
백서
네트워킹 예제를 사용한 FPGA RTL과 HLS C/C++의 비교
개요
대부분의 FPGA 프로그래머는 높은 수준의 툴이 항상 더 큰 비트 스트림을 생성하기 때문에 생산성이 높아지는 '비용'이 발생한다고 생각합니다. 하지만 이것이 항상 사실일까요? 이 백서에서는 동일한 하드웨어에서 기존의 RTL/Verilog 툴과 하이레벨 합성(HLS)을 모두 사용하여 공통 네트워크 함수인 RSS를 생성한 실제 사례를 보여드립니다. 놀랍게도 HLS 접근 방식이 실제로 더 적은 수의 FPGA 게이트와 메모리를 사용한다는 사실을 발견했습니다. 이유가 있습니다. 자세한 내용을 읽어보세요.
FPGA 개발에 대한 HLS 접근 방식은 C/C++ 환경에서 쉽게 표현할 수 있는 애플리케이션의 일부분만 추상화하는 것입니다. HLS 툴 흐름은 기본적으로 Vivado(Xilinx) 또는 Intel(Quartus) 툴을 사용하여 모든 BittWare 보드에 사용할 수 있습니다.
HLS를 성공적으로 사용하려면 애플리케이션의 어떤 부분이 적합한지 파악하는 것이 중요합니다. 가이드라인은 다음과 같습니다:
- 대상 용도는 일반적으로 우선 높은 수준의 언어로 정의된 IP 블록입니다. 수학 알고리즘이 잘 작동하거나 RSS 블록에서와 같이 일부 네트워크 프로토콜 처리가 가능합니다.
- 또 다른 사용 범주는 제대로 정의되지 않아 여러 차례의 구현이 필요할 수 있는 블록입니다. 여기서 가장 큰 장점은 HLS 툴이 결과 네이티브 FPGA 코드를 자동으로 파이프라인화하여 파이프라인을 빠르게 수작업으로 코딩하는 것보다 더 적은 단계로 구현할 수 있다는 점입니다. 또한 수작업으로 코딩한 파이프라인을 수정할 때 하나의 병렬 경로에서 지연 변경이 발생하면 모든 경로에 파급 효과를 미칠 수 있습니다. HLS 툴을 사용하여 처음부터 두 번째로 파이프라인을 자동으로 생성하면 이러한 골칫거리를 없앨 수 있습니다.
- 마지막으로, HLS 플로우를 사용하면 FPGA 브랜드와 속도 등급 간에 코드를 더 쉽게 포팅할 수 있습니다. 이는 HLS가 적절한 수의 파이프라인 스테이지를 자동으로 생성하기 때문인데, 이는 Verilog 또는 VHDL로 작업할 때 수동으로 지정해야 하는 사항입니다.
현재 HLS의 한계는 그 범위가 IP 블록으로 제한되어 있다는 점입니다. 애플리케이션 팀은 여전히 다른 구성 요소에 대해 RTL을 요구할 수 있지만, RTL 부분에 대해 BittWare의 SmartNIC Shell과 같은 것을 활용하면 사용자가 고유한 애플리케이션을 HLS에서 완전히 정의할 수 있습니다. 또한 HLS는 가장 단순한 코드나 대부분 사전 최적화된 컴포넌트로 구성된 대규모 디자인에는 적합하지 않다는 점에 유의해야 합니다.
애플리케이션 FPGA에서 RSS 네트워킹
RSS란 무엇인가요? RSS는 "수신자 측 스케일링"의 약자입니다. 이는 네트워크 패킷을 여러 CPU에 효율적으로 분산하기 위한 해싱 알고리즘입니다. RSS는 최신 이더넷 카드의 기능으로, 일반적으로 Microsoft에서 정의한 특정 토플리츠 해시를 구현합니다.
RSS 애플리케이션을 호스팅하는 환경은 BittWare의 SmartNIC 셸입니다. SmartNIC 셸은 사용자가 FPGA 기반 네트워킹 애플리케이션을 구축할 때 유리하게 시작할 수 있도록 설계되었습니다. 이 셸은 호스트 상호 작용을 위한 DPDK를 포함하여 최적화된 FPGA 기반 100G 이더넷 파이프라인을 사용자에게 제공합니다. 사용자는 애플리케이션을 IP 블록으로 드롭하기만 하면 됩니다.
