
白皮书
FPGA加速的NVMe存储解决方案
使用BittWare 250系列加速器
概述
近年来,向基于NAND闪存的存储迁移和非易失性存储器Express®(NVMe™)的引入,使技术公司以不同方式 "做存储 "的机会成倍增加1。实时数字业务的快速增长和多样性要求这种创新,以使新产品和服务得以实现。
简介
近年来,向基于NAND闪存的存储迁移和非易失性存储器Express®(NVMe™)的引入,使技术公司以不同方式 "做存储 "的机会成倍增加1。实时数字业务的快速增长和多样性要求这种创新,以便实现新产品和服务。因此,新的存储产品一直遵循着更高的带宽、更低的延迟以及减少占地面积和总拥有成本的趋势--这对于依赖大型基础设施的公司来说是至关重要的改进。最近的市场报告2预测,NVMe市场将以大约15%的复合年增长率增长,到2020年达到570亿美元。NVMe市场继续发展,在三个领域寻求进一步的技术创新:
- 存储虚拟化以提高灵活性和安全性
- 贴近存储数据的本地化数据处理
- 用于优化基础设施的分列式存储3
2018年3月,BittWare宣布推出250系列FPGA产品,提供创新的解决方案,以满足存储市场的需求。250系列产品采用Xilinx® UltraScale+™ FPGA和MPSoC,在单芯片中提供ASIC级功能,符合存储行业的技术需求6。通过将NVMe与可重构逻辑FPGA和MPSoC相结合,BittWare提供了一类新的存储产品,在快速发展的市场中具有重要的差异化优势;Xilinx器件的灵活性和可重构性保证了基于20的解决方案能够在NVMe标准不断融入新功能的过程中保持最新状态5。
本应用说明介绍了BittWare的250系列FPGA和MPSoC支持的加速器产品如何用于让客户为下一代物联网和云基础设施构建高性能、可扩展的NVMe基础设施。
NVMe 路线图
自2011年NVMe创建以来,NVMe联盟一直非常活跃。事实上,NVMe协议目前正在从三个角度发展,分别定义在不同的规范中。除了基本的NVMe规范外,NVMe管理接口(NVMe-MI)详细说明了如何管理通信和设备(设备发现、监控等),NVMe over Fabric(NVMe-oF)推动了如何通过网络与非易失性存储进行通信,使该协议与传输无关9。
随着时间的推移,随着更多来自不同行业的用户开始采用NVMe,新的用户表征了他们对新功能的需求,并为该规范引入了新的想法。NVMe协议的采用仍在增长,它正在产生创新。硬件和软件公司正在寻找新的方法,通过引入新的外形尺寸,创造新的产品和设备等,来获取内存。NVMe生态系统的重点是为用户提供扩展到数据中心或超大规模基础设施的手段,而协议规范将继续朝着这个方向发展9。
2019年将发布NVMe基本规范的1.4修订版,这将导致数据延迟的改善,对非易失性数据的高性能访问,以及几个主机之间数据共享的便利。NVMe用户,特别是云供应商期待的功能之一是IO确定性,这将提高IO并行执行期间的服务质量10。通过将后台维护任务的影响限制在最小范围内,并控制嘈杂的邻居的影响,IO确定性功能将使用户在访问非易失性数据时拥有一致的延迟。另一种方法是之前讨论的开放通道架构11。通过这第二种方法,主机接管了一些管理功能,只有数据传输到存储硬件。在这种配置中,硬盘与主机的物理接口只限于高速数据通道,没有边带通道。这个例子显示了NVMe规范中任何变化的影响和相关性,并强调了对灵活的NVMe硬件基础设施的要求。
随着基础、MI和over Fabric规范的新修订在未来几个月内出台,NVMe用户将受益于一个灵活的基础,可以适应新的NVMe要求。250系列FPGA和MPSoC产品不仅提供了这种灵活性,而且还解决了当今客户的挑战,使他们立即获得了竞争优势。
为什么是FPGA?
