
ホワイトペーパー
FPGAアクセラレーションによるNVMeストレージソリューション
BittWare 250シリーズアクセラレータの使用
概要
近年、NANDフラッシュベースのストレージへの移行とNon-Volatile Memory Express®(NVMe™)の導入により、テクノロジー企業にとって、これまでとは異なる「ストレージのあり方」を模索する機会が倍増しています1。リアルタイムのデジタルビジネスの急速な成長と多様化は、新しい製品やサービスを実現するために、このようなイノベーションを要求しています。
はじめに
近年、NANDフラッシュベースのストレージへの移行とNon-Volatile Memory Express®(NVMe™)の導入により、テクノロジー企業にとって、これまでとは異なる「ストレージのあり方」を模索する機会が倍増しています1。リアルタイムのデジタルビジネスの急速な成長と多様化により、新しい製品やサービスを実現するためのイノベーションが求められています。そのため、新しいストレージ製品は、より高い帯域幅、より低いレイテンシ、フットプリントと総所有コストの削減というトレンドに沿っており、大規模なインフラに依存している企業にとって重要な改善となっています。最近の市場レポート2では、NVMe 市場は年平均成長率約15%で成長し、2020年には570億ドルに達すると予測されています。NVMe市場は進化を続け、3つの領域でさらなる技術革新を追求しています:
- ストレージ仮想化で柔軟性と安全性を高める
- 蓄積されたデータに近い局所的なデータ処理
- 最適化されたインフラストラクチャのための分解されたストレージ3
2018年3月、BittWare 、ストレージ市場のニーズに対応する革新的なソリューションを提供する250シリーズFPGA製品を発表しました。250シリーズ製品は、シングルチップでASICクラスの機能を提供するXilinx®UltraScale+™ FPGAとMPSoCを搭載し、ストレージ業界6 の技術ニーズに適合しています。NVMeとリコンフィギュラブルロジックFPGAおよびMPSoCを組み合わせることで、BittWare 、急速に進化する市場において重要な差別化要因となる新しいクラスのストレージ製品を提供しています。ザイリンクスデバイスの柔軟性と再構成性により、20ベースのソリューションは、NVMe標準が新しい機能を随時取り入れているため、最新の状態を維持できることが保証されています5。
本アプリケーションノートでは、BittWareのFPGAおよびMPSoC対応アクセラレータ製品250シリーズを使用して、次世代IoTおよびクラウドインフラ向けの高性能で拡張性の高いNVMeインフラを構築する方法について説明します。
NVMeロードマップ
2011年にNVMeが誕生して以来、NVMeコンソーシアムは非常に活発な活動を続けています。実は現在、NVMeプロトコルは、別々の仕様で定義された3つの観点から進化しています。基本的なNVMe仕様に加え、NVMe Management Interface(NVMe-MI)は、通信とデバイスの管理方法(デバイスの発見、監視など)を詳述し、NVMe over Fabric(NVMe-oF)は、ネットワーク上の不揮発性ストレージとの通信方法を説明し、プロトコルがトランスポートアグノスティックであると示す9.
時間が経つにつれて、様々な業界のより多くのユーザーがNVMeを採用し始めると、新しいユーザーは新しい機能の必要性を特徴付け、仕様に対する新しいアイデアを導入します。NVMeプロトコルの採用は今も増え続けており、イノベーションを生んでいます。ハードウェアとソフトウェアの企業は、新しいフォームファクタの導入、新しい製品やアプライアンスの作成などを通じて、メモリにアクセスする新しい方法を見つけています。NVMeエコシステムの焦点は、データセンターやハイパースケールインフラに拡張する手段をユーザーに提供することであり、プロトコル仕様はその方向で進化し続けるでしょう9.
