
Intel® oneAPI™
High-level FPGA Development
Menu
Is oneAPI Right for You?
You may already know of oneAPI™ as a faster, easier way to develop hardware accelerators, particularly on Altera FPGAs. However, not every application is suitable, and often will take some initial development to establish baseline performance.
So, Where to Begin?
Could your application benefit from oneAPI™?
Staring with our enterprise-class accelerator cards is an excellent choice. Our cards with oneAPI support are shown below, along with details to get you started.
Want more details about oneAPI? Jump to our More About oneAPI section.
Ready to get hardware or have questions? Jump to our Where to Buy and Contact section.
A History of High Performance High-Level Tools

With decades of experience supplying high-level FPGA tools, we know what customers need from the start: a fast onramp to evaluate key performance metrics like F-max on your design. That’s why our standard Accelerator Support Package (ASP) is optimized for high-performance computing. Some key benefits of choosing a BittWare accelerator card supporting oneAPI as a starting point:
- Get to know key performance indicators like F-Max as a priority.
- Avoid starting with a large silicon resource footprint; add only the features you need through customization.
- You’re starting with deployable, enterprise-class hardware that you won’t need to change as you move toward deployment.
2D FFT Demo Using oneAPI
Develop faster + reuse code in this software-orientated tool flow
Explore using oneAPI with our 2D FFT demo no the 520N-MX card featuring HBM2. Be sure to request the code download at the bottom of the page!

Our Recommended Cards for oneAPI Development
We recommend these cards for oneAPI as we have the latest tools support, ASP (HPC focused), and each has a high-performance Altera FPGA.


Will Other BittWare Cards Work?
Our accelerator cards with Altera Agilex devices are all candidates for oneAPI support, however by not choosing a recommended card, building up an ASP to even evaluate performance will be a significant development project.
That’s why we recommend starting with these cards which have an HPC-optimized ASP ready for you. We can discuss other platforms for volume deployments.
Coming Soon: Agilex™ M-Series

