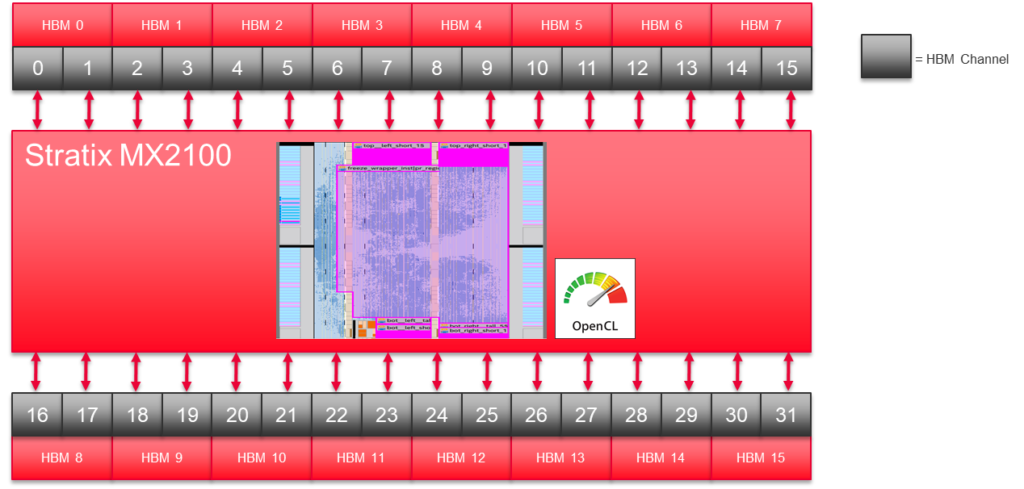
 Stratix 10 MX有32个伪HBM2内存通道。我们的2D FFT实现使用这些通道的一半。
Stratix 10 MX有32个伪HBM2内存通道。我们的2D FFT实现使用这些通道的一半。
- 我们可以在芯片中放置两个二维FFT内核。一个内核使用芯片北侧的所有伪通道接口。 另一个使用南侧的通道。
- 试图在一个单一的二维FFT中使用所有32个通道会产生我们不想在示范代码中处理的路由挑战。
每个FPGA的HBM2通道有一排
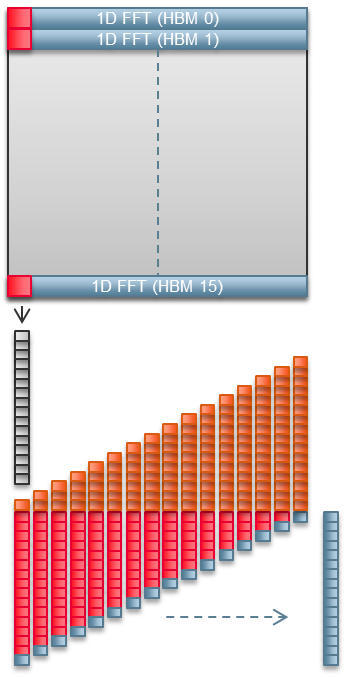
二维FFT是通过许多一维FFT实现的。一个单一的1D FFT会使其使用的HBM2通道达到饱和。有了16个HBM2通道,我们的二维FFT实现可以并行处理1024行矩阵的16行。 高端GPU可能可以一次性处理所有1024行。FPGA需要64个通道。然而,通道的数量并不重要,因为HBM2/GDDR6带宽是两种情况下的限制因素。400兆赫Fmax足够了
我们需要400兆赫的OpenCL时钟频率,以使每个HBM2通道达到最佳的32字节突发状态。再快就没有价值了。再慢一点也不是最佳状态。英特尔目前对DPC++的实现利用了BittWare现有的OpenCL板支持包。因此,两种实现方式在FPGA上看起来都像OpenCL。两种实现都需要同样的调整来实现400MHz。这些调整只是在源代码中的表达方式不同。1D FFT输出
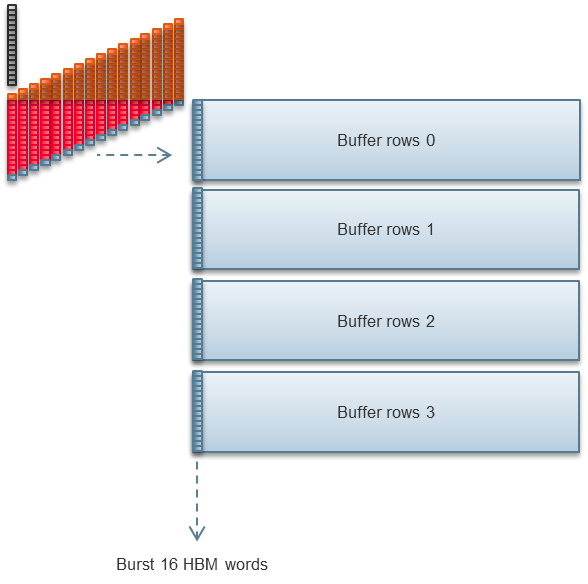
1D FFT不直接向HBM2输出结果。相反,它写入FPGA内部存储器中。额外的FPGA逻辑收集多个一维FFT的结果,将这些结果转角,并将它们写回HBM2,所有这些都是与计算并行的。