

FPGA ニューラルネットワーク
FPGAデバイス上でのニューラルネットワークの推論について、その長所と短所を説明しながら見ていきます。
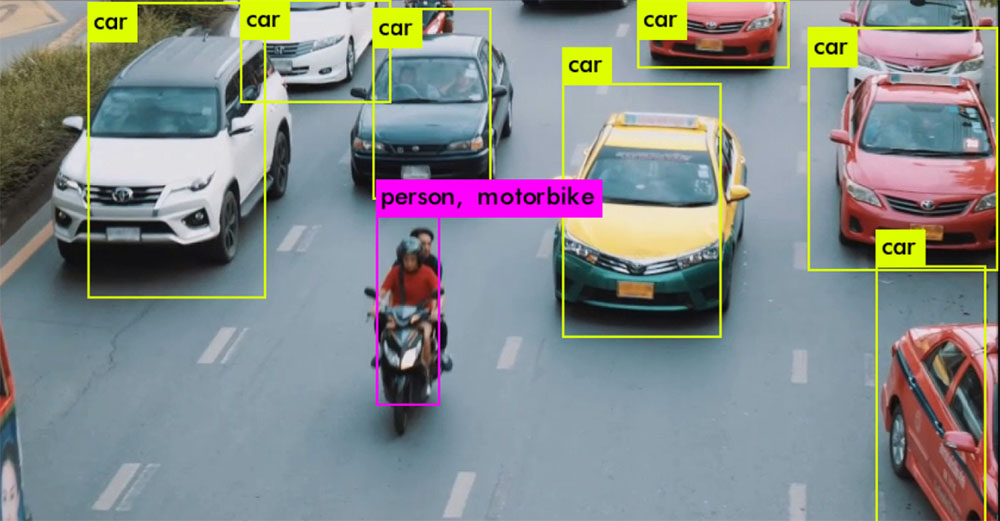
アクセラレーション BWNNの
プログラミングStratix 10 機械学習のためのOpenCLを使用します。カバーするトピックOpenCL、機械学習、Stratix 10。

CNNアクセラレーション
FPGAの可変精度を利用して、より良い機械学習推論ネットワークを構築する。トピックカバー:機械学習、アプリケーションテーラリング、Arria 10.
FPGAデバイス上でのニューラルネットワークの推論について、その長所と短所を説明しながら見ていきます。
プログラミングStratix 10 機械学習のためのOpenCLを使用します。カバーするトピックOpenCL、機械学習、Stratix 10。
FPGAの可変精度を利用して、より良い機械学習推論ネットワークを構築する。トピックカバー:機械学習、アプリケーションテーラリング、Arria 10.