이 경우 BittWare는 RSS의 FPGA 구현을 애플리케이션으로 만든 사용자이기도 했습니다. 전통적인 RTL 접근 방식을 사용하여 RSS를 만드는 팀과 HLS 팀 모두 SmartNIC Shell을 FPGA 이더넷 프레임워크로 사용하고 RSS 애플리케이션 자체에 집중할 수 있었습니다.
BittWare의 RSS 구현
저희의 FPGA 기반 RSS 구현은 특히 DPDK 소스 트리에 있는 C 코드를 기반으로 하며, 해당 코드에 대한 테스트 기능도 트리에서 사용할 수 있습니다. 또한 RSS 애플리케이션은 일반적인 128개 항목 테이블 대신 64개 항목의 인디렉션 테이블을 사용합니다. 이 HLS 연구에서 중요한 점은 FPGA로 이동하는 함수가 C로 정의되어 시작한다는 것입니다. 이는 HLS 성공의 가장 중요한 기준인 C 또는 C++로 정의된 함수를 충족합니다.
튜플을 사용하여 패킷 그룹화
RSS 기능의 목표는 관련 패킷 스트림을 함께 유지하면서 CPU 간에 패킷을 배포하는 것입니다. 토플리츠 키 세트마다 다른 배포 패턴을 제공합니다. 그러나 키 세트에 관계없이 RSS 기능은 각 패킷의 소스 및 대상 IP 주소와 소스 및 대상 포트를 입력으로 사용합니다. 이 네 가지 구성 요소를 결합한 것을 4-튜플이라고 합니다.
RSS 애플리케이션의 경우 4-튜플이 이미 파싱되어 패킷의 메타데이터에 추가되었다고 가정합니다. 이 패킷 분류 기능은 또 다른 SmartNIC 셸 모듈이 처리합니다. 이 모듈을 "파서"라고 부르며 별도의 BittWare 백서에서 다룰 예정입니다.
현재 트위터의 RSS 구현은 분류를 위해 96비트 필드를 허용하며, 이는 IPv4 소스/목적지 및 포트의 4-튜플에 충분합니다. 파서는 패킷에서 사용할 수 없는 필드에 대해서는 0을 제공하며, 패킷에 IP 페이로드가 포함되지 않은 경우 전체 96비트 튜플 필드는 0이 됩니다.
많은 RSS 구현은 4튜플 대신 5튜플을 사용합니다. 그렇게 하려면 프로토콜 번호를 수용하기 위해 8비트가 추가로 필요합니다. RSS의 HLS 사용자는 약간의 소스 코드 변경으로 이러한 변경 사항을 쉽게 수용할 수 있습니다. 4-튜플에서 5-튜플로 빠르게 적응할 수 있는 이러한 능력은 HLS 성공의 두 번째 기준인 여러 차례의 구현을 위한 요구 사항을 보여주는 예입니다.
FPGA 개발 툴 용어
FPGA 내부에서 실행되는 IP를 개발할 때는 원래 ASIC 개발을 위해 만들어진 언어를 사용합니다. 이러한 언어를 무엇이라고 부를지에 대한 합의가 이루어지지 않았습니다. 레지스터 전송 언어의 약자인 "RTL"을 사용하는 경우도 있습니다. 다른 사람들은 하드웨어 정의 언어의 약자인 "HDL"을 사용합니다. 가장 널리 사용되는 두 가지 HDL은 VHDL과 SystemVerilog입니다. 내부적으로는 두 가지를 모두 사용하지만 대규모 프로젝트에서는 SystemVerilog와 전체 검증 기능 세트를 사용합니다.
검증은 FPGA 설계 프로세스의 중요한 부분이며 ASIC 설계의 핵심적인 부분입니다. ASIC 업계의 비용 상승으로 인해 실리콘 1차 통과 성공을 보장하기 위한 고급 검증 언어와 기술이 필요하게 되었습니다. 이러한 필요성에 따라 Verilog 언어에 HVL(고급 검증 언어)의 기능을 통합하게 되었고, 결국 현재의 SystemVerilog IEEE 1800 표준으로 통합되었습니다. 또한 최신 ASIC 검증은 테스트 벤치 구축의 표준 방법을 제공하는 범용 검증 방법론(UVM)으로 나아가고 있습니다.
