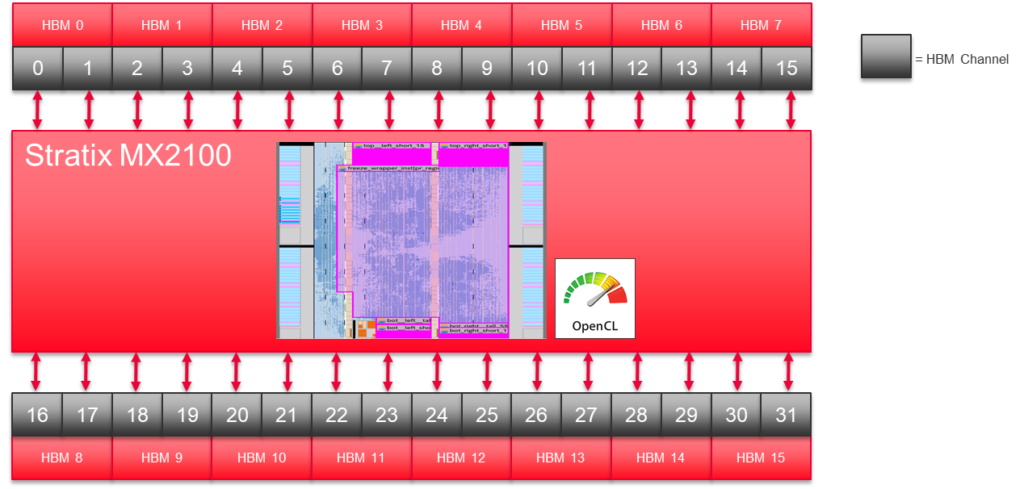
 Stratix 10 MX에는 32개의 의사 HBM2 메모리 채널이 있습니다. 유니티의 2D FFT 구현은 이 채널의 절반을 사용합니다.
Stratix 10 MX에는 32개의 의사 HBM2 메모리 채널이 있습니다. 유니티의 2D FFT 구현은 이 채널의 절반을 사용합니다.
- 칩에 두 개의 2D FFT 커널을 배치할 수 있습니다. 한 커널은 칩의 북쪽에 있는 모든 의사 채널 인터페이스를 사용합니다. 다른 하나는 남쪽의 채널을 사용합니다.
- 단일 2D FFT에서 32개 채널을 모두 사용하려고 하면 데모 코드에서 다루고 싶지 않은 라우팅 문제가 발생합니다.
FPGA HBM2 채널당 1열
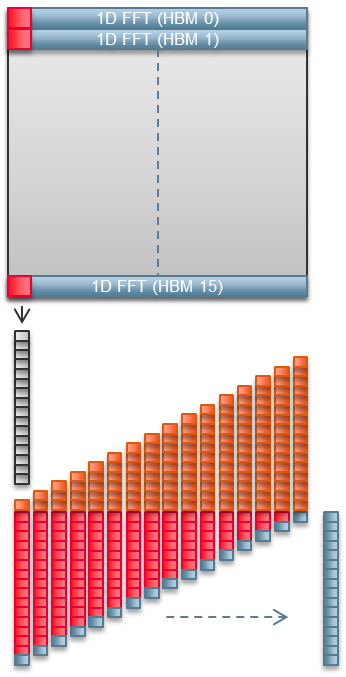
2D FFT는 여러 개의 1D FFT를 사용하여 구현됩니다. 단일 1D FFT는 사용하는 HBM2 채널을 포화시킵니다. 16개의 HBM2 채널로 2D FFT를 구현하면 1024행 매트릭스의 16행이 병렬로 처리됩니다. 하이엔드 GPU는 아마도 1024 행을 모두 한 번에 처리할 수 있을 것입니다. FPGA는 64개의 패스가 필요합니다. 그러나 두 경우 모두 HBM2/GDDR6 대역폭이 제한 요소이므로 패스 수는 중요하지 않습니다.400MHz Fmax면 충분합니다
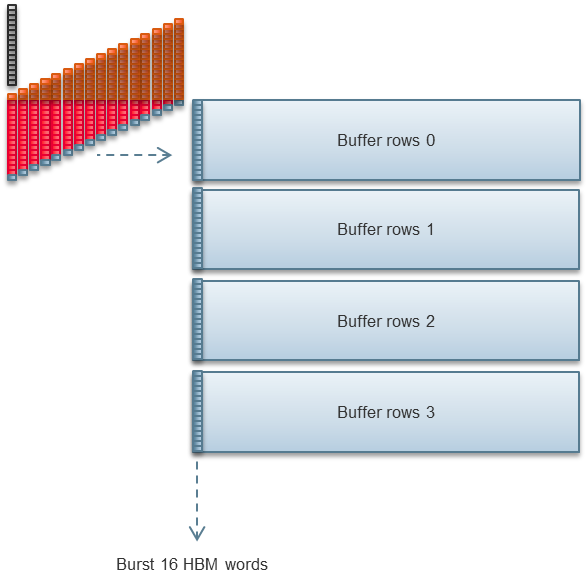
최적의 32바이트 버스트를 수행하는 각 HBM2 채널을 포화 상태로 만들려면 400MHz OpenCL 클럭 주파수가 필요합니다. 더 빨라지는 것은 가치가 없습니다. 느리게 가는 것도 최적이 아닙니다. 인텔의 현재 DPC++ 구현은 비트웨어의 기존 OpenCL 보드 지원 패키지를 활용합니다. 따라서 두 구현 모두 FPGA에 대한 OpenCL처럼 보입니다. 두 구현 모두 400MHz를 달성하기 위해 동일한 조정이 필요합니다. 이러한 조정은 소스 코드에서 다르게 표현될 뿐입니다.1D FFT 출력
1D FFT는 결과를 HBM2로 직접 출력하지 않습니다. 대신 FPGA 내부 메모리에 기록합니다. 추가 FPGA 로직은 여러 1D FFT의 결과를 수집하고, 그 결과를 코너링한 후 계산과 병행하여 HBM2에 다시 씁니다.