BittWare的FPGA和MPSoC产品采用了最新的Xilinx UltraScale+技术,符合日益关注NVMe的数据中心的需求。三十年来,FPGA已经为多个行业提供了可编程的硬件解决方案,并被广泛用于解决汽车、广播、医疗和军事市场等领域的计算和嵌入式系统问题。同时,近年来,FPGA制造商为这项成熟的技术引入了最新和最先进的集成系统设计改进。
赛灵思UltraScale+ FPGA和MPSoC产品采用16纳米工艺,通过提供高速结构、嵌入式RAM、时钟和DSP处理,提高系统性能。此外,赛灵思器件还引入了更快的收发器技术(高达32.75Gb/s),以实现与网络或PCIe结构的高吞吐量连接。凭借其高数量的串行收发器通道,UltraScale+产品可以同时连接到多个PCIe接口,并向主机CPU提供数据卸载接口。在某些情况下,通过用FPGA或MPSoC取代PLX开关,CPU可以卸载一些处理工作,腾出时间用于其他操作。FPGA和MPSoC的可编程逻辑还在系统中提供了一个确定的和低延迟的接口,这在某些用例中可以带来明显的竞争优势。
最近的FPGA系列现在还包括器件结构内的嵌入式低功耗微处理器。UltraScale+ MPSoCs将需要软件和可编程逻辑的应用结合到一个单一的封装中,从而满足了这些应用的需要。例如,赛灵思Zynq UltraScale+ ZU19EG具有两个处理单元,一个四核ARM Cortex-A53和一个实时双核ARM Cortex-R5,此外还有一个图形处理单元,即ARM Mali™-400 MP2,用于满足混合计算的应用。ZU19EG MPSoC器件是一款非常通用的芯片,特别适合NVMe over Fabric或Open Channel的实施,其中可编程逻辑为存储数据提供了低延迟的确定性路径,而ARM内核执行复杂的数据包控制操作或在无CPU的嵌入式系统中替代主机CPU。
在过去几年中,BittWare一直处于存储行业的前沿,并通过开发基于NVMe技术的产品为其创新发展做出了贡献。BittWare认识到,FPGA可以减少I/O瓶颈,为NVMe固态硬盘提供直接的高速确定性路径。早在2015年,BittWare就与赛灵思和IBM合作,开发了一个创新的NoSQL数据库解决方案12。250系列FPGA&MPSoC板在这个初始产品的成功基础上,增加了更深更快的板载存储器、网络连接、片上系统和服务器存储背板的布线选项等功能。
空标题
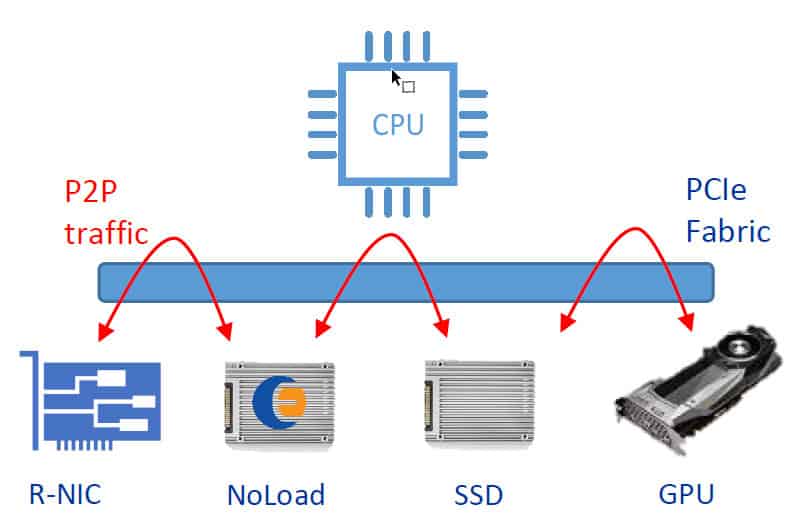
250个FPGA和MPSoC产品系列
250 FPGA和MPSoC产品线包括三个FPGA适配器,即250S+、250-U2和250-SoC,它们可以连接到各种行业标准的形式因素,如PCIe插槽、OCuLink/Nano-Pitch、SlimSAS、MiniSAS HD、U.2存储背板等等。250系列产品适合于现有基础设施的PCIe结构,可直接低延迟地访问NVMe存储设备。
250S+直接连接的加速器
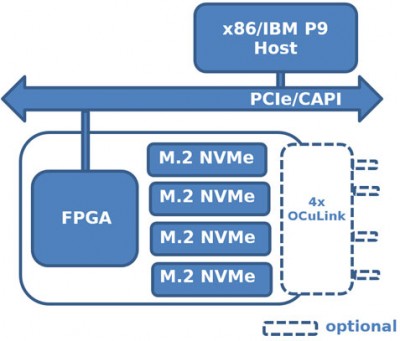
该系列的第一个加速器是250S+。这款FPGA加速器具有Xilinx UltraScale+ Kintex 15P FPGA和四个板载四通道1TB M.2 NVMe驱动器(共4TB非易失性闪存),采用低调的8通道半高半长PCIe兼容外形。另外,对于只想在系统中引入FPGA计算并且已经有存储空间的客户,M.2板载连接器可以使用Molex低损耗高速布线技术,将电缆连接到OCuLink/Nano-Pitch或MiniSAS HD NVMe背板。KU15P FPGA拥有1,143K系统逻辑单元、1,968个DSP片和70.6 Mb嵌入式存储器,是UltraScale+ Kintex FPGA系列中最大的器件,为实现增值功能提供了大量的可配置资源。板载的DDR4存储器组允许对更深的数据向量进行额外的缓冲。


- 多达四个M.2 NMVe固态硬盘与赛灵思FPGA的卡上耦合
- OCuLink断开布线,允许250S+成为大规模扩展的存储阵列的一部分
直接连接的加速器(DAA)
- 虚拟化NVMe存储并在多个虚拟机上共享
- 隔离NVMe存储,提高主机CPU和NVMe SSD之间的安全性
- 250S+ & 250-SoC
250-U2代理线内加速器
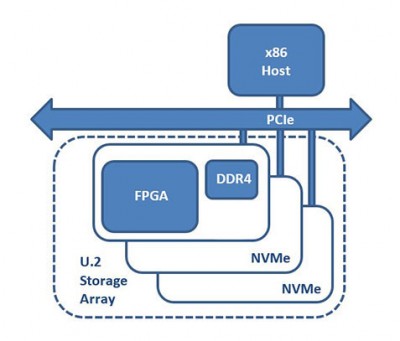
