
ホワイトペーパー
BittWare FPGAソリューションによるNVMeオーバーファブリックの構築
概要
Non-Volatile Memory Express(またはNVMe)プロトコルの導入以来、データセンターの顧客は、ストレージアプリケーションに高い性能と低遅延をもたらすこの新しい技術を広く採用しています(Gupta、2018)。NVMeの機能セットにより、この技術は市場で最も急成長しているストレージソリューションとなりました。2021年までに、International Data Corporationは、NVMeベースのストレージソリューションが、プライマリ外付けストレージの出荷に関連する収益の50%以上を生み出すと予測しています(Burgener、2019年)。
BittWare は、基本的なハードウェアオフロード(圧縮、重複排除など)に加え、推論にFPGAを使用する機械学習アプリケーションなどのアプリケーション固有のアルゴリズムを実装するFPGAアクセラレーション ソリューションを提供します。このように、NVMeにマッチした性能レベルのストレージの基本的なものと高度なものアクセラレーション をミックスしたものを、私たちはコンピュテーショナル・ストレージ(Computational Storage)と呼んでいます。250S+、250-SoC、250-U2など、当社の250シリーズは、この市場に焦点を当てた製品です。
最近、NVMeコンソーシアムは、既存のネットワークインフラ上でNVMeの利点を活用するために、NVMe over Fabrics(NVMe-oF)というプロトコルの変種を発表しました。データセンターではオンプレミスのNVMeストレージの拡大が続いているため、リモート・ユーザーはNVMe-oFを使用して、オーバーヘッドがほとんどない状態で、分割されたストレージにアクセスできます(Gibb、2018)。この場合、低レイテンシーと高帯域幅というNVMeの利点を維持するために、専用のネットワークスタックをハードウェアで実装する必要があります。
私たちのソリューションは、オンチップのARMプロセッサを搭載したFPGA、Xilinx Zynq MPSoCを250-SoCボードで使用しています。FPGAはNVMe-oFコントローラとして機能し、CPUからオフロードしたり、オンチップ・プロセッサを使用する場合はCPUから切り離されます。ネットワーク・プロトコル・スタックを含むFGPAロジックにNVMeデータプレーンを完全に実装することで、低レイテンシーと高帯域を実現しています。ARMコアは、レイテンシと帯域幅があまり問題にならないソフトウェアを使用して制御プレーンを処理するための設計になっています。このアプリケーションノートでは、BittWare 250-SoCをJBOFのNVMe-oFコントローラとして構成する方法について説明します。
NVMe Over Fabricsとは
NVMe-oFプロトコルは、高速SSDの技術を利用し、ローカルサーバーやデータセンターの枠を超えて拡張する。
NVMe-oFにより、アプリケーション開発者は、ファイバーチャネル、InfiniBand、RDMA(Remote Direct Memory Access)over Converged Ethernet(RoCE)、iWARP、最近ではTCP/IPなどのネットワークファブリック上のリモートストレージノードに、レイテンシ(通常、NVMeドライブ100台のクラスタで10usから大規模クラスタで100追加マイクロ秒の間)を低く抑えながらアクセスできる。要するに、NVMe-oFトランザクションはホストとターゲットを含み、ターゲットはホストサーバーがアクセスできるようにネットワーク全体でNVMeブロックストレージデバイスを公開するサーバーです(Davis、2018)。RDMAを使用すると、ホストとターゲットのデータ転送は、CPUがトランザクションを処理することなく行うことができます。代わりに、専用のRNICが、NICのハードウェアの一部がネットワークスタックのトランスポート層を管理するため、コンピューティングリソースへの影響が少ない状態でリソース間のデータ転送を行います。
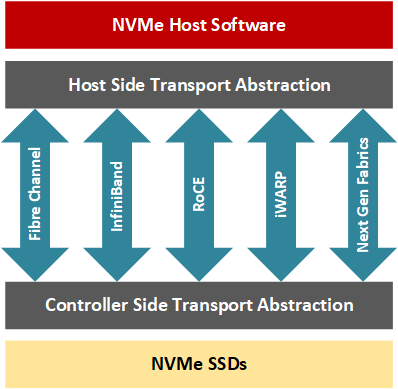
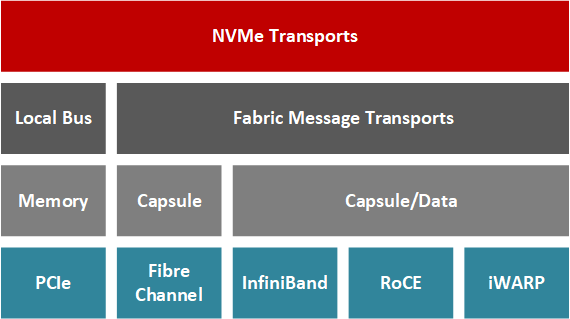
NVMe-oFにFPGAを使用する理由とは?