FPGA 개발의 다양한 경제성과 실험실에서 설계를 즉시 테스트할 수 있는 기능으로 인해 FPGA 개발자들 사이에서 UVM의 채택이 늦어졌습니다. 그럼에도 불구하고 고밀도 FPGA의 복잡성이 증가함에 따라 많은 그룹이 ASIC 설계 흐름에 사용되는 것과 동일한 검증 방법론을 채택하게 되었습니다. 비트웨어는 FPGA 검증에 대한 유동적인 접근 방식을 가지고 있습니다. 우리는 종종 저렴한 무료 시뮬레이터에서 제공되는 SystemVerilog 또는 VHDL 기능을 기반으로 하는 간단한 테스트 벤치를 사용합니다. 그러나 적절한 경우 SystemVerilog 및 UVM의 전체 기능 세트를 기반으로 최신 테스트 벤치를 구축합니다.
HLS, 즉 고수준 합성은 HDL보다 더 높은 수준의 추상화에서 작동하는 언어에 부여되는 이름입니다. 실제로 HLS는 일반적으로 C 또는 C++의 특수 버전을 의미합니다. 하지만 다른 HLS 언어도 있습니다. 예를 들어, BittWare가 배포하는 일부 타사 IP는 BlueSpec으로 작성되었습니다. 이러한 모든 HLS 도구는 모듈 수준에서 테스트벤치를 생성하는 간편한 푸시 버튼 방식으로 제공되는 경향이 있습니다. 시스템 수준에서는 여전히 UVM이 필요합니다.
마지막으로 오늘날 가장 높은 수준에서는 OpenCL이 있습니다. 이는 GPU 칩용으로 개발된 병렬 프로그래밍 언어이며 FPGA 세계로 용도가 변경되었습니다. 오늘날 OpenCL은 거의 전적으로 HPC, 즉 고성능 컴퓨팅에 적용되며, 인텔 기반 서버가 실행할 수 있는 속도보다 빠르게 실행되는 계산 알고리즘을 구현하는 데 사용됩니다.
성능을 위한 HLS 코딩
HLS를 사용하면 소프트웨어와 유사한 도구 흐름을 제공하지만, 개발자는 기존 프로세서용 C 코드를 작성할 때 접하지 못했던 파이프라이닝 및 반복 간격과 같은 하드웨어 중심 개념을 익혀야 합니다.
HLS 코드는 주로 임베디드 설계를 위한 IP 구성 요소를 개발하는 데 사용되며, 일반적으로 파이프라인으로 연결됩니다. RSS 애플리케이션도 예외는 아닙니다. RSS의 최소 성능 요구 사항은 포화 상태인 100Gb/s 네트워크 인터페이스에 맞춰 각 512비트 입력 단어를 충분히 빠르게 처리하는 것입니다. 이는 300MHz의 주파수에서 매 클럭 사이클마다 새로운 단어를 처리하는 것과 같습니다. 이 주파수는 가장 빠른 FPGA도 400MHz보다 훨씬 높지 않은 주파수에서 실행된다는 점에서 까다롭습니다. 분명한 것은 매 클럭마다 새로운 단어를 처리해야 한다는 것입니다.
여기서는 파이프라인에서 주어진 로직이 완료되는 데 필요한 클럭 주기를 나타내는 반복 간격(II)의 개념을 소개합니다. RSS 모듈의 경우 매 클럭마다 결과인 II가 1이 필요하므로 이 요구 사항을 위반하지 않는 코드를 작성하는 방법을 이해해야 합니다.
더 높은 II의 원인은 다음과 같습니다:
- 루프 간 종속성은 파이프라인의 다음 출력이 파이프라인의 다른 변수의 미래 결과를 필요로 할 때 발생합니다(예: 재귀). 누산기와 같은 간단한 재귀 연산자는 단일 클록 주기 내에 이러한 계산을 수행하는 로직이 포함되어 있으므로 FPGA에서 허용됩니다. 그러나 더 복잡한 재귀를 사용하려면 더 높은 II 값이 필요합니다.
- RSS 설계에서는 파이프라인의 각 단계가 3.3ns 이내에 완료되도록 요구합니다. HLS 도구는 각 단계가 이 타이밍 요건을 충족하도록 필요한 곳에 등록을 삽입합니다. 그러나 조합 로직을 파이프라인화할 수 없는 경우 항상 그렇게 할 수 있는 것은 아닙니다. 예를 들어 심층 조합 논리는 여러 중첩 루프에 대한 인덱싱 계산이 될 수 있습니다.
- 목표 클럭 주파수가 너무 높고 FPGA 패브릭 라우팅 경로가 너무 길어 타이밍 요구 사항을 충족하지 못하면 II가 증가합니다. 이 문제에 대한 해결책은 로직을 절반의 클럭 주파수로 실행되는 두 개의 경로로 분할하는 것입니다.
