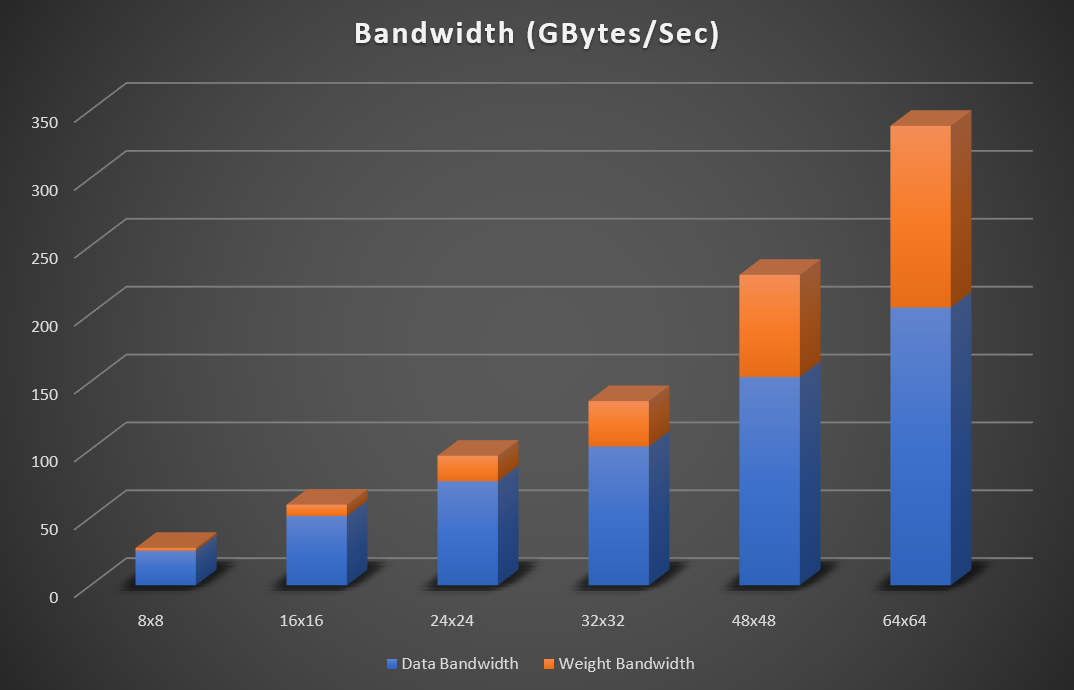
IntelAgilex シリーズはテンソルDSPコンポーネントを搭載していませんが、そのDSPはStratix 10 から改良され、より多くのデータ型をサポートし、低精度演算のスループットを向上させています。IntelAgilex MシリーズのResnet-50の理論性能は88 INT TOPS.2です。
図8 :BittWare 520NX
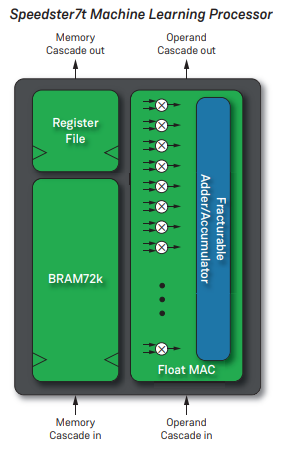
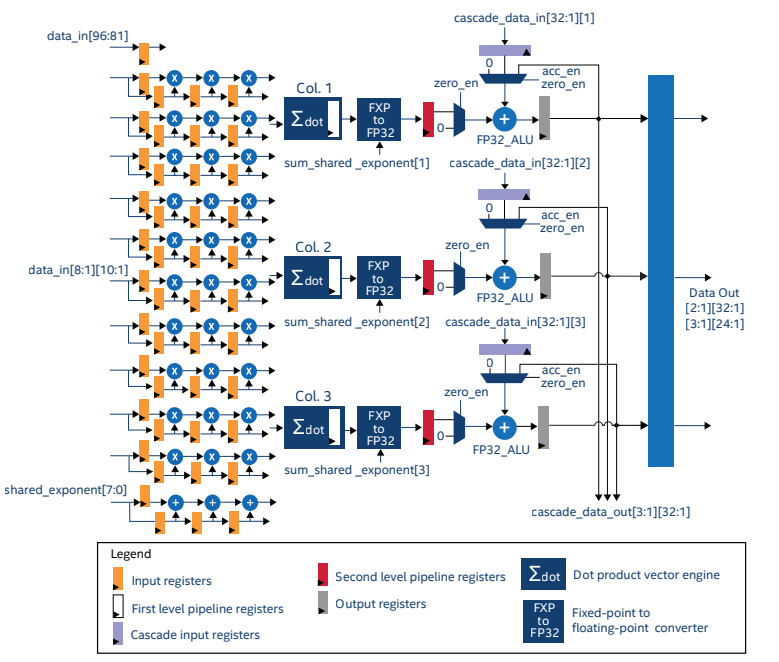
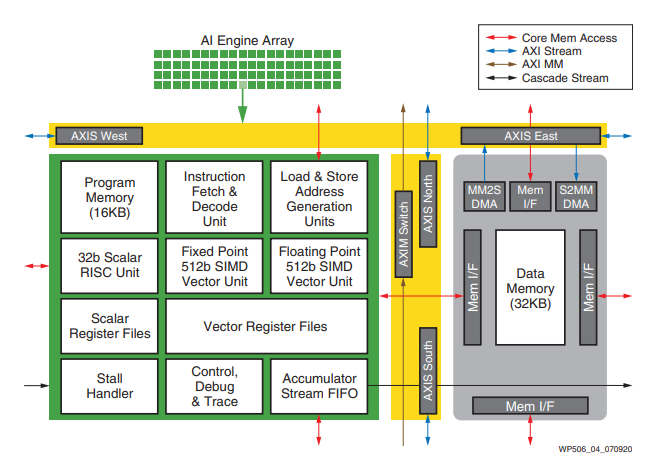
AMD ザイリンクス Versal
ザイリンクスのVersalデバイスには、FPGAのプログラマブルロジックに統合されていない独立したAIエンジンがあります。バーサルのAIエンジンはFPGAと密接に結合していますが、FPGAの他の部分とは独立して動作しています。データは、NOC(Network On Chip)を使用して、AIエンジンとFPGAロジックの間で受け渡されます。