NVMe-OFをPCIeカードにオフロードする場合、基本的に3つの選択肢があります:
まず、ASICの実装を使用することができます。これは、最も低コストで低レイテンシーの選択でしょう。しかし、ASICでは、「計算ストレージ」アルゴリズムをオフロードすることはできません。また、ASICは一般的に最も普及しているネットワーク帯域幅にしか対応しておらず、最高帯域幅になることはほとんどありません。
2つ目は、コア数の多いシステムオンチップを使うことで、「計算記憶」のアルゴリズムを追加することができることです。ただし、そのためには並列プログラミングのスキルが必要です。究極のソリューションは、一般に、ここで選択した中で最もレイテンシが高く、NVMeの低レイテンシの価値提案に直接反することになります。ASICのように、これらのMPP SOCは一般的に、最も一般的なネットワーク帯域幅にのみ利用可能で、最高帯域幅になることはほとんどありません。
3つ目は、FPGAを使うことです。このオプションでは、ASICのようなレイテンシーを維持したまま、「計算記憶」アルゴリズムを追加することができます。また、このオプションでは、100Gbや400Gbといった広帯域のネットワークが可能になります。3つのオプションの中で最も高価かもしれませんが、ストレージ市場に関わるボリュームを考慮すると、コストの差はわずかなものになります。
アダプティブストレージ
データセンター設計者は、FPGA や SoC などの技術を活用することで、データ集約型の業務において、CPU との間のデータ移動をさらに減らすことができます。ハードウェア駆動型アクセラレーション では、ユーザーアプリケーションはより高いパフォーマンスと低い応答時間を示します。CPU の空きサイクル数が増加すると、ワークロードを分散するプロセスは、専用ハードウェアと CPU を使用するハイブリッド システム アーキテクチャをより効率的に活用することができます。FPGA ファブリックアーキテクチャ,IO スループット,プログラミングの柔軟性により,高帯域幅 NVMe ストレージと緊密に結合した再構成可能なハードウェアの設計が容易になっています.FPGAは、例えば、圧縮、暗号化、RAIDと消去コード、データ重複排除、キーバリューオフロード、データベースクエリーオフロード、ビデオ処理、またはNVMe仮想化などに特に適しています。FPGAハードウェアは、専用ソリューションの性能を提供するだけでなく、データセンターのニーズが長期的に変化した場合に、素早く目的を切り替えて再構成できる利点もあります。