코드의 본문은 필요한 입력 튜플 단어 수만큼 반복하여 새 해시를 생성합니다. 이 예제에서는 96비트 해시 값에 3개의 단어로 구성된 입력 튜플을 사용합니다.
int input_len = 3;
/*
* The hash calculation is calculated per input tuple word.
*/
int32_t ret = 0;
int j, i;
for (j = 0; j < input_len; j++) {
for (i = 0; i < 32; i++) {
if (tuple_in_i[j] & (l << (32 - i ))) {
ret ^= rte_cpu_to_be_32(((const uint32_t *)rss_key) [j]) << i |
(uint32_t) ((uint64_t) (rte_cpu_to_be_32 (((const uint32_t *)rss_key) [j + 1])) >>
(32 - i));
}
}
}
return ret;

이 코드는 RSS 계산의 핵심을 구현합니다. 이 코드는 DPDK 소스 트리에서 추출한 원본과 변경되지 않았습니다. 따라서 이 RSS 블록의 경우, 모든 포팅 작업은 블록의 AXI 인터페이스를 정의하고 II와 같은 정의에 프라그마 문을 추가하는 것이었습니다.
입력 길이가 상수인 경우 FPGA는 두 루프를 완전히 풀어서 완전한 파이프라인 코드를 생성할 수 있습니다.
IP 구성 요소를 스마트 NIC 프레임워크에 통합하려면 외부 인터페이스를 읽고 쓰기 위한 로직과 함께 인터페이스와 제어 플레인을 정의해야 합니다. 스마트 NIC 프레임워크는 AXI 인터페이스 프로토콜을 사용하여 구성 요소 간 통신을 수행합니다.

AXI 인터페이스를 정의하고 프래그마 문을 추가하는 과정에서 여기 그림에 표시하기에는 너무 많은 코드 줄이 생겼습니다. 전체 소스 코드 파일은 BittWare에서 확인할 수 있습니다.
자일링스 컴파일러의 상수는 인텔 바이트 순서(리틀 엔디안)이지만 네트워킹 프로토콜은 네트워크 바이트 순서(빅 엔디안)를 사용하기 때문에 엔디안 문제가 있습니다. 이는 성능이나 리소스 사용에는 영향을 미치지 않지만 모든 입력 데이터가 HLS에서 처리되기 전에 엔디안을 변경해야 합니다.
네이티브 프로그래밍과 HLS 비교: 결과
두 개의 FPGA RSS 구현이 있는 이유는 초기 버전이 Verilog로 작성되었기 때문입니다. 이는 우리가 평가하고 있는 가정, 즉 네이티브 FPGA 코딩이 항상 가장 적은 리소스를 사용한다는 가정 아래에서 발생했습니다. 그러나 BittWare 엔지니어는 이 결정에 이의를 제기하고 이 접근 방식을 테스트하기 위해 HLS로 RSS를 다시 구현했습니다. 그의 말이 맞았고 BittWare는 이제 SmartNIC 셸의 RSS 모듈과 파서 모듈을 HLS 코드로 대체했습니다.
두 가지 RSS 구현
| 특징 | Verilog | HLS C |
|---|---|---|
| CLB | 44,435 | 2,385 |
| BRAM | 12 | 1 |
| 레지스터 | 52,352 | 4,843 |
| 코드 라인 | 650 | 459 |
두 구현의 가장 큰 차이점은 Verilog/RTL 버전은 FIFO를 사용하고 HLS C++ 버전은 그렇지 않다는 점입니다. 모든 경우에 예상하지 못했던 리소스 사용량이 HLS로 전환하면서 실제로 감소하는 것을 보고 놀랐습니다.
시간 절약은 어떤가요? 대략적으로 말씀드리자면 네이티브 RTL 버전의 경우 한 달이 걸렸지만, HLS 코드는 일주일 만에 완료되었습니다.
인텔 HLS와 자일링스 HLS 비교
이 예제에서는 자일링스 HLS를 사용합니다. 그러나 상위 수준 언어 사용의 주요 장점 중 하나는 서로 다른 기술 아키텍처 간의 근본적인 차이점을 어느 정도 추상화할 수 있다는 점입니다. 인텔은 또한 C++를 게이트 RTL 코드로 컴파일하는 동등한 컴파일러를 보유하고 있습니다.