2019年には、NVMeの基本仕様のリビジョン1.4がリリースされ、データレイテンシの改善、不揮発性データへの高性能なアクセス、複数のホスト間でのデータ共有の容易さが実現される予定である。NVMeのユーザー、特にクラウドプロバイダーが待ち望んでいる機能の1つが、IOの並列実行時のサービス品質を向上させるIO決定論です10。バックグラウンドのメンテナンスタスクの影響を最小限に抑え、ノイズの多い隣人の影響を抑えることで、IO決定論機能は、不揮発性データへのアクセス時に一貫したレイテンシーをユーザーに提供します。別の方法として、先に述べたOpen Channelアーキテクチャ11がある。この2番目の方法では、ホストが管理機能の一部を引き継ぎ、データのみがストレージハードウェアに転送されます。この構成では、ホストに対するドライブの物理的なインターフェイスは高速データレーンに限られ、サイドバンドチャンネルは存在しない。この例は、NVMe仕様に変更があった場合の影響と関連性を示し、柔軟なNVMeハードウェア・インフラストラクチャの要件を浮き彫りにしています。
今後数カ月でベース、MI、オーバーファブリック仕様の新しい改訂版が登場するため、NVMeユーザーは、新しいNVMe要件に適応できる柔軟な基盤から恩恵を受けることになります。250シリーズFPGAおよびMPSoC製品は、この柔軟性を提供するだけでなく、今日の顧客の課題を解決し、即座に競争上の優位性を得ることができるのです。
なぜFPGAなのか?
BittWareザイリンクスの FPGA および MPSoC 製品は、最新のザイリンクスUltraScale+ テクノロジーを搭載し、NVMe にますます注力するデータセンターのニーズに対応しています。FPGA は、30 年以上にわたって複数の業界にプログラマブルなハードウェアソリューションを提供し、自動車、放送、医療、軍事などの市場でコンピューティングや組み込みシステムの問題解決に広く使用されています。同時に、近年、FPGAメーカーは、この実績ある技術に、最新かつ最高の統合システム設計の改良を導入しています。
ザイリンクスUltraScale+ FPGA および MPSoC 製品は 16nm プロセスを採用し、高速ファブリック、組み込み RAM、クロッキング、および DSP 処理を提供することでシステム性能を向上させています。さらに、ザイリンクス デバイスは、ネットワークまたは PCIe ファブリックへのより高いスループットの接続のために、より高速なトランシーバ テクノロジー (最大 32.75 Gb/s) を導入しました。UltraScale+製品は、シリアルトランシーバーのチャンネル数が多いため、一度に複数のPCIeインターフェースに接続し、ホストCPUにデータオフロードインターフェースを提供することができます。PLXスイッチをFPGAやMPSoCに置き換えることで、CPUが処理の一部をオフロードし、他の処理にあてることができるケースもあります。また、FPGAやMPSoCのプログラマブル・ロジックは、システムにおいて決定論的で低遅延なインターフェイスを提供し、一部のユースケースにおいて明確な競争優位性をもたらすことができる。
