

FPGAの最適化
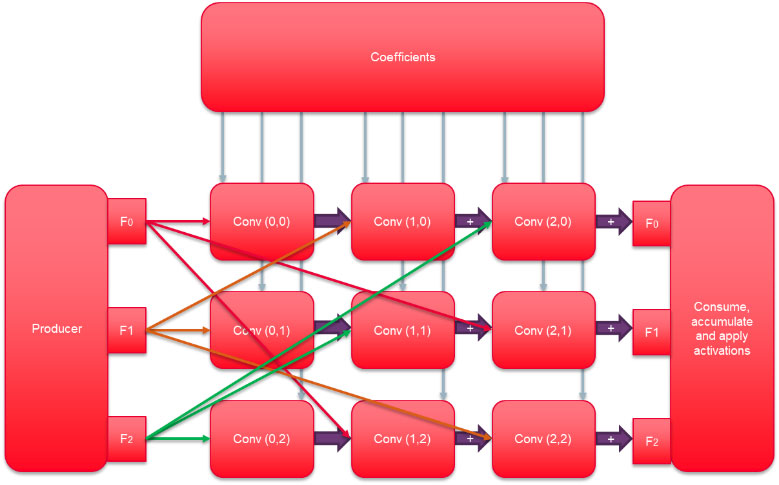
まず、重みを2値化することで、外部メモリの帯域幅とストレージの必要量を32分の1に削減することができます。FPGAファブリックは、各内部メモリブロックが1~32ビットの範囲のポート幅を持つように構成できるため、この2値化を利用することができます。したがって、重みを保存するための内部FPGAリソースが大幅に削減され、タスクの並列化のためのスペースが確保されます。
また、ネットワークの2値化により、CNNの畳み込みは入力の活性化の一連の加算または減算として表現することができる。ウェイトが2値0の場合、入力は結果から減算され、ウェイトが2値1の場合、結果に加算される。FPGA の各ロジック エレメントには、事実上あらゆるビット長の整数加算を効率的に実行できるキャリー チェーン ロジックが追加されています。これらのコンポーネントを効率的に使用することで、1つのFPGAで数万回の並列加算を実行することができます。そのためには、浮動小数点入力の活性化を固定精度に変換する必要があります。FPGAファブリックの柔軟性を利用すれば、CNNの要求に合わせて固定加算で使用するビット数を調整することが可能です。さまざまなCNNの活性化のダイナミックレンジを分析した結果、浮動小数点等価設計の1%以内の精度を維持するには、ほんの一握りのビット(通常は8ビット)が必要であることがわかりました。より高い精度を得るためには、ビット数を増やすことができます。
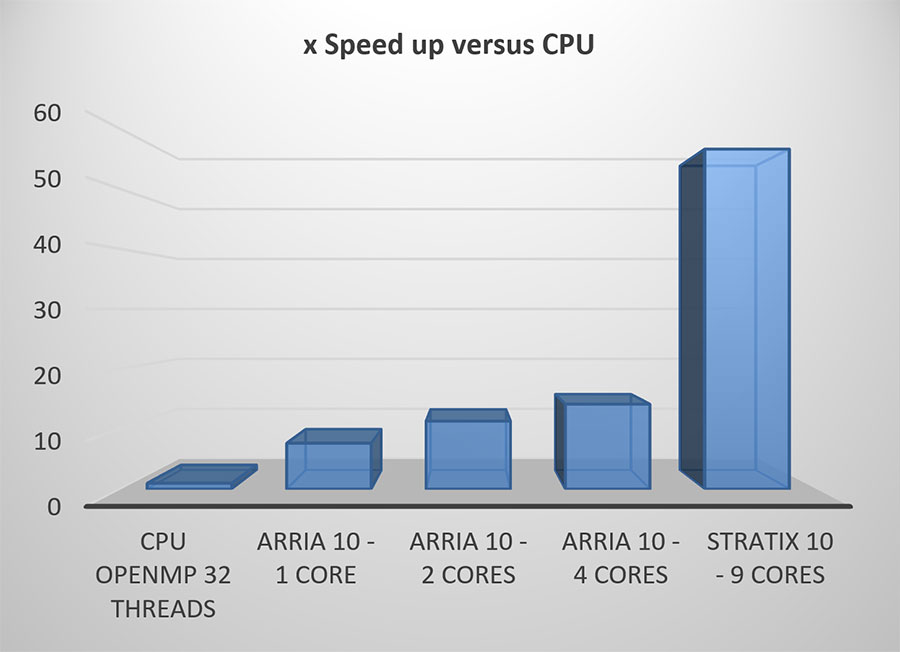
BNNのアプリケーションとして調査可能なネットワークは数多くあり、AlexNetのような多くのシンプルなネットワークの中から1つを選びたくなる。しかし、BWNN処理におけるFPGAの有効性を本当に理解するためには、YOLOv3のような最先端のネットワークを使用するのがよいでしょう。これは、多くの畳み込み層を持つ大規模な畳み込みネットワークである。