인텔 i++ 컴파일러를 사용하여 동일한 코드를 컴파일하려면 데이터 유형에 약간의 미묘한 변경과 #pragmas에 대한 변경이 필요합니다. 인텔과 자일링스의 가장 큰 차이점은 인텔의 경우 Avalon 스트리밍 인터페이스를 사용하고 자일링스의 경우 AXI를 사용한다는 점입니다. 이 두 인터페이스를 서로 변환하려면 간단한 심 인터페이스가 필요합니다.
공동 시뮬레이션
기능적으로 검증이 완료되면 사이클 정확도 RTL 시뮬레이션을 위해 공동 시뮬레이션 환경을 호출하는 것은 간단한 작업입니다. Vivado-HLS는 원본 C++ 코드에서 생성된 벡터에 의해 구동되는 RTL 테스트벤치를 자동으로 생성합니다. 사용자가 수정해야 하는 유일한 작업은 설계에서 무한 루프 또는 차단 인터페이스를 처리하는 것뿐입니다. RSS 모듈은 펌웨어 파이프라인의 일부로 무한히 실행되도록 설계되었습니다. 따라서 시뮬레이션이 완료되지 않고 공동 시뮬레이션이 중단됩니다. 이를 방지하기 위해 RSS 코드의 "while (1)" 메인 루프를 테스트벤치의 모든 입력을 소비하고 필요한 모든 출력을 생성할 수 있을 만큼 충분히 긴 고정 길이로 변경합니다.
공동 시뮬레이션은 툴을 통해 RTL이 올바르게 생성되었고 모듈의 타이밍 특성이 원래 설계 파라미터에 적합하다는 추가적인 확신을 줍니다.
공동 시뮬레이션 흐름은 인텔 HLS 툴 스택의 일부로도 사용할 수 있습니다.
IP 블록별 HLS 구축
HLS 도구 흐름에는 사용되는 인터페이스 프로토콜에 대한 인식 기능이 내장되어 있어야 합니다. BittWare의 IP 블록은 일반적으로 고급 확장 가능 인터페이스(AXI)를 사용하여 통신합니다. 구체적으로는 패킷 데이터를 전달하는 AXI4-Stream과 제어 플레인으로 AXI4-Lite가 있습니다.
100GbE의 경우, BittWare는 512비트 폭과 300MHz로 클럭되는 AXI4-Stream 인터페이스를 사용합니다. 각 패킷과 관련된 메타데이터는 패킷 데이터의 TLAST 신호가 어설트될 때 패킷이 끝날 때 유효한 자체 버스에서 이어집니다. 패킷 메타데이터는 블록 사이와 릴리스 사이에 진화합니다. 일반적으로 다음과 같은 정보가 포함됩니다:
- 패킷이 도착한 물리적 이더넷 커넥터의 번호입니다.
- MAC이 패킷과 관련된 오류를 식별한 경우
- 80비트 IEEE-1588 형식의 타임스탬프 또는 단축된 64비트 형식인 경우도 있습니다.
- 다음 기회에 스트림에서 패킷을 제거해야 함을 나타내는 "삭제됨" 비트입니다.
- 패킷의 목적지를 나타내기 위해 일반적으로 "대기열"이라고 부르는 숫자입니다. 파이프라인의 IP 블록 중 하나(이 블록일 수도 있음)에 의해 계산됩니다.
