

FPGA 최적화
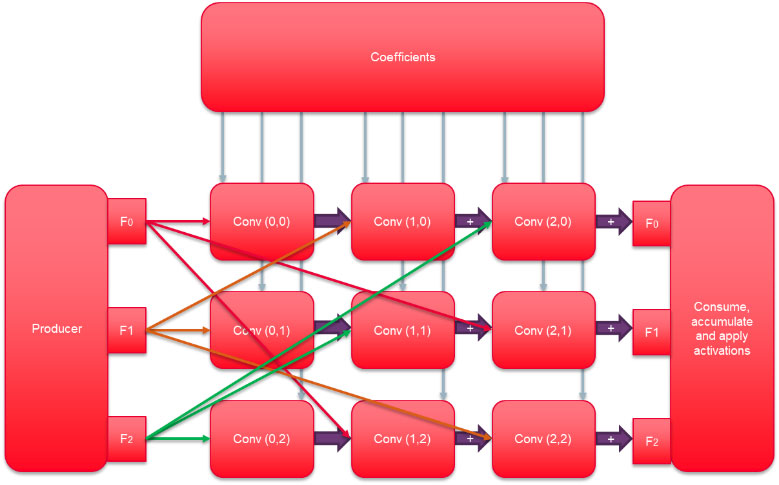
첫째, 가중치의 이진화는 외부 메모리 대역폭과 스토리지 요구 사항을 32배까지 줄여줍니다. 각 내부 메모리 블록은 1비트에서 32비트 범위의 포트 폭을 갖도록 구성할 수 있으므로 FPGA 패브릭은 이러한 이진화의 이점을 활용할 수 있습니다. 따라서 가중치 저장을 위한 내부 FPGA 리소스가 크게 줄어들어 작업 병렬화를 위한 더 많은 공간을 확보할 수 있습니다.
또한 네트워크의 이진화를 통해 CNN 컨볼루션을 입력 활성화의 일련의 더하기 또는 빼기로 표현할 수 있습니다. 가중치가 이진 0이면 입력이 결과에서 차감되고, 가중치가 이진 1이면 결과에 더해집니다. FPGA의 각 논리 소자에는 거의 모든 비트 길이의 정수 덧셈을 효율적으로 수행할 수 있는 추가 캐리 체인 로직이 있습니다. 이러한 구성 요소를 효율적으로 활용하면 단일 FPGA로 수만 개의 병렬 덧셈을 수행할 수 있습니다. 이를 위해서는 부동 소수점 입력 활성화를 고정 정밀도로 변환해야 합니다. FPGA 패브릭의 유연성을 통해 고정 덧셈에 사용되는 비트 수를 조정하여 CNN의 요구 사항을 충족할 수 있습니다. 다양한 CNN의 동적 활성화 범위를 분석한 결과, 부동 소수점 등가 설계의 1% 이내로 정확도를 유지하는 데 필요한 비트는 일반적으로 8비트에 불과한 것으로 나타났습니다. 정확도를 높이려면 비트 수를 늘릴 수 있습니다.
BNN 애플리케이션을 위해 조사할 수 있는 다양한 네트워크가 있으며, AlexNet과 같은 간단한 네트워크 중 하나를 선택하고 싶은 유혹을 느낄 수 있습니다. 그러나 BWNN 처리를 위한 FPGA의 효과를 실제로 이해하려면 YOLOv3와 같은 최신 네트워크를 사용하는 것이 좋습니다. 이것은 많은 컨볼루션 레이어가 있는 대규모 컨볼루션 네트워크입니다.
YOLOv3는 딥 네트워크이므로 고정 소수점 반올림으로 인해 발생하는 오류는 AlexNet과 같은 소규모 네트워크보다 추가당 더 많은 비트가 필요합니다. FPGA 기술의 장점은 필요한 비트 수를 정확하게 수정할 수 있다는 점입니다. 저희 설계에서는 레이어 간에 전송되는 데이터를 표현하기 위해 16비트를 사용했습니다.
컨볼루션을 고정점으로 변환하고 이진화를 통해 곱셈의 필요성을 제거하면 FPGA 내에서 필요한 로직 리소스가 크게 줄어듭니다. 그러면 단일 정밀도 또는 반정밀도 구현에 비해 동일한 FPGA에서 훨씬 더 많은 처리를 수행하거나 다른 처리를 위해 FPGA 로직을 확보할 수 있습니다.
타겟 네트워크 교육
YOLOv3 네트워크는 106개의 레이어로 구성된 대규모 컨볼루션 네트워크로, 객체를 식별할 뿐만 아니라 객체 주변에 바운딩 박스를 배치합니다. 물체를 추적해야 하는 애플리케이션에 특히 유용합니다.
이진 가중치 네트워크는 적절하게 훈련된 경우 YOLOv3 네트워크의 정확도를 약간만 떨어뜨립니다. 다음 표는 재트레이닝된 YOLOv3 네트워크에 대해 얻은 결과를 보여줍니다.