NVMe-oF ターゲットにザイリンクス MPSoC を使用する。
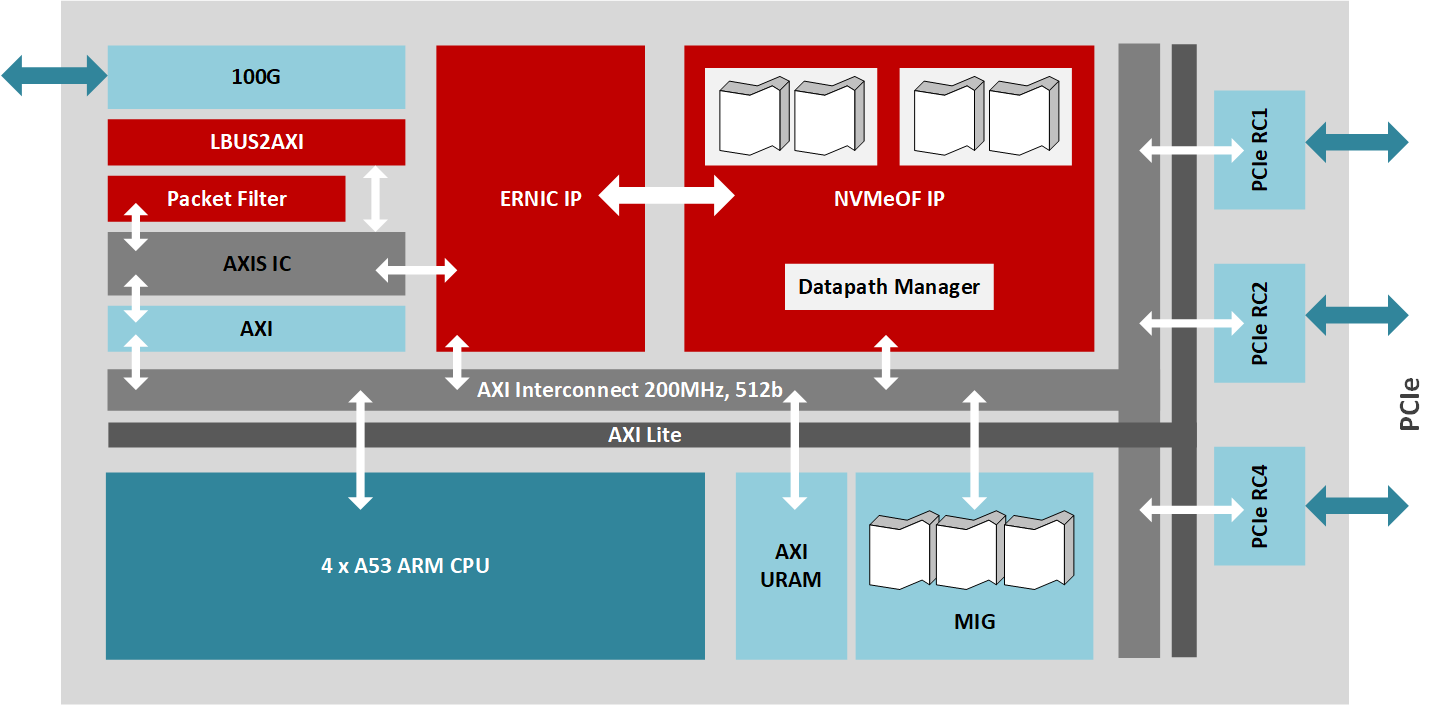
BittWare 250-SoC は、ザイリンクスUltraScale+ Zynq ZU19EG MPSoC を搭載し、2 つの QSFP28 ポートによるネットワーク ファブリックと 16 レーンのホスト インターフェイスまたは 4 つの 8 レーンOCuLink コネクタによる PCIe ファブリックの両方に接続することができます。このMPSoCアダプタは、FPGAファブリック(PL(Programmable Logic)とも呼ばれる)のデータストリーム演算、ネットワークIO、PCIe接続、オンボードARMプロセッサを兼ね備えており、NVMe-oFターゲットノードを駆動するには最適なプラットフォームです。ARMはデータプレーンではなく、コントロールプレーンを処理することに注意してください。CPUとストレージのエンドポイントの間に専用のハードウェアアクセラレータを配置することで、よりデータに近いところで計算するよう最適化されたシステムが実現します。
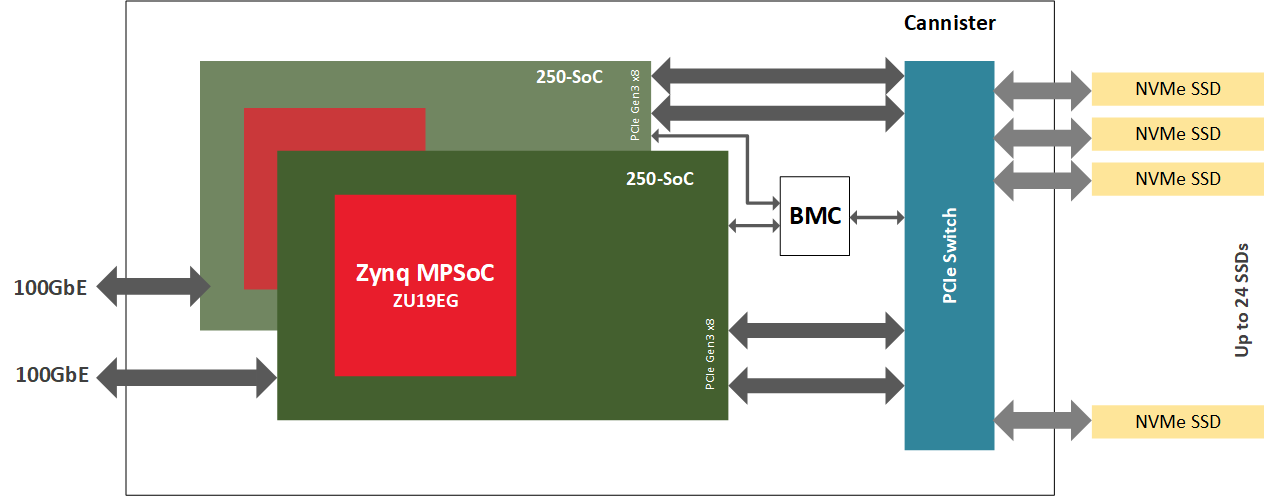
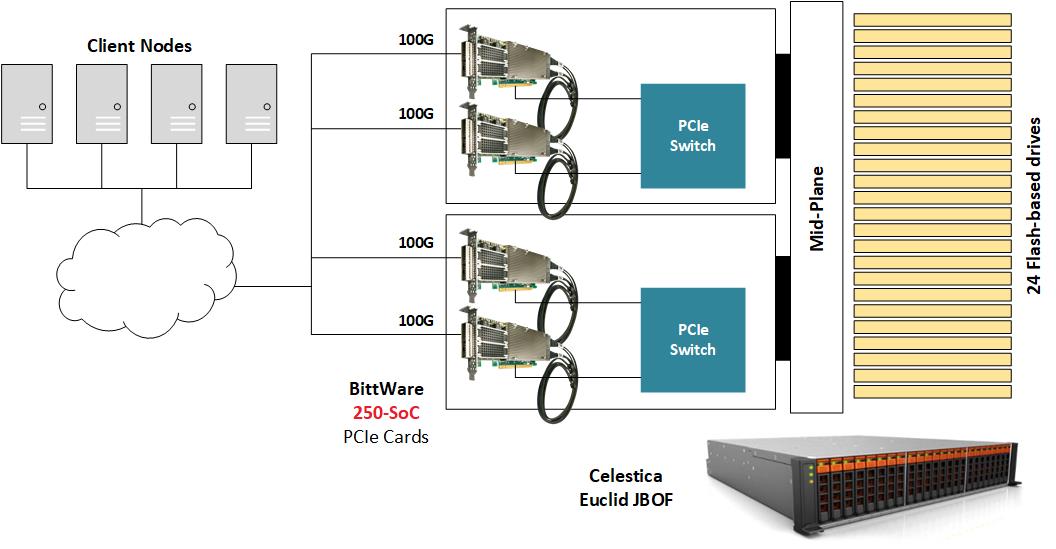
ハードウェア
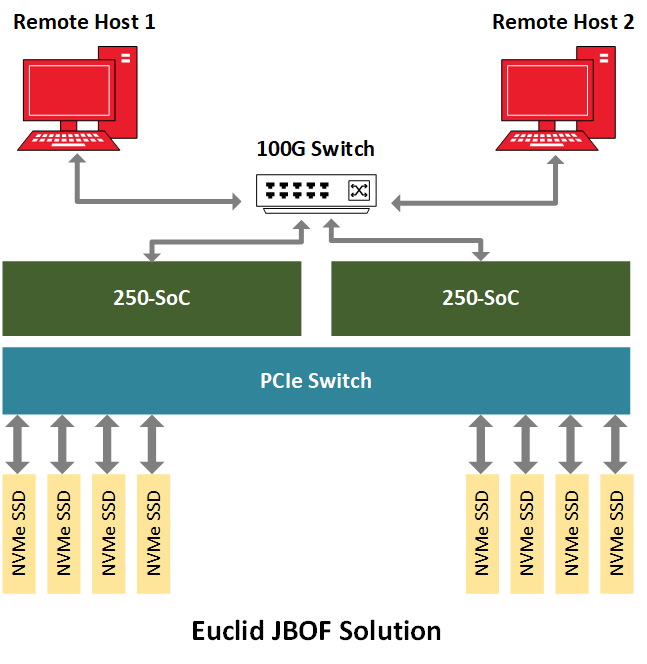
NVMe-oFを実証するために、BittWare 、250-SoCを複数のNVMe U.2ドライブを搭載したJBOF(Just A-Bunch-Of-Flash) シャーシ内に置き、250-SoCボードのQSFP28ポートをネットワークに露出させています。Celestica Euclid JBOFは、PCIeスイッチとPCIeスロットを備えた2つのプラグインブレードを備えており、各ドロワーはネットワークファブリックとNVMeストレージの間のコンジットとして機能します。