最近のFPGAファミリーは、デバイス・ファブリック内に低消費電力のマイクロプロセッサを内蔵するようになりました。UltraScale+ MPSoC は、プログラマブル ロジックだけでなくソフトウェアも必要とするアプリケーションのニーズに応え、これらを 1 つのパッケージに統合しています。例えば、Xilinx ZynqUltraScale+ ZU19EG は、ハイブリッド コンピューティングのニーズがあるアプリケーション向けに、クアッドコア ARM Cortex-A53 とリアルタイム デュアルコア ARM Cortex-R5 の 2 つの処理ユニットに加え、グラフィック処理ユニット ARM Mali™-400 MP2 を備えています。ZU19EG MPSoCデバイスは、プログラマブル・ロジックがストレージ・データに低レイテンシの決定性パスを提供し、ARMコアが複雑なパケット制御を実行したり、CPUレス組み込みシステムでホストCPUを置き換えたりするNVMe over FabricまたはOpen Channelの実装に特に適した非常に汎用性の高いチップとなります。
ここ数年、BittWare はストレージ業界の最前線に立ち続け、NVMe テクノロジーに基づく製品を開発することでその革新的な成長に貢献してきました。BittWare は、FPGA が I/O ボトルネックを減らし、NVMe ソリッドステートドライブに直接高速決定性パスを提供できることを認識しました。早くも2015年には、BittWare 、XilinxおよびIBMと提携し、革新的なNoSQLデータベースソリューションを開発しました12。250シリーズFPGA&MPSoCボードは、この初期製品の成功に基づき、より深く高速なオンボードメモリ、ネットワーク接続、システムオンチップ、サーバーストレージバックプレーンへのケーブル接続オプションなどの機能を追加しています。
空の見出し
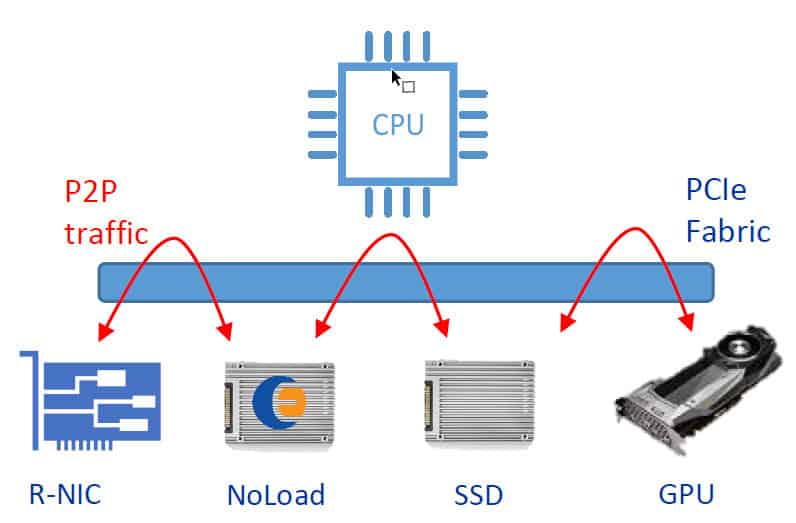
250 FPGA & MPSoC製品シリーズ
250 FPGA & MPSoC製品ラインは、250S+、250-U2、250-SoCの3つのFPGAアダプタで構成され、PCIeスロット、OCuLink/Nano-Pitch、SlimSAS、MiniSAS HD、U.2ストレージバックプレーンなどのさまざまな業界標準フォームファクターに接続します。250シリーズ製品は、既存のインフラストラクチャのPCIeファブリックにぴったりとフィットし、NVMeストレージデバイスに低レイテンシーで直接アクセスすることができます。
250S+直付けアクセラレータ
シリーズの最初のアクセラレータは、250S+です。このFPGAアクセラレータは、XilinxUltraScale+ Kintex 15P FPGAと、ロープロファイル8レーンのハーフハイトハーフレングスPCIe準拠のフォームファクタに4つのオンボード1TB M.2 NVMeドライブ(合計4TBの不揮発性フラッシュ)を備えています。また、システムにFPGAコンピューティングを導入したいだけで、すでにストレージを用意しているお客様には、M.2オンボードコネクタから、Molex低損失高速ケーブル技術を使用して、OCuLink/Nano-Pitch またはMiniSAS HD NVMeバックプレーンへケーブル出力することができます。KU15P FPGAは、1,143Kシステムロジックセル、1,968DSPスライス、70.6Mbの組み込みメモリを備え、UltraScale+ Kintex FPGAシリーズで最大のデバイスで、付加価値機能を実装するための大量の設定可能リソースを提供します。オンボードのDDR4メモリバンクにより、より深いデータベクタのバッファリングを追加することができます。


- 最大4台のM.2 NMVe SSDをオンカードでザイリンクスFPGAに結合可能
- OCuLink 250S+を大規模なストレージアレイの一部として使用できるブレイクアウトケーブリング
DAA(Directly Attached Accelerator)とは?
