
ホワイトペーパー
畳み込みニューラルネットワークのFPGAアクセラレーション
概要
畳み込みニューラルネットワーク(CNN)は、複雑な画像認識問題に非常に有効であることが示されている。このホワイトペーパーでは、 BittWare の FPGA アクセラレーター製品を使って、これらのネットワークを高速化する方法について説明し、Intel OpenCL Software Development Kit を使ってプログラミングします。さらに、計算精度を下げることで、画像分類の性能を大幅に向上させる方法についても説明します。精度を下げるごとに、FPGAアクセラレーターは1秒間に処理できる画像の枚数が増えていきます。
Caffeの統合
Caffeは、表現力、スピード、モジュール性を意識して作られた深層学習フレームワークです。Berkeley Vision and Learning Centerとコミュニティの貢献者により開発されています。
Caffeフレームワークは、特定のCNNに必要なさまざまな処理層を記述するために、XMLインターフェースを使用しています。様々な層の組み合わせを実装することで、ユーザーは与えられた要件に応じた新しいネットワークトポロジーを迅速に作成することができます。
その中でもよく使われるのが、このレイヤーです:
- コンボリューション(畳み込み):コンボリューション層は、入力画像を学習可能なフィルタのセットで畳み込み、それぞれが出力画像に1つの特徴マップを生成する。
- プーリング:マックスプーリングは、入力画像を重ならない矩形の集合に分割し、そのような部分領域ごとに、最大値を出力する。
- Rectified-Linear: Given an input value x, The ReLU layer computes the output as x if x > 0 and negative_slope * x if x <= 0.
- InnerProduct/Fully Connectedの略:画像は1つのベクトルとして扱われ、各点が新しい出力ベクトルの各点に寄与する。
この4つのレイヤーをFPGAに移植することで、Caffeフレームワークを用いて、大半の前方処理ネットワークをFPGAに実装することができます。
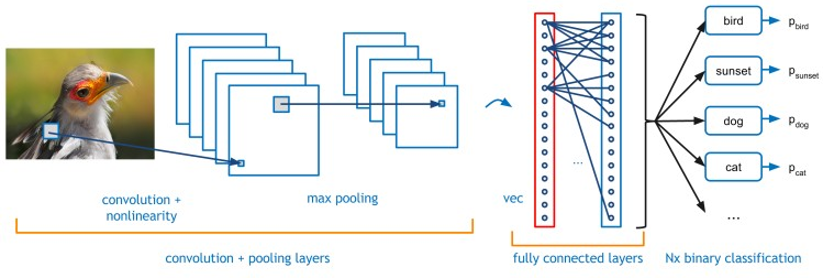
図1 : 典型的なCNN - Convolutional Neural Networkの例。
アレックスネット
AlexNetはよく知られたネットワークで、学習済みデータセットやベンチマークが自由に利用できる。この論文では、AlexNet CNNを対象としたFPGA実装について説明しますが、ここで使用するアプローチは、他のネットワークにも同様に適用できます。
図2は、AlexNet CNNが必要とするさまざまなネットワーク層を示したものである。5つの畳み込み層と3つの完全接続層がある。これらの層は、このネットワークの処理時間の99%以上を占めている。異なる畳み込み層には、11×11、5×5、3×3の3種類のフィルターサイズがあります。異なる畳み込み層に最適化された異なるレイヤーを作成することは非効率的である。これは、適用されるフィルタの数と入力画像のサイズによって、各層の計算時間が異なるためです。 入力と出力の特徴量の処理数に起因します。しかし、各畳み込みは、異なる数のレイヤーを必要とし、処理する画素数も異なる。より計算量の多い層に適用するリソースを増やすことで、各層が同じ時間で完了するようにバランスをとることができます。したがって、一度に複数の画像を飛行させることができるパイプラインプロセスを作成し、使用するロジックの効率を最大化することが可能である。つまり、ほとんどの処理要素が、ほとんどの時間、ビジー状態になっている。