NVMeパケットは、QSFP28ポートからFPGAファブリックを経由し、PCIeホストインターフェイス、JBOFのPCIeスイッチを経て、最終的にNVMeドライブに到達します。この実装では、250-SoCのOCuLink コネクタは使用されていませんが、別のハードウェアプラットフォームでは、PCIeトランザクションがケーブル上で実行されるこの設計のケーブル化バージョンに対応することができます。
ザ・ゲートウェア
このデザインは、RoCE v2 (NVMe 1.2 および NVMe-oF 1.0 仕様準拠) の NVMe-oF ターゲットを実装し、明示的な輻輳管理をサポートしています。MPSoC をターゲットとする IP は、複数のザイリンクス IP ライブラリ ブロックを使用し、データ プレーンに 200MHz で動作する 512 ビット AXI バスを介して相互接続されています。ザイリンクスのEmbedded RDMA NICが100Gb/sのネットワークトラフィックを処理し、PCIe root complex IPコアが16レーンのPCIe 3.0インターフェイスと最大24台のドライブを駆動するJBOF回路への接続を管理し、DMAコアがAXIバス上の高速データ転送を制御しています。さらに、NVMe-oFターゲットコアは、100Gb/sのデータパス上で最大256のキューを管理し、クアッドコアのA53 ARMプロセッサで動作するファームウェアがストレージノードのハイレベルな管理を担当します。
パフォーマンスの最大化
MPSoC PLは、データパスの最大帯域幅に対応することができます。したがって、システム全体の能力を最大限に発揮するためには、ホストができるだけ100Gb/sに近いネットワークトラフィックを生成する必要があります。ベンチマークでは、数台のNVMe-oFホストがネットワークスイッチに接続し、JBOFのNVMe-oFターゲットを実行する250-SoC MPSoCカードに最大データスループットを供給することができます。このリファレンスデザインでは、約2.5MIOPSのランダムリード性能と約1.1Mのランダムライト性能を示し、アプリケーションレイテンシは105usとなっています。