Need the power of HBM2 memory for your oneAPI appliation? Our IA-860m will be added to our recommended card for oneAPI development. Contact us to get updated when it’s ready.
Accelerator Support Package (ASP)
In oneAPI terms, the ASP (formerly called the Board Support Package or BSP), is the inner ring that bridges your SYCL code and the card’s hardware. It’s what enables features, defines where oneAPI resides physically on the chip (floor plan), and really is the defining element of performance potential within the scope of a particular accelerator.
Did you know?
Performance is ASP-specific
The Accelerator Support Package (ASP) plays a big role in performance.
The ASP—your board vendor’s specific oneAPI implementation—defines how the oneAPI code interfaces with hardware resources on both the chip and card level. There are many variables which can result in lower or higher performance, more or less silicon resource usage, and I/O features available.
It’s important to consider your board vendor as much as it is choosing the right FPGA. That’s why BittWare focuses on high-performance oneAPI ASP development as a baseline–adding only features as required. Starting with a lower-performance (though perhaps with more features) ASP can result in less than ideal results that may mask how oneAPI would actually perform for you.
The BittWare ASP
Designed for Customization
Customers can customize for more features as required.
Should you need more features than our ASP provides, you’re already working with enterprise-class hardware that has additional I/O that can be enabled. Getting these resources enabled with oneAPI can be done with your own team, or talk to us about more customization options.
Need ASP Customization?
Contact us to get a quote or recommendation for getting a customized ASP that meets your project needs.
How do these terms relate?
OFS, FIM, AFU, and ASP
Related Terms: How OFS, FIM, AFU ASP work together
You may have heard several more terms related to oneAPI, the Open FPGA Stack (OFS) and FPGA Interface Manager (FIM), the Accelerator Functional Unit (AFU). How do these relate to the Accelerator Support package (ASP)? Why do you sometimes see a reference to a Board Support Package (BSP)?
OFS is the highest-order component, however it’s important to not think of oneAPI as comprising all that OFS offers. Such an implementation would not be resource-efficient and challenging to maintain. It’s better to consider OFS as a broad library of features, with a particular oneAPI implementation as offering a subset of these.
This is why, when comparing various “supports OFS” boards, that doesn’t give you much information on what features, performance, or resource usages are implemented. You’ve got to dig further into how the ASP (formerly called BSP) is implemented.
The next “level down” is comprised of the FIM—the FPGA Interface Manager. This defines the particular interface to hardware features, including those on the FPGA itself, and the oneAPI software. You can think of the FIM as an OFS-based shell. If you have RTL programming resources, you can add/remove features from the FIM.
Working “inside” of the FIM is the AFU, the actual algorithm or processing unit that provides acceleration. You can think of this as your user application space, with development using software tools but the advantages of hardware instantiation.
Lastly, the ASP brings together these components: hardware interfaces and how they interact with the oneAPI code plus host software tools like Quartus for development. You’ll see reference to a BSP (board support package) and oneAPI; this is a similar term for the ASP. The best way to think of the ASP is as the component that turns a FIM (with its user application AFU area) into a target for oneAPI.
Summary: Getting Started
What are the next steps? What’s the typical flow from development to deployment?
Evaluate
Choose the right card with a quality ASP.
Not all cards you see advertised with “oneAPI” are going to be suitable for evaluation. We’ve chosen to implement our ASPs on cards with Altera F-Series, I-Series, and soon M-Series Agilex FPGAs. Check out our list of recommended accelerator boards and are ready for a discussion on what’s the best fit for you.
Get the basics.
With hardware in hand, you’ll be using Altera Quartus Design Software (sold separately), and oneAPI tools. With BittWare, we have our Developer site to guide you as part of your accelerator board purchase.
Develop
Develop faster with oneAPI.
If you’re used to native RTL development, oneAPI will be a welcome improvement as full compile runs are reduced. Thanks to test bench emulation and reports, these steps are completed in seconds/minutes. Moving on to full compiles, you can use the Vtune to further refine your project.
Deploy
Good news if you started with a BittWare accelerator.
By starting with BittWare accelerators, your deployment can be on the same cards you’ve been using in development! Talk to us about volume requirements depending on your needs.
Learning More About oneAPI™
What is oneAPI?
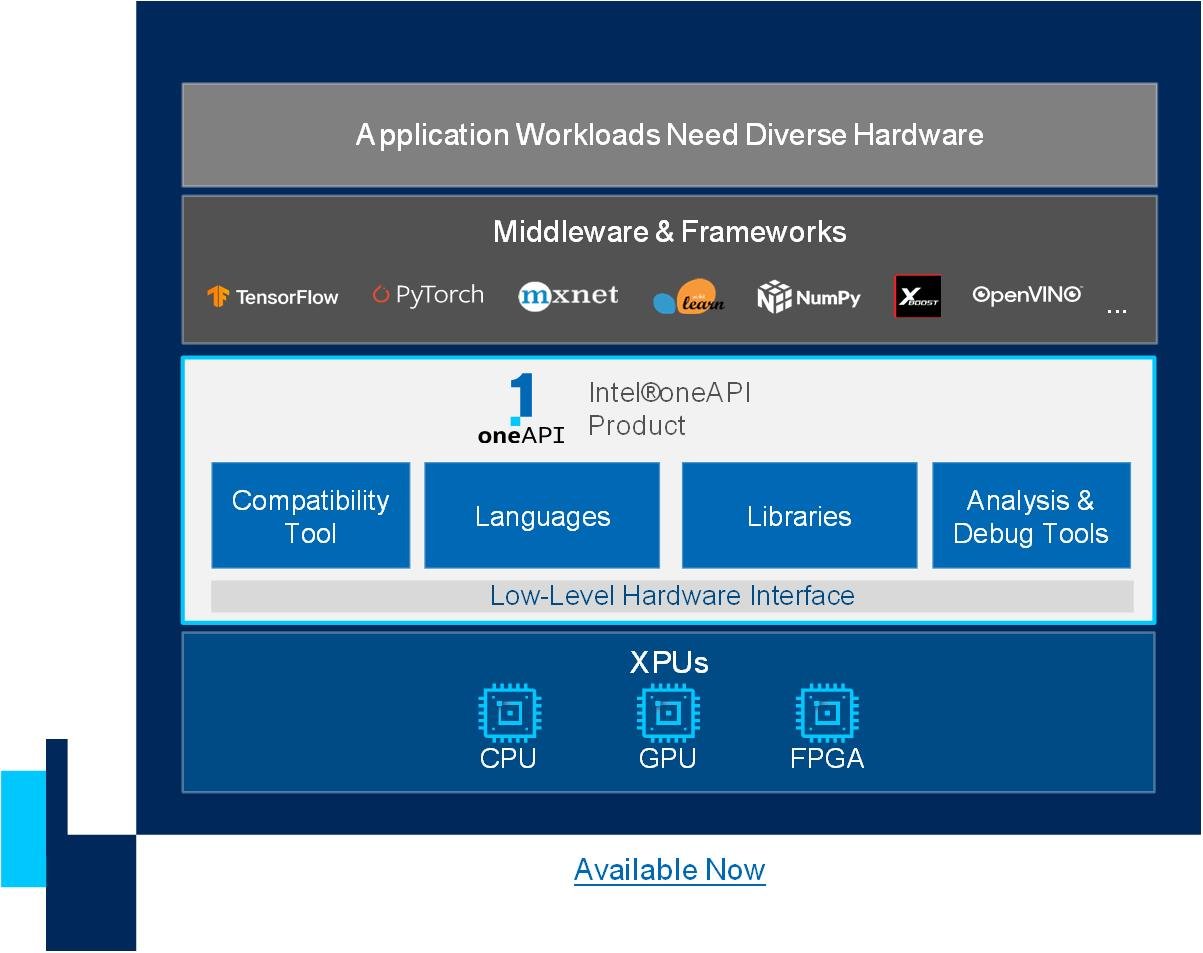
oneAPI is a cross-industry, open, standards-based unified programming model that delivers a common developer experience across accelerator architectures—for faster application performance, more productivity, and greater innovation. The oneAPI industry initiative encourages collaboration on the oneAPI specification and compatible oneAPI implementations across the ecosystem.
The Libraries
oneAPI provides libraries for compute and data intensive domains. They include deep learning, scientific computing, video analytics, and media processing.
The Hardware Abstraction Layer
The Specification
The oneAPI specification extends existing developer programming models to enable a diverse set of hardware through language, a set of library APIs, and a low level hardware interface to support cross-architecture programming. To promote compatibility and enable developer productivity and innovation, the oneAPI specification builds upon industry standards and provides an open, cross-platform developer stack.