- NVMeストレージを仮想化し、複数の仮想マシンで共有する。
- ホストCPUとNVMe SSDの間でNVMeストレージを分離し、セキュリティを高める。
- 250S+ & 250-SoC
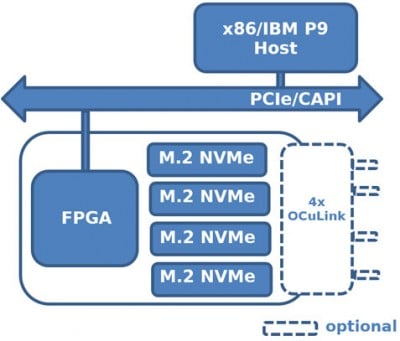
250-U2 プロキシ インラインアクセラレータ
250シリーズの第2弾は、250-U2です。このアクセラレータボードは、XilinxUltraScale+ Kintex 15P FPGA (250S+ と同じ) と DDR4 メモリの 1 バンクを 2.5 インチ U.2 ドライブフォームファクタに搭載しています。250S+とは異なり、250-U2にはFPGAに直接接続されたオンボードSSDはありません。このアクセラレータの斬新な設計により、専用のPCIeスロットがないシステムでも、既存の標準的なU.2 NVMeストレージの隣にある追加の計算能力を持つU.2ストレージバックプレーンにフィットすることができます。この250-U2製品は、Proxy In-Line Accelerator (PIA)の役割を担っています。

250-U2は、インライン圧縮、暗号化、ハッシュのほか、消去符号化、重複排除、文字列/画像検索、データベースのソート/結合/フィルタなど、より複雑な機能を実行できます。アプリケーションのコンピューティング・ニーズに応じて、バックプレーン集団はNVMeドライブ用の250-U2ボードの比率を変えて表示することになる。250-U2は、ストレージと並んでU.2バックプレーンに配置され、NVMe-MI仕様を活用した他の標準U.2 NVMeドライブと同じメンテナンスオプションを備えています。250-U2プロセッシング・ノードとストレージの両方がホスト・サーバーのPCIeファブリックに直接接続するため、DMAデータ・トラフィックはCPUとグローバル・メモリを完全にバイパスし、SPDKなどの技術を使用してエンドポイントからエンドポイントへのデータ転送を最適化することができます。RDMAまたはピアツーピアDMAソリューションでは、データはCPUを完全にバイパスしてNVMeエンドポイント間で直接流れます。FPGAやMPSoCのプログラマブル・ロジックに直接接続することで、アクセス・レイテンシーを大幅に削減できます(Lusinsky, 201721)。また、このハードウェア・プラットフォームの別の使用例として、オフロード・コンピュート・エンジンがあり、FPGAaaSのスケーラブルなインフラストラクチャにうまく適合するでしょう。
プロキシインラインアクセラレータ(PIA)
- ローカルのNVMeストレージデータに対して、低レイテンシーかつ広帯域の処理を実行する。
- 複数のホストフォームファクタ 8レーンPCIeアダプタまたは2.5インチU.2
- 250S+ & 250-U2
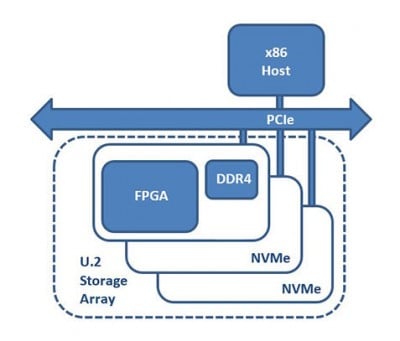
NVMe-over-Fabricに対応した250-SoC。
シリーズ3番目のアクセラレータである250-SoCは、XilinxUltraScale+ Zynq 19EG MPSoCを搭載し、2つのQSFP28ポート(100GbE対応25Gbpsラインレート)によるネットワークファブリックと16レーンのPCIe 3.0 Host Interfaceと4つの8レーンOCuLink コネクタによるPCIeファブリックの両方に接続することができます。ZU19EGは、1,143Kシステムロジックセル、1,968 DSPスライス、70.6 Mbの組み込みメモリを搭載したシリーズ最大のデバイスです。デバイス・パッケージに組み込まれたARMプロセッシング・ユニットとグラフィカル・ユニットは、ハイブリッドなプロセッシングを必要とする製品に理想的なプラットフォームを作り出します。
250-SoCは、ネットワークからストレージに直接アクセスできる汎用性の高いハードウェアで、NVMe-over-Fabricをサポートしています。NVMe-oFは、ネットワークファブリック上でストレージを分解し、ストレージをリモートで管理するための次世代NVMeプロトコルです。NVMe-oFはまた、SASよりも柔軟性を高め、オンデマンドでネットワークアレイを設定することができます。分散型ストレージやEJBOF(Ethernet Just-a-Bunch-Of-Flash) ハードウェアは、データセンター内のストレージコスト、フットプリント、電力を削減します。
ザイリンクス Zynq MPSoC チップは、組み込みシステム向けにさらなる柔軟性を提供します。MPSoCボードは、ホストCPUから独立してオペレーティングシステムとそのフルソフトウェアスタックを実行することができます。最大2つの100GbEポートをサポートする高帯域幅ネットワーク機能とオンボードMPSoCにより、250-SoCは、NVMe-oFアプリケーションのための外部ネットワークインターフェースカード(NIC)と外部プロセッサの両方の必要性を排除しています13。FPGAベースのNVMe-oFインフラの実装は、データがハードウェアパスを通過するだけなので、シンプルかつ高性能であり、低遅延で予測可能なソリューションとなります。