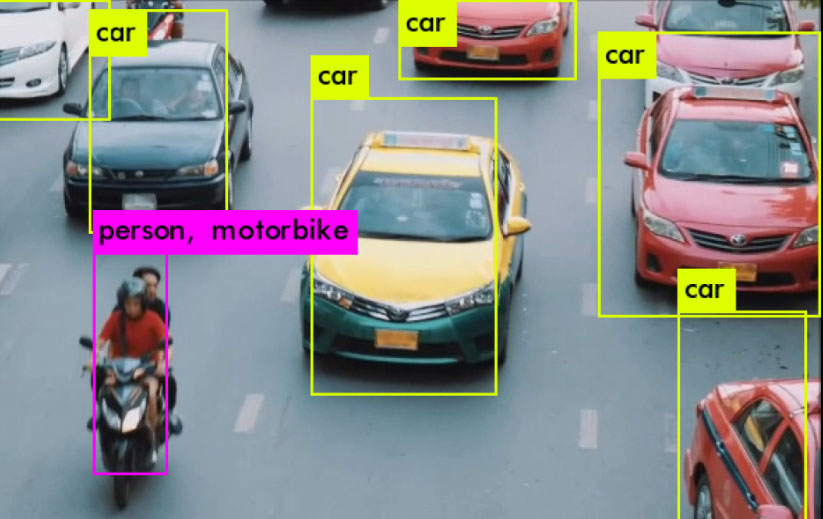
이 이미지의 자전거에 대한 평균 신뢰도는 76%, 사람에 대한 신뢰도는 82%였습니다. 이를 같은 이미지의 부동 소수점과 비교하면 자전거는 평균 92%(16% 향상), 사람은 88%(6% 향상)의 정확도를 얻을 수 있습니다.
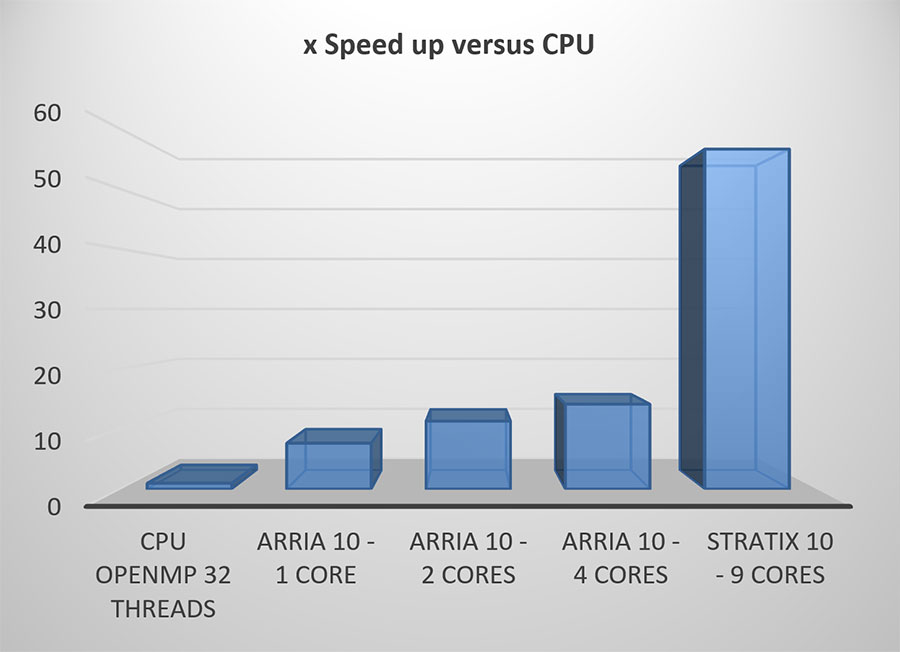
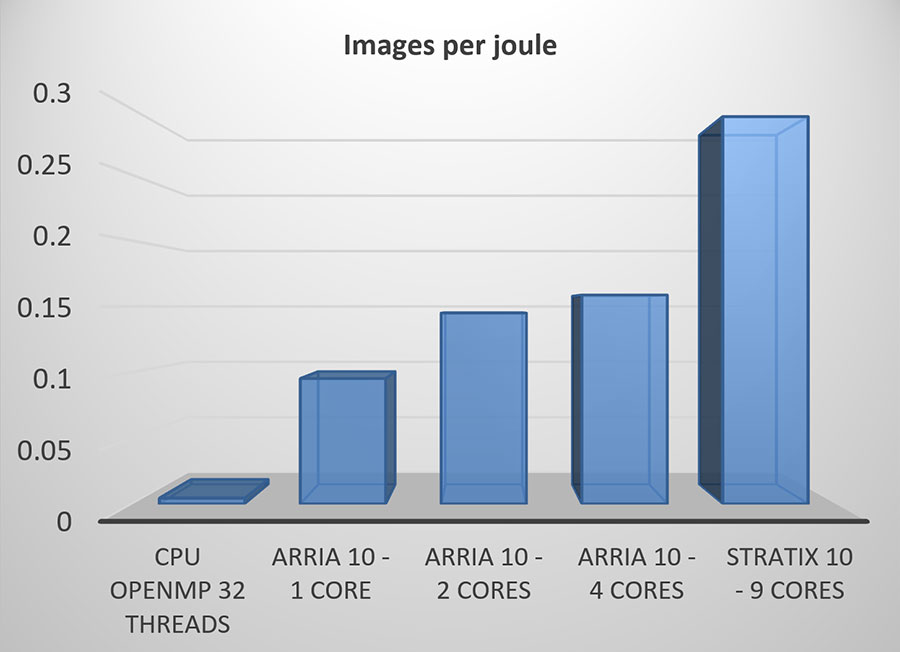
FPGA에서 최상의 성능을 얻으려면 FPGA에 가장 잘 매핑되는 네트워크 기능을 타겟팅하는 것이 도움이 됩니다. 이 사례에서는 네트워크가 바이너리 가중치에 대해 훈련되었을 뿐만 아니라 FPGA 로직에 효율적으로 매핑되는 적절한 활성화 유형이 선택되었습니다.