FREE On-Demand Webinar
Using Intel® oneAPI™ to Achieve High-Performance Compute Acceleration with FPGAs
Watch immediately after registering!
Programming Challenges
For Multiple Architectures
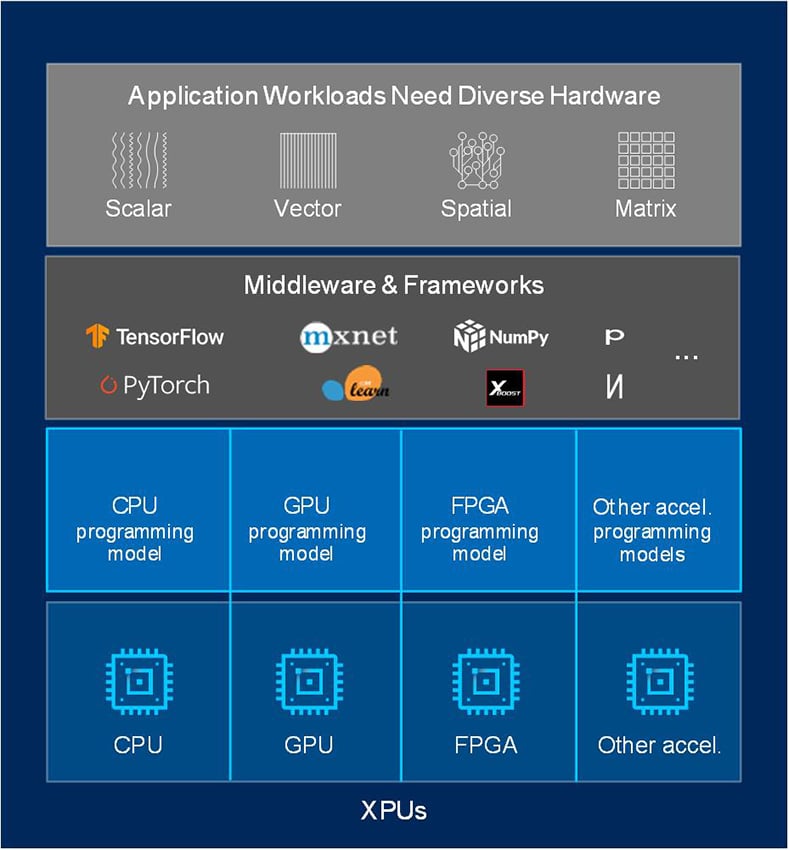
In today’s HPC landscape, several hardware architectures are available for running workloads – CPUs, GPUs, FPGAs, and specialized accelerators. No single architecture is best for every workload, so using a mix of architectures leads to the best performance across the most scenarios. However, this architecture diversity leads to some challenges:
Each architecture requires separate programming models and toolchains:
- Required training and licensing – compiler, IDE, debugger, analytics/monitoring tool, deployment tool – per architecture
- Challenging to debug, monitor, and maintain cross-architectural source code
- Difficult integration across proprietary IPs and architectures and no code re-use
Software development complexity limits freedom of architectural choice.
- Isolated investments required for technical expertise to overcome the barrier-to-entry
How oneAPI Can Help
OneAPI delivers a unified programming model that simplifies development across diverse architectures. With the oneAPI programming model, developers can target different hardware platforms with the same language and libraries and can develop and optimize code on different platforms using the same set of debug and performance analysis tools – for instance, get run-time data across their host and accelerators through the Vtune profiler.
Using the same language across platforms and hardware architectures makes source code easier to re-use; even if platform specific optimization is still required when code is moved to a different hardware architecture, no code translation is required anymore. And using a common language and set of tools results in faster training for new developers, faster debug and higher productivity.