NVMe-over-Fabric(NVMEoF)」。
- データセンターのネットワークファブリック上でNVMeフレームを低レイテンシーかつ高スループットで伝送する。
- 250-SoC
250-SoCは、ストレージ業界に柔軟なソリューションの数々を提供します。250S+と250-SoCは、Direct Attached Acceleratorのユースケースをターゲットにすることで、仮想化とセキュリティ強化の必要性に取り組んでいます。250-U2と250S+は、Proxy In-Line Acceleratorとして既存のインフラに簡単にプラグインでき、NVMeストレージに低レイテンシーと高帯域幅のローカルデータコンピュートを提供します。さらに、250SoCは、最新世代のNVMeプロトコルをサポートしながら、ストレージを分離するハードウェアのみの革新的な方法として、NVMe-over-Fabricをサポートしています。NVMe市場が成長を続ける中、FPGAとMPSoCのソリューションは、NVMe製品のアプリケーションの課題を解決してくれるでしょう。
NVMeアプリケーション
NVMeテクノロジーは、ストレージに破壊的なイノベーションをもたらし、データセンターのインフラに広範囲な影響を及ぼしています。このプロトコルの特徴により、NVMeはストレージに関わる新しい製品やアプリケーションを設計する際に、第一の選択肢となります。
データベース(アクセラレーション )などのエンタープライズ・アプリケーションでは、低レイテンシと高帯域幅の4Kまたは8Kデータ書き込み転送速度が求められますが、この2つの要件はNVMeプロトコルの長所に完全に適合しています。このような特性から、NVMeはREDOログの実装に適しています。例えば、多くのトランザクション記録が保存され、データベースが故障した場合に将来再生されるようなユースケースです。このユースケースにおいて、250S+は最大4TBのNVMeストレージをFPGAリコンフィギュラブル・ファブリックの端に直接持ち込み、トランザクション記録を高速でSSDに集め、再生に備えます14。
NVMeはまた、仮想化インフラの課題を軽減し、IOが最も一般的なボトルネックであるVM(仮想マシン)、ステートレスVM、SRIOVの実装を簡素化します。ステートレスVMの使用例では、IT管理者は、企業ユーザーが変更しないOSイメージをロックダウンする必要があります。ユーザーは自分のデータだけを変更し、OSイメージはNVMeストレージで変更されないままである。このようなITインフラでは、NVMeストレージは複数のユーザー間で共有されます。250S+は、このアプリケーションを実現するためのオールインワン・プラットフォームです。各1TBの物理ドライブはFPGA IPによって分割され、各ユーザーはOSイメージとデータへの分離された安全なアクセスを得ることができます。ハイパーバイザーは、エミュレーションドライバを使用せずに、ドライブの一部への直接アクセスを管理し、このIO制限のあるアプリケーションに優れた性能を提供します。
ビッグデータ」市場は、バッチ処理からリアルタイム処理へと移行しているため、ストレージと処理を組み合わせたインテリジェントなNVMe製品にも機会をもたらしています。Map Redの問題は、バッチ処理ではなく、リアルタイム分析に移行しているため、GFSバックエンドよりもはるかに高速な新しいストレージ階層が必要です。現在ITインフラで見られるストレージの階層化は、ほとんどアクセスされない低速のコールドストレージと、非常に高速なSSD、NVMe、NVMメモリに分けられます。このユースケースでは、すべてのデータはGDFSに記録されますが、その後、より高速なメモリを持つコンピュートノードに移動されます。NVMe-over-Fabricを実装した250-SoCは、高速ストレージと高性能なコンピュート機能へのアクセスを提供するため、これらの両方の要件に対応します。
ディープラーニング業界は、アナリティクスの世界と同様のニーズを持っています。深層学習用の新世代アクセラレータ、すなわちGPGPU、TPU、FPGA;これらのデバイスは、チップの計算能力に見合った大きなメモリ帯域幅を必要とします。学習演算は、この高スループットのデータを大量に消費し、数テラバイトになることも少なくありません15。最近の研究では、FPGAファブリックを使用することで、特定のネットワークタイプのトレーニングオペレーションを高速化できることが示されています。したがって、ストレージと計算エンジンの両方を1つのハードウェアプラットフォームに統合することで、待ち時間を短縮し、トレーニングデータセットが増加しても再トレーニングのサイクルを増やすことができます16。