250系列的第二个成员是250-U2。该加速器板具有Xilinx UltraScale+ Kintex 15P FPGA(与250S+相同)和一组DDR4内存,采用2.5英寸U.2驱动器的外形尺寸。与250S+不同,250-U2没有任何直接连接到FPGA的板载固态硬盘。这款加速器的新颖设计使其可以在没有专用PCIe插槽的系统中融入现有的U.2存储背板,在现有的标准U.2 NVMe存储旁边获得额外的计算能力。这个250-U2产品承担了代理在线加速器(PIA)的角色。

250-U2可以执行在线压缩、加密和散列,还可以执行更复杂的功能,如擦除编码、重复数据删除、字符串/图像搜索或数据库排序/连接/过滤。根据应用的计算需求,背板人口将显示不同比例的250-U2板用于NVMe驱动器。250-U2位于U.2背板中,与存储设备并列,具有与任何其他利用NVMe-MI规范的标准U.2 NVMe驱动器相同的维护选项。由于250-U2处理节点和存储直接连接到主机服务器的PCIe结构,DMA数据流量可以完全绕过CPU和全局内存,利用SPDK等技术实现优化的端点到端点数据传输。通过RDMA或点对点DMA解决方案,数据在NVMe端点之间直接流动,完全绕过CPU。这些直接进入FPGA和MPSoC可编程逻辑的接口大大降低了访问延迟(Lusinsky, 201721)。另外,这个硬件平台的另一个用例是作为一个卸载计算引擎,并且很适合于FPGAaaS可扩展的基础设施。
代理在线加速器(PIA)
- 对本地NVMe存储数据进行低延迟、高带宽的处理
- 多种主机形式因素 8通道PCIe适配器或2.5英寸U.2
- 250S+和250-U2
250-SoC for NVMe-over-Fabric
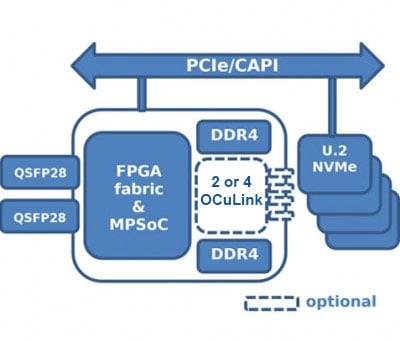
该系列的第三个加速器,即250-SoC,采用Xilinx UltraScale+ Zynq 19EG MPSoC,可以通过两个QSFP28端口(支持100GbE的25Gbps线速)连接到网络结构,或者通过一个16通道的PCIe 3.0主机接口和四个8通道的OCuLink连接器连接到PCIe结构。ZU19EG是其系列中最大的设备,有1,143K系统逻辑单元、1,968个DSP片和70.6 Mb的嵌入式存储器。器件封装中的嵌入式ARM处理和图形单元为具有混合处理要求的产品创造了一个理想的平台。
250-SoC硬件的多功能性允许从网络直接访问存储,并支持NVMe-over-Fabric。NVMe-oF是下一代NVMe协议,可以通过网络结构分解存储并远程管理存储;NVMe-oF还提供了比SAS更多的灵活性,可以按需设置网络阵列。分散存储或EJBOF(Ethernet Just-a-Bunch-Of-Flash)硬件降低了数据中心的存储成本、占地面积和功率。
赛灵思Zynq MPSoC芯片为嵌入式系统提供了额外的灵活性。MPSoC板可以独立于主机CPU运行操作系统及其全部软件栈。凭借其支持两个100GbE端口的高带宽网络功能和板载MPSoC,250-SoC消除了对外部网络接口卡(NIC)和NVMe-oF应用的外部处理器的需求13。基于FPGA的NVMe-oF基础设施的实施是简单而有效的,因为数据只通过硬件路径,这就提供了一个低而可预测的延迟解决方案。
网络虚拟机(NVMEoF)
- 数据中心网络结构上的NVMe帧的低延迟和高吞吐量
- 250-SoC
250-SoC为存储行业提供了一系列灵活的解决方案。250S+和250-SoC通过针对直接连接加速器的使用情况,满足了虚拟化和提高安全性的需要。250-U2和250S+可作为代理在线加速器轻松插入现有基础设施,为NVMe存储提供低延迟和高带宽的本地数据计算。最后,250-SoC支持NVMe-over-Fabric,这是一种仅靠硬件的创新方法,可以在支持最新一代NVMe协议的同时分解存储。随着NVMe市场的不断发展,FPGA和MPSoC解决方案将解决NVMe产品的应用挑战。
NVMe应用
NVMe技术给存储带来了颠覆性的创新,对数据中心基础设施产生了深远的影响。该协议的特点使NVMe成为设计涉及存储的新产品或应用时的首要选择。
企业应用,如数据库加速,需要低延迟以及高带宽的4K或8K数据写入传输率,这两个要求完全符合NVMe协议的优势。这些特性使NVMe在实现重做日志方面处于领先地位,例如,在这种用例中,许多交易记录被存储起来,并在数据库发生故障时用于未来的重放。对于这个用例,250S+将高达4TB的NVMe存储直接带到FPGA可重构结构的边缘,交易记录被高速收集到SSD,准备进行重放14。