YOLOv3は深いネットワークであり、固定小数点丸めによって生じる誤差は、AlexNetのような小さなネットワークよりも、加算ごとに多くのビットを必要とします。FPGA技術の利点は、必要なビット数を正確に変更できることです。私たちのデザインでは、レイヤー間で転送されるデータを表現するために16ビットを使用しました。
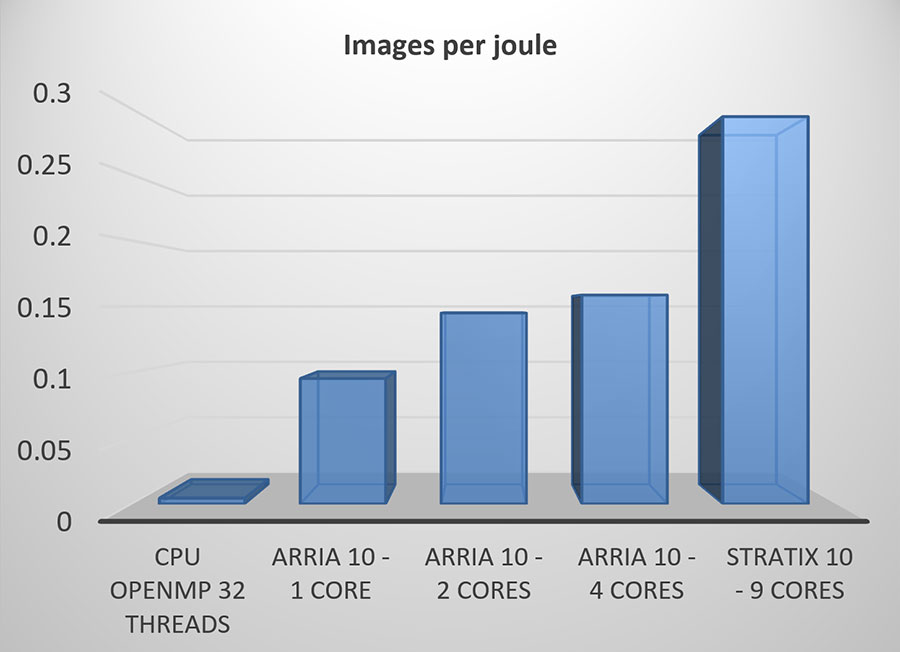
コンボリューションを固定小数点に変換し、2値化による乗算の必要性をなくすことで、FPGA内で必要なロジックリソースが劇的に削減されます。これにより、単精度や半精度の実装と比較して、同じFPGAで大幅に多くの処理を実行したり、FPGAロジックを他の処理に解放することが可能になります。
ターゲット・ネットワーク・トレーニング
YOLOv3ネットワークは、106層からなる大規模な畳み込みネットワークで、オブジェクトを識別するだけでなく、そのオブジェクトの周囲にバウンディングボックスを配置します。オブジェクトの追跡が必要なアプリケーションで特に有効です。
バイナリ重み付けネットワークは、適切に訓練された場合、YOLOv3ネットワークの精度をわずかに低下させるだけである。次の表は、再トレーニングしたYOLOv3ネットワークで得られた結果を示しています。

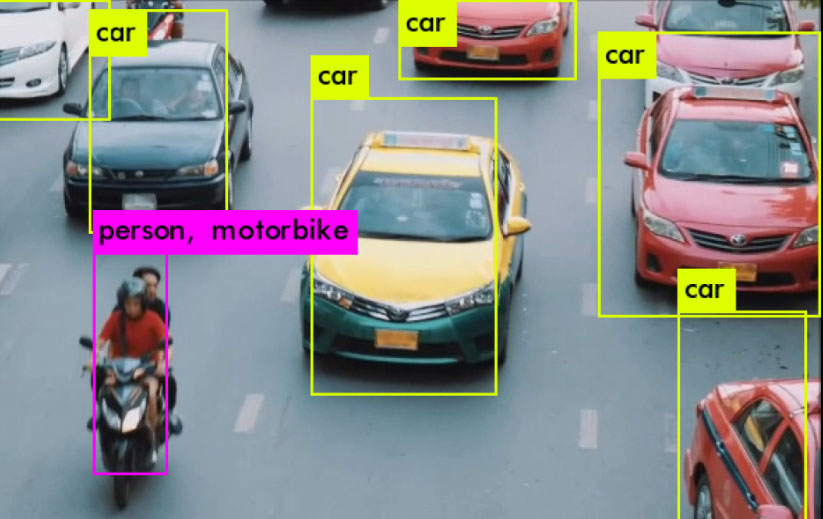
この画像の平均的な信頼度は、自転車の場合は76%、人の場合は82%でした。同じ画像で浮動小数点を使用した場合、自転車の平均信頼度は92%(16%向上)、人の平均信頼度は88%(6%向上)であることを比較してみてください。
FPGAで最高のパフォーマンスを発揮するためには、FPGAに最適なネットワーク機能をターゲットにすることが有効です。この場合、ネットワークは2値の重みで学習されるだけでなく、FPGAロジックに効率的にマッピングされる適切な活性化タイプが選択されました。