リコンフィギュラブル・ハードウェア・ソリューションの利点
MPSoCベースのNVMe-oFソリューションは、ソフトウェア(CPU+外部NIC+SPDK)やRNICソリューション(CPU+統合NIC)と比較して、いくつかの利点があります。MPSoCベースのソリューションが他の製品と比べて比較的高いコストと消費電力を持つ場合、このような技術は帯域幅、構成性、レイテンシの観点から競合他社を凌駕します。同様に、RNICソリューションに対して、MPSoCのNVMe-oFはネットワーク・インターフェイスのスループットを飽和させます。しかし、MPSoCのハードウェア実装は、他のソリューションにはないレベルの柔軟性と適応性を備えています。そのため、この適応性の高いハードウェアは、ドメイン固有のアプリケーションをターゲットにすることができ、システム設計者は、顧客定義の機能(RAID、または仕様の進化に伴う新しいNVMe機能)を主要IPに組み合わせ、システム全体の機能セットを強化することができます。また、暗号化や圧縮などのカスタム・アクセラレータを追加して、2つの機能を1つのボックスに統合することも可能です。最後に、ソリューションプロバイダーは、ビデオ処理(ビデオコーデックなど)や人工知能のワークロードなど、特定の目的に最適化されたアプリケーション専用ハードウェア製品を作ることができます。ストレージ管理のようなIT機能を、通常高価なコンピュートノードが行うタスクと組み合わせることで、CPUは広帯域幅のIO転送を行う必要から解放され、よりコンピュートクリティカルなオペレーションに再利用されるようになります。レイテンシーの観点からは、MPSoCベースのソリューションは、CPU駆動の代替案よりも低く、予測可能なレイテンシーを提供します。
結論
NVMeがここ数年で成熟するにつれ、NVMe-oFへの道が開かれ、現在ではNVMeと同様のメリットを分解されたストレージ環境に提供しています(Waver, 2019)。この技術は、データセンターの俊敏性とパフォーマンスを向上させながら、コンピュートとストレージノードの利用率を向上させました(Waver, 2019)。NVMe-oFにより、開発者は斬新な方法でアプリケーションをターゲットにすることができます。