NVMe还减轻了虚拟化基础设施的挑战,简化了虚拟机(Virtual Machines)、无状态虚拟机和SRIOV的实施,其中IO是最常见的瓶颈。在无状态虚拟机的使用案例中,IT经理需要锁定企业用户不修改的操作系统图像。用户只修改他们的数据,操作系统镜像在NVMe存储中保持不变;用户之间的隐私和安全是至关重要的。对于这样的IT基础设施,NVMe存储在多个用户之间共享。250S+是实现这一应用的多合一平台。每个1TB的物理驱动器被FPGA IP分割,因此每个用户都能安全地隔离访问其操作系统图像和数据。管理程序管理着对部分驱动器的直接访问,而不需要仿真驱动,这为这个有IO限制的应用提供了更好的性能。
"大数据 "市场也为结合了存储和处理的智能NVMe产品带来了机会,因为它正在从批处理方法转向实时处理方法。地图还原问题正在转向实时分析,而不是批处理,因此,它们需要一个新的存储层,其速度比GFS后端快得多。现在在IT基础设施中看到的存储分层将很少访问和低速的冷存储分离到非常快的SSD、NVMe或NVM存储器。在这个用例中,所有的数据都被记录在GDFS中,但随后被转移到具有更快的内存的计算节点中。实施NVMe-over-Fabric的250-SoC满足了这两个要求,因为它可以访问高速存储和高性能计算能力。
深度学习行业与分析领域有类似的需求。用于深度学习的新一代加速器,即GPGPU、TPU和FPGA;这些设备需要大的内存带宽来配合芯片的计算能力。训练操作会消耗大量这种高吞吐量的数据,通常是多兆字节15。最近的研究工作表明,FPGA结构可以加速某些网络类型的训练操作。因此,将存储和计算引擎结合到一个硬件平台上,可以减少延迟,随着训练数据集的增加,可以有更多的再训练周期16。
在HPC领域,250S+的本地存储和250-SoC的远程版本有几种应用,如检查点/重启、突发缓冲器、分布式文件系统或从调度器中缓存作业数据。通过在FPGA结构上靠近存储的地方运行算法,FPGA应用的占用率仍然很低,同时充分利用存储,并将CPU腾出来用于其他处理工作。而不是简单地存储数据或使用主机CPU来压缩或加密内存中的数据库,其中数千兆字节的数据保存在易失性存储器中,但需要定期备份到闪存。基于FPGA的系统可以处理这些数据快照,以便永久存储到基于NVM的大型存储阵列。对于这种类型的操作,MPSoC特别适合于对用户数据进行更复杂的操作。
最后,在物联网领域,需要在物联网网关上进行数据过滤和预处理,在收到数据后对其进行加密,FPGA通过加密或压缩等位操作实时处理数据流,并使用250S+将数据存储在板上,或通过有线的250S+或250-SoC在输入带宽上将其传递给存储背板。FPGA也是区块链计算的首选平台。区块链技术给物联网网关带来了差异化,提供了一种自适应和安全的方法来维护物联网设备的用户隐私偏好17。
BittWare的能力
二十多年来,BittWare帮助行业专家在其基础设施中引入FPGA来设计、开发和优化工作负载。在这段时间里,BittWare计算和网络解决方案为不同行业的客户提供了竞争优势,包括HPC、金融、基因组学和嵌入式计算。BittWare将硬件、软件和系统设计的专业知识结合起来,指导客户在其产品中寻求FPGA技术的最大利益。
在250加速器系列中,BittWare选择了各种Xilinx UltraScale+器件和PCIe外形尺寸,为存储基础设施架构师提供了完整的解决方案。这些加速器将Xilinx器件的可编程逻辑直接连接到基础设施网络,并通过上一代100GbE和PCIe 3.0高速接口连接PCIe结构。此外,利用BittWare母公司Molex的能力,250系列提供了连接现有硬件的高度灵活性。Molex是超高速低损耗电缆和互连解决方案的行业领导者。

总结
NVMe已经并仍在快速地改变着存储行业。这种新的高吞吐量存储技术为IT基础设施提供了一个灵活的存储解决方案。与上一代存储相比,NVMe不仅提供了卓越的数据写入和读取带宽,它还利用了现有数据中心的PCIe和网络结构。随着NVMe变得越来越流行,行业创新者正在推出支持NVMe的新产品。所有基本的数据中心设备都在更新以支持NVMe;NVMe存储背板现在是新的规范。
基于FPGA的NVMe产品允许计算在硬件层面与存储合并,以达到更高的应用性能。通过FPGA,可重构逻辑的处理通过一个高吞吐量和低延迟的管道直接连接到存储。由于这些特性,数据可以流经FPGA并得到实时处理。此外,通过使用FPGA处理,CPU内核可以自由地执行其他只能在处理器上运行的任务。有了MPSoCs,系统就有了额外的能力,并在设备上结合了高速数据处理和控制,有可能在自主运行。
BittWare基于FPGA和MPSoC的存储产品是针对实际应用的需求而设计的,解决了IT基础设施管理人员的挑战。BittWare通过250产品系列提供了一条通往生产的道路。