HPC分野では、250S+のローカルストレージや250-SoCのリモートバージョンは、チェックポイント/再起動、バーストバッファ、分散ファイルシステム、スケジューラからのジョブデータのキャッシュなど、いくつかの用途があります。FPGAファブリック上のストレージの近くでアルゴリズムを実行することで、FPGAアプリケーションのフットプリントは低いまま、ストレージをフル活用し、CPUを他の処理ジョブのために空けておくことができます。ギガバイトのデータが揮発性メモリに保持されているが、定期的にフラッシュにバックアップする必要があるインメモリデータベースでは、単にデータを保存したり、ホストCPUを使用して圧縮や暗号化を行う代わりに、FPGAベースのシステムがこれらのデータを処理します。FPGAベースのシステムは、このようなデータのスナップショットを処理して、大容量のNVMeベースのストレージ・アレイに永久保存することができます。このような運用では、MPSoCはユーザーデータに対してより複雑な処理を行うのに特に適しています。
最後に、IoT空間では、集約が行われるIoTゲートウェイでのデータのフィルタリングや前処理、また受信後のデータに対する暗号化のニーズがあり、FPGAはリアルタイムでデータのストリームを暗号化や圧縮などのビット演算で処理し、250S+を使ってデータをオンボードで離れて保存するか、ケーブル付きの250S+や250-SoCを使って入力帯域でストレージバックプレーンに渡します。FPGAは、ブロックチェーン計算から選ばれるプラットフォームでもあります。ブロックチェーン技術は、IoTゲートウェイに差別化をもたらし、IoTデバイスのユーザープライバシー設定を維持するための適応的で安全な方法を提供します17。
BittWare'sの実力
BittWare は、20 年以上にわたって、業界の専門家が FPGA をインフラに導入してワークロードを設計、開発、最適化するのを支援してきました。この間、BittWare Compute and Network ソリューションは、HPC、金融、ゲノム、組み込みコンピューティングなど様々な業界のお客様に競争力を提供してきました。BittWare は、ハードウェア、ソフトウェア、システム設計の専門知識を組み合わせ、自社製品で FPGA 技術のメリットを最大化することを目指すお客様をご案内しています。
250-accelerator シリーズでは、BittWare がザイリンクスUltraScale+ デバイスと PCIe フォームファクターを選択し、ストレージインフラストラクチャアーキテクトに完全なソリューションを提供しています。これらのアクセラレータは、ザイリンクスデバイスのプログラマブルロジックをインフラストラクチャーネットワークに直接接続し、前世代の100GbEおよびPCIe 3.0高速インターフェイスを通じてPCIeファブリックに接続します。さらに、BittWare の親会社であるモレックスの能力を利用し、250 シリーズは既存のハードウェアを接続する高い柔軟性を提供します。モレックスは、超高速低損失ケーブルと相互接続ソリューションの業界リーダーです。

結論
NVMeは、これまでも、そして今も、急速なスピードでストレージ業界を変革しています。この新しい高スループット・ストレージ・テクノロジーは、ITインフラストラクチャに柔軟なストレージ・ソリューションを提供します。NVMeは、前世代のストレージと比較して、データの書き込みと読み取りの帯域幅が優れているだけでなく、既存のデータセンターの現在のPCIeとネットワークファブリックを活用することができます。NVMeの普及に伴い、業界のイノベーターはNVMeをサポートする新製品を発表しています。基本的なデータセンター機器はすべてNVMeをサポートするように更新されており、NVMeストレージバックプレーンは今や新しい標準となっています。
NVMe用のFPGAベースの製品は、コンピュートとストレージをハードウェア・レベルで融合させ、より高いアプリケーション性能に到達させることができます。FPGAでは、再構成可能なロジックの処理が、高スループットと低レイテンシのパイプを通じてストレージに直接接続されます。このような特性から、データはFPGAの中を流れ、リアルタイムで処理されることができます。さらに、FPGAの処理を利用することで、CPUコアはプロセッサでしか実行できない他のタスクの実行に自由に使えるようになる。MPSoCでは、システムにさらなる機能を持たせ、高速データ処理と制御をデバイス上で組み合わせ、自律的に動作させることができる可能性があります。
BittWare FPGAとMPSoCベースのストレージ製品は、実際のアプリケーションのニーズをターゲットとし、ITインフラ管理者の課題を解決するために設計されています。BittWare 、250製品シリーズで生産へのパスを提供します。
参考文献