RSS 블록의 컨트롤 플레인에는 다음이 포함됩니다:
- 활성화/비활성화 비트
- 토플리츠 해시를 위한 16비트 키 20개
- 64개 항목의 방향 테이블
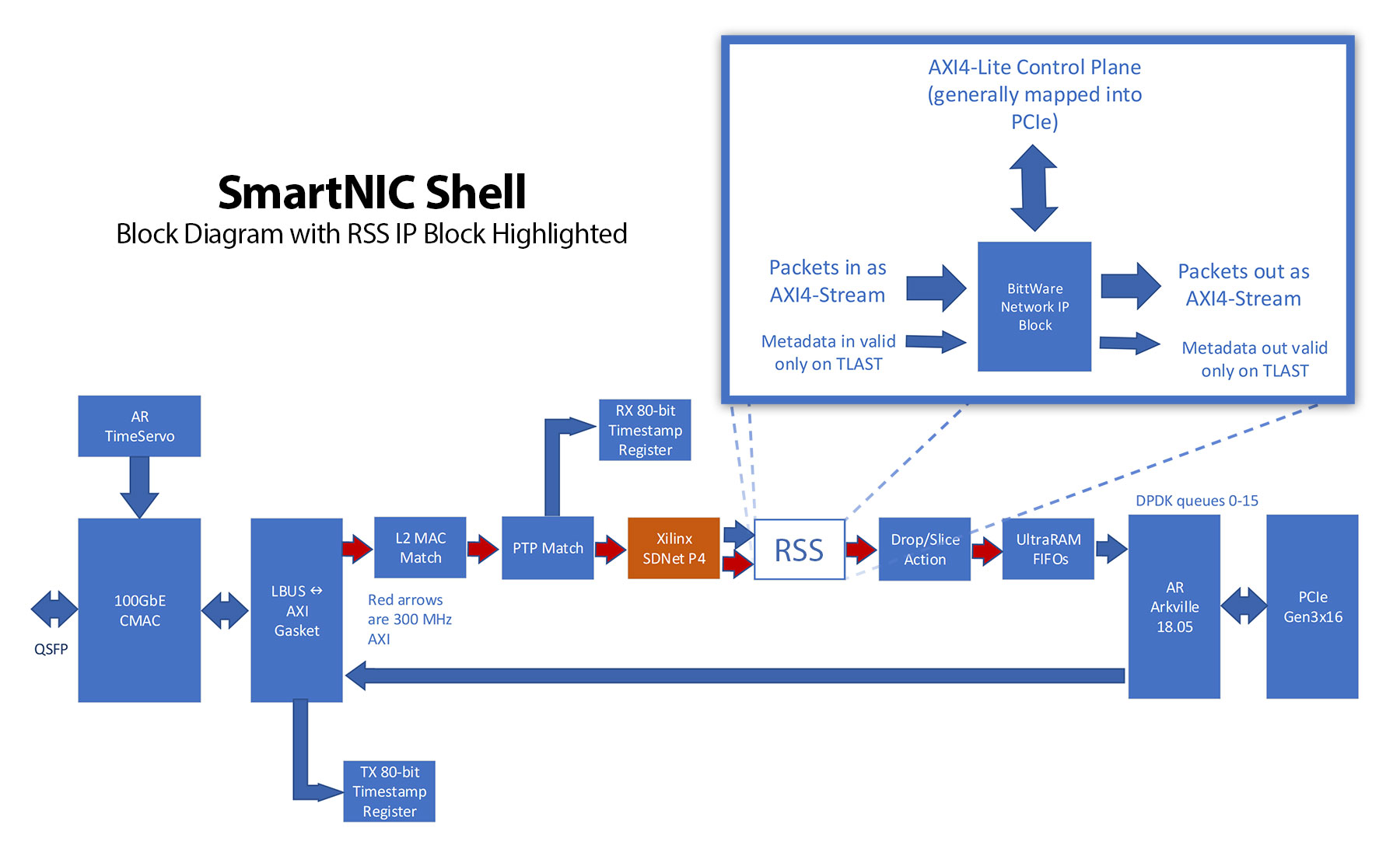
SmartNIC 셸 프레임워크의 예시 구현에 대한 SmartNIC 셸 블록 다이어그램. 여기서 RSS 블록은 HLS 구현으로 대체되었습니다.
결론
오늘날의 고급 FPGA 개발 툴은 시장 출시 기간을 단축하고 하드웨어 엔지니어에 대한 의존도를 낮추도록 설계되었습니다. 하지만 이러한 툴을 사용하면 속도나 실리콘 리소스 등 애플리케이션 성능이 항상 저하된다는 가정은 잘못된 생각입니다.
HLS를 사용하여 BittWare의 SmartNIC Shell용 IP 블록을 개발하면 개발 시간이 약 1개월에서 1주일로 단축되는 것을 확인했습니다. 또한 실제로 구현하는 데 더 적은 수의 게이트를 사용한다는 사실도 발견했습니다.
RSS 블록의 소스 코드는 XUP-P3R 보드 소유자 및 SmartNIC 셸 사용자가 사용할 수 있습니다. HLS 코드 내에서 AXI 인터페이스를 사용하는 방법에 대한 훌륭한 예시입니다. 자세한 내용은 비트웨어 담당자에게 문의하세요.
기본 개발 툴 외에도 모든 BittWare FPGA 보드에서 HLS를 사용할 수 있습니다. 또한 OpenCL 개발을 지원하는 다양한 보드도 제공합니다.자세한 내용을 보려면 여기를 클릭하세요.