参考文献
- McDowell S. (2018).2018年存储行业:对未来一年的预测。福布斯》。2018年6月4日检索,来自:https://www.forbes.com/sites/moorinsights/2018/01/24/storage-industry-2018-predictions-for-the-year-to-come
- Ahmad M. (2017).基于NVM的存储设计中需要关注的四个趋势。电子设计》。2018年6月8日检索,来自:https://www.electronicproducts.com/Computer_Peripherals/Storage/Four_trends_to_watch_in_NVMe_based_storage_designs.aspx
- G2M Research(2018)。G2M Research NVMe Ecosystem Market Sizing Report。G2M Research.于2018年6月6日检索,来自:http://g2minc.com/g2m-research-nvme-ecosystem-market-sizing-report
- Mehta N. (2015).利用UltraScale+产品组合推动性能和集成。Xilinx.2018年6月8日,检索到:https://www.xilinx.com/support/documentation/white_papers/wp471-ultrascale-plus-perf.pdf
- Allen D., & Metz J. (2018a).NVMe的演变和未来。Bright Talk.取自:https://www.brighttalk.com/webcast/12367/290529
- Nuncic (2017).为你的SSD提供更多的速度 - NVME有望在未来取代SATA和SAS。OnTrack.2018年6月8日检索,来自:https://www.ontrack.com/blog/2017/09/15/nvme-replace-sata-sas/
- Adshead A. (2017).存储简报:NVMe vs SATA和SAS。计算机周刊》。2018年6月8日检索,来自:https://www.computerweekly.com/feature/Storage-briefing-NVMe-vs-SATA-and-SAS
- Rollins D. (2017).NVMe PCIe SSD的商业案例。美光公司网站。取自:https://www.micron.com/about/blogs/2017/july/the-business-case-for-nvme-pcie-ssds
- Allen D., & Metz J. (2018b).在NVMe技术的地平线上:关于NVMe的演变和未来的问答网络广播。NVM Express。取自:https://nvmexpress.org/on-the-horizon-for-nvme-technology-qa-on-the-evolution-and-future-of-nvme-webcast/
- MaharanP.(2018).云端SSD定制的NVMe可选功能回顾。希捷博客。取自:https://blog.seagate.com/intelligent/a-review-of-nvme-optional-features-for-cloud-ssd-customization/
- Martin B. (2017).I/O决定论及其对数据中心和超大规模应用的影响。2017年闪存峰会。取自:https://www.flashmemorysummit.com/English/Collaterals/Proceedings/2017/20170808_FB11_Martin.pdf
- Leibso S. (2016).IBM和Nallatech在圣何塞的OpenPOWER峰会上演示了CAPI闪存。Xcell每日博客。2018年6月4日检索,来自:https://forums.xilinx.com/t5/Xcell-Daily-Blog/IBM-and-Nallatech-demo-CAPI-Flash-at-OpenPOWER-Summit-in-San/ba-p/691256