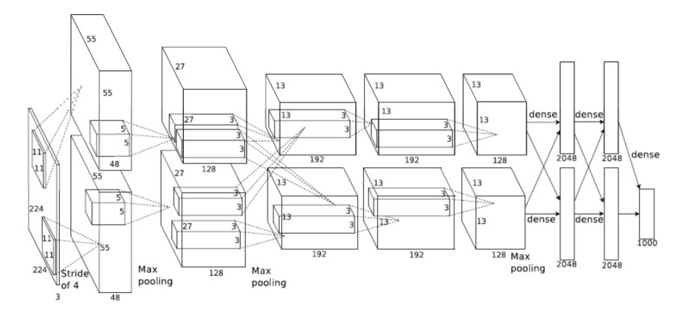
図2:AlexNet CNN - 畳み込みニューラルネットワーク
表1は、Imagenetネットワークの各レイヤーに必要な計算量を示しています。この表から、5×5畳み込み層は他の層よりも多くの計算を必要とすることがわかります。したがって、このレイヤーと他のレイヤーとのバランスをとるためには、FPGAの処理ロジックを増やす必要があります。
<p”>The inner product layers have a n to n mapping requiring a unique coefficient for each multiply add. Inner product layers usually require significantly less compute than convolutional layers and therefore require less parallelization of logic. In this scenario it makes sense to move the Inner Product layers onto the host CPU, leaving the FPGA to focus on convolutions.
FPGAのロジックエリア
FPGAデバイスには、DSPロジックとALUロジックの2つの処理 領域があります。DSPロジックは、乗算や乗算加算演算を行うための専用ロジックです。これは、浮動小数点数の大きな(18×18ビット)乗算にALUロジックを使用するとコストがかかるためである。DSPの演算では乗算が一般的であるため、FPGAベンダーはこの目的のために専用ロジックを用意しました。インテルはさらに一歩進んで、浮動小数点演算を実行するためにDSPロジックを再構成できるようにしました。CNN 処理のパフォーマンスを上げるには、FPGA に実装する乗算の回数を増やす必要があります。その1つの方法が、ビット精度を下げることです。
空の見出し
| イメージネットレイヤー | 乗算加算 (M) |
| コンボリューション (11×11) | 130 |
| コンボリューション(5×5) | 322 |
| コンボリューション(3×3) 1 | 149 |
| コンボリューション(3×3) 2 | 112 |
| コンボリューション(3×3) 3 | 75 |
| インナー・プロダクト 0 | 37 |
| インナープロダクト1 | 17 |
| 内製品2 | 4 |
表1:ImageNetレイヤーの計算要件
ビット精度
ほとんどのCNNの実装では、異なるレイヤーの計算に浮動小数点精度を使用しています。CPUやGPGPUの実装では、浮動小数点IPがチップ・アーキテクチャの固定部分であるため、これは問題にはならない。FPGA の場合、ロジック・エレメントは固定ではありません。インテルのArria 10 およびStratix 10 デバイスには、固定小数点乗算としても使用可能な浮動小数点 DSP ブロックが組み込まれています。各 DSP コンポーネントは、実際には 2 つの分離した 18×19 ビットの乗算として使用することができます。18ビット固定ロジックを使って畳み込みを行うことで、利用可能な演算子の数は、単精度浮動小数点と比較して2倍になります。
レイヤー | サイズ | フィルターサイズ | フィルターなし |
CONV x2 | 416×416 | 3×3 & 1×1 | 32,64 |
CONV x3 | 208×208 | 3×3 & 1×1 | 64,128 |
CONV x5 | 104×104 | 3×3 & 1×1 | 64,128 |
