 Craig 提到了 BittWare 即将推出的新 CXL 开发包。如果你想了解更多信息,请与我们联系。
好了,现在开始提问。
我想先问问塞萨尔。我们谈到了你们使用的 FPGA,但你们是在什么情况下决定在特定应用中使用 FPGA 的?
(塞萨尔)
事实上,我最先使用 C CUDA 对 GPU 进行编程,后来我们又使用了 FPGA,因为团队中的所有人都能直接理解高性能计算组件的实用性,而这些组件的工作原理也非常容易理解。对我们来说,让所有人都能理解 OpenCL 内核非常重要。
此外,你所拥有的所有经验,你在 FPGA 上做的所有事情,以后都可以在 GPU 上实现。总之,我们会看到一些限制,使用限制,以及使用 GPU 带来的一些便利或不便。例如,如果模型大 10 倍,GPU 中的时间就是两倍。与此同时,在 FPGA 中的时间是一样的。但这并不意味着 FPGA 就比 GPU 好。我们所处的环境不同。对我们来说,FPGA 更好。在我攻读博士学位之初,我曾向英特尔公司提出一个问题:"如果你去火星,你会带什么?GPU还是FPGA?笑
(马库斯)
是啊,这是个好问题。是的,这个比喻很好,我很欣赏。
你能简单回顾一下吗?我知道你详细介绍了你使用的过程,但最终结果是什么?我知道你在一开始就谈到了,但就......你将把这些结果用于什么用例?
(塞萨尔)
当你能确定一个分子的结构时--就在那里--你就能为病人制造治疗方法或药片,以及所有这些东西。因此,我们正在生物医学和纳米技术的基础上开展工作。因此,这对医生和其他人来说非常重要,因为他们想知道我们如何才能阻断这种分子或其他分子。这一点非常重要--是的。