- SakalleyD. (2017).使用FPGA来加速基于NVMe-oF的存储网络。Flash Memory Summit.2018年6月7日检索,来自:https://www.flashmemorysummit.com/English/Collaterals/Proceedings/2017/20170810_FW32_Sakalley.pdf
- Rollins J. D. (n.d.).重做日志文件和备份。维克森林大学。取自:http://users.wfu.edu/rollins/oracle/archive.html
- Wahl M., Hartl D., Lee W., Zhu X., Menezes E., & Tok W. H. (2018).如何使用FPGA进行深度学习推理,在TB级的航空图像上进行土地覆盖测绘。微软博客。
- Teich D. (2018).管理AI:GPU和FPGA,为什么它们对人工智能很重要。福布斯》。取自:https://www.forbes.com/sites/davidteich/2018/06/15/management-ai-gpu-and-fpga-why-they-are-important-for-artificial-intelligence/#6bf2ff171599
- Cha S. C., Chen J. F., Su C., & Yeh K. H. (2018).物联网中基于BLE的设备的区块链连接网关。IEEE访问。取自:https://ieeexplore.ieee.org/document/8274964/
- 阿尔科恩(2017)。2017年热门芯片:我们将在今年看到PCIe 4.0,PCIe 5.0在2019年。汤姆的硬件。2018年6月8日检索,来自:https://www.tomshardware.com/news/pcie-4.0-5.0-pci-sig-specfication,35325.html
- Caulfield L. (2018).Denali项目为云规模的应用定义灵活的SSD。Azure Microsoft。2018年6月6日检索,来自:https://azure.microsoft.com/en-us/blog/project-denali-to-define-flexible-ssds-for-cloud-scale-applications/
- Ismail N. (2017).闪存:改变存储行业。信息时代》。2018年6月4日检索,来自:http://www.information-age.com/flash-storage-transforming-storage-industry-123465174/
- Lusinsky R. (2017).关于RDMA over Converged Ethernet(RoCE)的11个神话。电子设计。2018年6月9日检索,来自:http://www.electronicdesign.com/industrial-automation/11-myths-about-rdma-over-converged-ethernet-roce
- Miller R. (2017).IBM的新Power9芯片是为人工智能和机器学习而建的。Tech Crunch。2018年6月8日检索,来自:https://techcrunch.com/2017/12/05/ibms-new-power9-chip-architected-for-ai-and-machine-learning/
- Peng V. (2015).16纳米UltraScale+系列 作者:Victor Peng,执行副总裁及总经理。赛灵思公司。2018年6月8日,检索到:https://www.xilinx.com/video/fpga/16nm-ultrascale-plus-series.html
- Vaid K.(2018)。微软为数据中心硬件存储和安全创建行业标准。Azure博客。取自:https://azure.microsoft.com/en-us/blog/microsoft-creates-industry-standards-for-datacenter-hardware-storage-and-security/
- 取自:https://blogs.technet.microsoft.com/machinelearning/2018/05/29/how-to-use-fpgas-for-deep-learning-inference-to-perform-land-cover-mapping-on-terabytes-of-aerial-images/