CONV x17 | 52×52 | 3×3 & 1×1 | 128,256 |
CONV x17 | 26×26 | 3×3 & 1×1 | 256,512 |
CONV x15 | 13×13 | 3×3 & 1×1 | 512×1024 |
アップサンプル&ルート | 26×26 | 3×3 & 1×1 | 256 |
CONV x7 | 26×26 | 3×3 & 1×1 | 256,512 |
アップサンプル&ルート | 52×52 | 3×3 & 1×1 | 128 |
CONV x7 | 52×52 | 3×3 & 1×1 | 128,256 |
図3:Arria 10浮動小数点DSPの構成
精度を落とした浮動小数点演算が必要な場合は、半精度を使用することができます。この場合、FPGAファブリックから追加のロジックが必要になりますが、低いビット精度がまだ適切であると仮定すると、可能な浮動小数点計算の数が2倍になります。
本ホワイトペーパーで紹介するパイプラインアプローチの主な利点のひとつは、パイプラインの異なるステージで精度を変化させることができることです。そのため、必要な部分のみリソースを使用することができ、設計の効率性が向上します。
CNNのアプリケーションの許容範囲に応じて、ビット精度をさらに下げることができる。乗算のビット幅を10ビット以下にすれば(20ビット出力)、FPGAのALUロジックだけで効率よく乗算を行うことができます。これにより、FPGAのDSPロジックを使用した場合と比較して、乗算可能回数が2倍になります。ネットワークによっては、さらに低いビット精度に耐えられるものもあります。FPGAは、必要に応じて、1ビットまでの精度を扱うことができます。
AlexNetが使用するCNN層では、10ビットの係数データが、単精度浮動小数点演算に対して1%以下の誤差を維持しつつ、単純な固定小数点実装で得られる最小限の減少であることが確認されました。
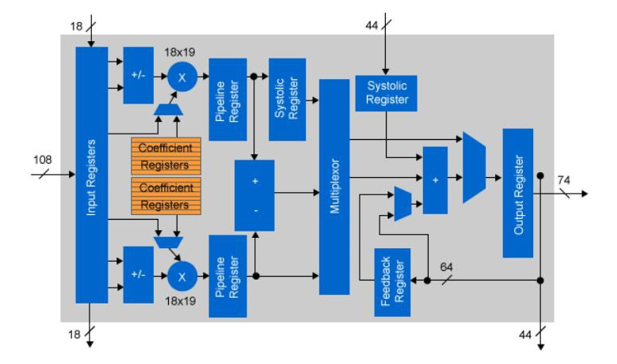
図4:Arria 10 固定小数点DSPの構成
CNNコンボリューションレイヤー
スライディングウィンドウ技術を用いることで、メモリ帯域が極めて少ないコンボリューションカーネルを作成することが可能です。
図5は、FPGAのメモリにデータがキャッシュされ、各ピクセルが複数回再利用される様子を示している。データの再利用量は、コンボリューションカーネルのサイズに比例します。
CNNの畳み込み層では、各入力層がすべての出力層に影響を与えるため、複数の入力層を同時に処理することが可能である。この場合、レイヤーをロードするために必要な外部メモリの帯域幅が増加する。そのため、係数を除くすべてのデータをFPGAデバイスのローカルM20Kメモリに格納することで、この増加を抑制している。デバイスのオンチップメモリの量は、実装できるCNNレイヤーの数を制限する。
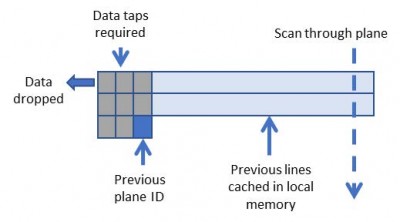
図5 : 3×3コンボリューションのためのスライディングウィンドウ
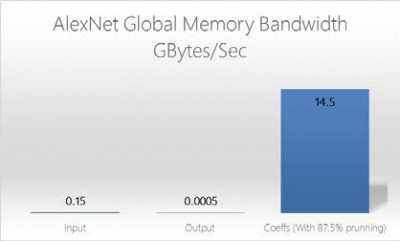
図6:OpenCLグローバルメモリバンド幅(AlexNet)
M20Kのリソース量によっては、1つのFPGAで完全なネットワークを構築できるとは限りません。このような場合、高速シリアルインターコネクトを使用して、複数のFPGAを直列に接続することができます。これにより、十分なリソースが確保できるまで、ネットワークパイプラインを拡張することができます。このアプローチの主な利点は、性能を最大化するためのバッチ処理に依存しないため、レイテンシが非常に低く、レイテンシが重要なアプリケーションにとって重要であることです。