- Performance tuning and timing closure through emulation and reports
- Runtime analysis via VTune™ Profiler
- Complex hardware patterns implemented through built-in language features: macros, pragmas, headers
- Code re-use across architectures and vendors
- Compatible with existing high-performance languages
- Leverage familiar sequential programming languages: improved ramp-up and debug time
- IDE Integration: Eclipse, VS, VS Code

Data Parallel C++
Standards-Based Cross-Architecture Language
The oneAPI language is Data Parallel C++, a high-level language designed for parallel programming productivity and based on the C++ language for broad compatibility. DPC++ is not a proprietary language; its development is driven by an open cross-industry initiative.
Language to deliver uncompromised parallel programming productivity and performance across CPUs and accelerators:
- Allows code reuse across hardware targets, while permitting custom tuning for a specific accelerator
- Open, cross-industry alternative to single architecture proprietary language
Based on C++:
- Delivers C++ productivity benefits, using common and familiar C and C++ constructs
- Incorporates SYCL* from the Khronos Group to support data parallelism and heterogeneous programming
Community Project to drive language enhancements:
- Extensions to simplify data parallel programming
- Open and cooperative development for continued evolution
FPGA Development Flow for oneAPI
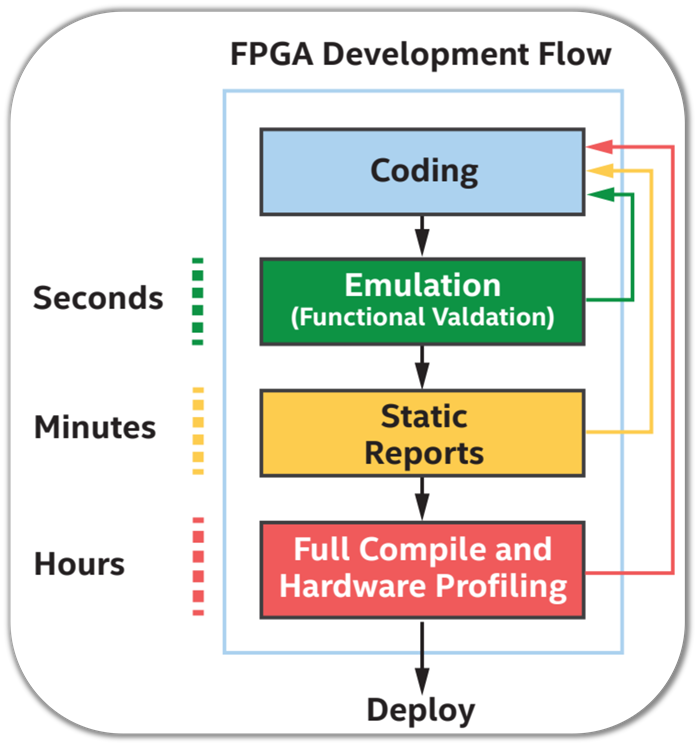
One of the main problems when compiling code for FPGA is compile time – the backend compile process required for translating DPC++ code into a timing closed FPGA design implementing the hardware architecture specified by that code can take hours to complete. So, the FPGA development flow has been tailored to minimize full compile runs.
- The first step is functional validation, where code is checked for correctness using a test bench. This is made using emulation on the development platform – where the code targeting the FPGA is compiled and executed on CPU. That allows for a much faster turnaround time when a bug is found and needs to be fixed. A standard CPU debugger (such as the Intel® Distribution for GDB) can be used for that purpose.
- Once functional validation is completed, static performance analysis is performed through compiler generated reports. Reports include all the information required for identifying memory, performance, data-flow bottlenecks in the design, as well as suggestions for optimization techniques to resolve the bottlenecks. They also provide area and timing estimates of the designs for the target FPGA.
- After the results of static analysis are satisfactory, a full compile takes place. The compiler can insert on request profiling logic into the generated hardware; profiling logic generates dynamic profiling data for memory and pipe accesses that can later be used by the Vtune performance analyzer for identifying data pattern dependent bottlenecks that cannot be spotted in any other way.
Interested in Pricing or More Information?
Our technical sales team is ready to provide availability and configuration information, or answer your technical questions.
"*" indicates required fields