例えば、膨大なデータセット(数100PB)に対するランダムリードを必要とするAIワークロードは、この技術から大きな恩恵を受けるでしょう(Hemsoth、2019)。FPGAとMPSoCは、NVMe-oFプロトコルの上にさらなるイノベーションを提供します。これらのデバイスのプログラマブルロジックは、最適化やアプリケーション固有のカスタマイズのために構成可能なまま、高帯域幅データ転送と低レイテンシを処理できるシステムアーキテクチャを設計することができます。BittWare は、NVMe-oF用も含めた幅広い NVMeアクセラレーション オプションを用意しています。詳細については弊社までご連絡ください。
参考文献
- バーグナー E. (2019).高性能ストレージインターコネクトNVMe over TCPのプロバイダー3社がIDC Innovatorsに選出されました。AP News.2019年5月6日、APNews.comから取得しました。
- ギブS. (2018).NVMe-over-Fabricsを使用したFPGAアクセラレータの分散化。SNIA.2019年7月1日、SNIA.orgから取得しました。
- グプタ・R. (2018).NVMe™とは何か、そしてなぜ重要なのか?テクニカルガイド.ウエスタンデジタルブログ。2019年6月24日、Blog.WesternDigital.comから取得しました。
- ヘムソスN. (2019).既存のストレージインフラがAIのボトルネックに。Next Platform.2019年5月6日、NextPlatform.comから取得しました。
- ロビンソンD. (2019).VAST Dataは、ダウンタイムなし、データ損失なしを保証します。Blocks & Files.2019年5月6日、BlocksAndFiles.comから取得しました。
- ラウスM. (2019).コンピュテーショナル・ストレージのTech Target.2019年6月24日、SearchStorage.TechTarget.comから取得しました。
- Weaver E. (2019).M&Eが今NVMeを必要とするトップ5の理由。メディア&エンターテイメントサービスアライアンス.2019年5月6日、mesalliance.orgから取得。