レイヤー間の所要時間が同じになるようにバランスを取るには、並列に実装する入力レイヤーの数や並列に処理する画素数を調整する必要があります。
リソース | アレックスネット5×5畳み込み層(フロート) | AlexNet 5×5コンボリューションレイター(16ビット) |
登録 | 346,574 | 129,524 |
DSPブロック | 1,203 | 603 |
RAMブロック | 1,047 | 349 |
図9:Alexnetの5×5コンボリューションレイヤーのリソース
ほとんどのCNN機能は1つのM20Kメモリに収まりますが、FPGAファブリックに何千ものM20Kが組み込まれているため、コンボリューション機能を並列に使用できるメモリ帯域の合計は、10テラバイト/秒のオーダーとなります。
リソース | GX1150 | GX2800 |
ロジック・エレメント (K) | 1,150 | 2,753 |
ALM | 427,200 | 933,120 |
登録 | 1,708,800 | 3,732,480 |
可変精度DSPブロック | 181,5 | 5,760 |
18×19マルチプライヤー | 3,036 | 11,520 |
図7 :Arria 10 GX1150 /Stratix 10 GX2800 のリソース。
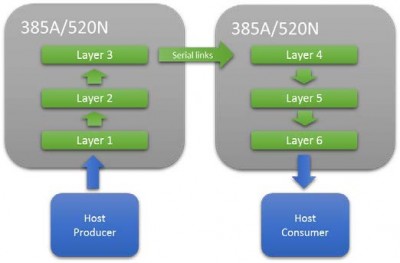
図8:複数のFPGAでCNNネットワークを拡張する場合
図9は、Alexnetの5×5コンボリューションレイヤーに48個の並列カーネルを使用し、Intel Arria10 FPGAで単精度版と16ビット固定小数点版の両方に必要なリソースを示したものです。この数値にはOpenCLボードロジックが含まれていますが、低精度がリソースに与えるメリットを示しています。
完全接続レイヤー
完全連結層の処理には、各要素に固有の係数が必要であるため、並列度を上げるとすぐにメモリに負荷がかかる。畳み込みレイヤーの処理に追いつくために必要な並列度は、FPGAのオフチップメモリをすぐに飽和させてしまうため、入力レイヤーのステージをバッチ化または刈り込みすることが提案されています。
内積層の要素数が少ないので、コンボリューション層に必要なストレージ量に対して、バッチ処理に必要なストレージ量は少なくて済みます。また、レイヤーをバッチ処理することで、バッチ処理された各レイヤーに同じ係数を使用することができ、外部メモリの帯域幅を小さくすることができます。
プルーニングは、入力データを調査し、閾値以下の値を無視することで機能する。完全接続層はCNNネットワークの後段に配置されるため、可能性のある多くの特徴はすでに排除されている。したがって、プルーニングは必要な作業量を大幅に削減することができます。
リソース
ネットワークの主要なリソースドライバーは、各層の出力を保存するために利用可能なオンチップM20Kメモリの量です。これは一定であり、達成される並列性の量とは無関係です。ネットワークを複数のFPGAに拡張すると、使用できるM20Kメモリの総量が増えるため、処理可能なCNNの深さが増えます。
空の見出し
結論
FPGAファブリックのユニークな柔軟性により、特定のネットワーク設計が必要とする最小限のロジック精度に調整することができます。CNN計算のビット精度を制限することで、1秒間に処理できる画像数を大幅に増やすことができ、性能の向上と消費電力の削減を実現します。
FPGA実装の非バッチアプローチにより、物体認識のための1フレームレイテンシーを実現し、低レイテンシーが重要視される状況に最適です。例:物体回避
この方法をAlexNetに適用すると(第1層は単精度、残りの層は16ビット固定)、Arria 10 FPGA1個で1.2ミリ秒、FPGA2個で0.58ミリ秒で各画像を処理することができます。