- マクダウェル S. (2018).ストレージ業界2018年版:来たるべき年の予測。Forbes.2018年6月4日、以下より取得: https://www.forbes.com/sites/moorinsights/2018/01/24/storage-industry-2018-predictions-for-the-year-to-come
- Ahmad M. (2017).NVMeベースのストレージ設計で注目すべき4つのトレンド。エレクトロニック・デザインズ。2018年6月8日、https://www.electronicproducts.com/Computer_Peripherals/Storage/Four_trends_to_watch_in_NVMe_based_storage_designs.aspx から取得しました。
- G2M Research (2018).G2M Research NVMe Ecosystem Market Sizing Report.G2Mリサーチ.2018年6月6日、http://g2minc.com/g2m-research-nvme-ecosystem-market-sizing-report から取得しました。
- Mehta N. (2015).UltraScale+ ポートフォリオでパフォーマンスと統合を推し進める。Xilinx.2018年6月8日取得、https://www.xilinx.com/support/documentation/white_papers/wp471-ultrascale-plus-perf.pdf から。
- アレンD.、&メッツJ. (2018a).NVMeの進化と未来。ブライトトーク。取得元:https://www.brighttalk.com/webcast/12367/290529
- ンチック(2017年)。SSDをもっと高速に - NVMEが将来SATAやSASを置き換えると予想される。OnTrack.2018年6月8日、https://www.ontrack.com/blog/2017/09/15/nvme-replace-sata-sas/ から取得しました。
- アドスヘッドA. (2017).ストレージのブリーフィング:NVMe vs SATAとSAS。Computer Weekly.2018年6月8日、https://www.computerweekly.com/feature/Storage-briefing-NVMe-vs-SATA-and-SAS から取得しました。
- ロリンズD. (2017).NVMe PCIe SSDのビジネスケース.マイクロン社ウェブサイト。取得元:https://www.micron.com/about/blogs/2017/july/the-business-case-for-nvme-pcie-ssds
- アレンD.、&メッツJ.(2018b)。NVMe テクノロジーの地平線上に:NVMeの進化と未来に関するQ&A Webcast.NVM Express.取得元:https://nvmexpress.org/on-the-horizon-for-nvme-technology-qa-on-the-evolution-and-future-of-nvme-webcast/
- MaharanP.(2018).クラウドSSDカスタマイズのためのNVMeオプション機能のレビュー。シーゲイト・ブログ.取得元:https://blog.seagate.com/intelligent/a-review-of-nvme-optional-features-for-cloud-ssd-customization/
- マーティン・B. (2017).I/O Determinism and Its Impact on Datacenters and Hyperscale Applications.フラッシュメモリーサミット2017.取得元:https://www.flashmemorysummit.com/English/Collaterals/Proceedings/2017/20170808_FB11_Martin.pdf
- Leibso S. (2016).IBMとNallatech、サンノゼのOpenPOWER SummitでCAPI Flashのデモを実施。Xcellデイリーブログ。2018年6月4日、https://forums.xilinx.com/t5/Xcell-Daily-Blog/IBM-and-Nallatech-demo-CAPI-Flash-at-OpenPOWER-Summit-in-San/ba-p/691256 から取得しました。
- SakalleyD. (2017).FPGAを使用してNVMe-oFベースのストレージネットワークを高速化する。フラッシュメモリーサミット.2018年6月7日、以下から取得: https://www.flashmemorysummit.com/English/Collaterals/Proceedings/2017/20170810_FW32_Sakalley.pdf
- ロリンズ J. D. (n.d.).Redo Log Files and Backups.ウェイクフォレスト大学。取得元:http://users.wfu.edu/rollins/oracle/archive.html
- Wahl M., Hartl D., Lee W., Zhu X., Menezes E., & Tok W. H. (2018).テラバイトの航空画像で土地被覆マッピングを実行するためのディープラーニング推論にFPGAを使用する方法。マイクロソフトのブログ。
- テイチD. (2018).マネジメントAI:GPUとFPGA、それらが人工知能にとって重要な理由.フォーブス取得元:https://www.forbes.com/sites/davidteich/2018/06/15/management-ai-gpu-and-fpga-why-they-are-important-for-artificial-intelligence/#6bf2ff171599
- Cha S. C., Chen J. F., Su C., & Yeh K. H. (2018).モノのインターネットにおけるBLEベースのデバイスのためのブロックチェーン・コネクテッド・ゲートウェイ。IEEE アクセス。取得元:https://ieeexplore.ieee.org/document/8274964/
- アルコーン(2017年)。ホットチップス2017:We'll see PCIe 4.0 This Year, PCIe 5.0 In 2019.トムズハードウェア.2018年6月8日、以下から取得: https://www.tomshardware.com/news/pcie-4.0-5.0-pci-sig-specfication,35325.html
- Caulfield L. (2018).クラウドスケールアプリケーション向けの柔軟なSSDを定義するプロジェクトDenali。Azure Microsoft.2018年6月6日、https://azure.microsoft.com/en-us/blog/project-denali-to-define-flexible-ssds-for-cloud-scale-applications/ から取得しました。
- イスマイル・N. (2017).フラッシュストレージ:ストレージ業界を変革する。インフォメーションエイジ2018年6月4日、http://www.information-age.com/flash-storage-transforming-storage-industry-123465174/ から取得しました。
- Lusinsky R. (2017).RDMA over Converged Ethernet (RoCE)に関する11の神話。エレクトロニック・デザイン。2018年6月9日、http://www.electronicdesign.com/industrial-automation/11-myths-about-rdma-over-converged-ethernet-roce から取得しました。
- ミラー・R. (2017).IBMの新しいPower9チップは、AIと機械学習のために作られた。Tech Crunch.2018年6月8日、https://techcrunch.com/2017/12/05/ibms-new-power9-chip-architected-for-ai-and-machine-learning/ から取得しました。
- Peng V. (2015).16nmUltraScale+ Series by Victor Peng, EVP & GM.Xilinx.2018年6月8日、以下より取得: https://www.xilinx.com/video/fpga/16nm-ultrascale-plus-series.html
- ヴァイド・K. (2018).Microsoft、データセンターのハードウェアストレージとセキュリティの業界標準を作成。Azure ブログ。取得元:https://azure.microsoft.com/en-us/blog/microsoft-creates-industry-standards-for-datacenter-hardware-storage-and-security/
- 取得元:https://blogs.technet.microsoft.com/machinelearning/2018/05/29/how-to-use-fpgas-for-deep-learning-inference-to-perform-land-cover-mapping-on-terabytes-of-aerial-images/