BittWare Partner IP
NVMe Bridge Platform
NVMe Intercept AXI-Stream Sandbox IP

Computational storage devices (CSD) allow storage endpoints to provide computational storage functions (CSF) to offload host processing and reduce data movement. Functions such as eBPF processing, encryption, compression, filesystem management, and RAID are ideally suited for IntelliProp’s NVMe Bridge Platform (NBP) IP Core.
The IntelliProp IPC-NV171B-BR NVMe Bridge Platform (NBP) utilizes the IntelliProp NVMe Host Accelerator Core and the IntelliProp NVMe Target Core to create an NVMe protocol bridge. The bridge is architected such that the command submissions, completion notifications and data transmissions may be either passed through without interruption or intercepted for analysis or modification. The architecture interfaces to a “Sandbox” area with an AXI Stream protocol so that IntelliProp customers may implement their own custom RTL and/or firmware in the bridge.
Key Features
Customizable sandbox with AXI-Stream interface
Up to 6200 MB/s PCIe Gen4x4
PCIe Switch Support for multiple SSDs
Marcus Weddle, BittWare
Welcome to our video focusing on FPGAs to accelerate storage, with a focus on a framework from IntelliProp called NVMe bridge platform.
With me today is IntelliProp’s CEO Hiren Patel. Thanks for joining me!
IntelliProp CEO Hiren Patel
Thank you, Marcus—glad to be here.
Marcus
Let’s start with the simple building blocks. So we’ve got SSD storage—so very fast storage—but instead of plugging that into, say, a host PCIe bus, we’re going to be putting an FPGA in the middle of that. So the first question is why would you do that?
Hiren
There’s probably several reasons, but an FPGA in front of an SSD allows for data capture—data acquisition systems—to be built that can store data directly onto the SSD and then read back from a host later on through the PCIe.
But again, there’s data acquisition you can preload. You can also, using the bridge, you can attack this new market that’s being explored nowadays—it’s growing—it’s computational storage.
We have the ability to offload certain accelerator features directly into the FPGA that that FPGA can then retrieve the data from the SSD, process it, push it back, or push it back to a host. So that’s probably the two biggest reasons right now.
Marcus
For data acquisition or data capture, what’s unique about using an FPGA? Because…there’s other data capture methods out there…so what’s unique about using an FPGA and then using this bridge framework?
Hiren
Yeah, great question again. In an FPGA—consider an FPGA like a blank canvas, right? So, with an FPGA we have a lot of interconnects. We have a lot of connection points where you can start to put other kinds of data acquisition, temperature sensors etc.—and you can start to take that data and throw it onto the SSD. That’s one of the main criteria.
The other criteria is you’ve got powerful processing built into the FPGA, you’ve got ARM cores nowadays you could put down multiple processors. You can do all kinds of processing on that data before it gets to the SSD.
A bridge in particular—why use the bridge? The bridge predominantly allows data to pass through, so it can allow writes to pass through, it can allow reads to pass through. But it can also intercept certain commands. It can intercept data as it needs to, so host could issue a command directly to the FPGA and let the FPGA then either go retrieve more data from the SSD, do what it needs to like searches, or some kind of acceleration function, and then push that data back. So there’s a lot of uses for the FPGA.
The other thing I’d like to say is that with an FPGA, because it is so customizable, you can actually take a single FPGA and build it in multiple products. You can take an FPGA in front of an SSD as a blank product and then you can attack different algorithms or a different acceleration.
One algorithm could be compression, the other one could be decompression, could be encryption. You could also do things like searches as well. These are all accelerator functions that are targeted to the specific need you have and not just one size fits all.
Marcus
So Hiren, you’ve introduced this concept now with the bridge component of the framework where you’ve got this host CPU being able to see the SSDs—even though they’re connected directly to FPGAs—and not the host PCIe bus. Now, there’s benefits to this—but does this require users to run special APIs or otherwise do they have to modify their software in order for all this to work?
Hiren
No, not out of the box. Out of the box with just the bridge platform in the shell, you can plug us in between a host PC and then an SSD. No, nothing needs to change. The host will actually enumerate the SSD as if it were directly connected.
Now, again, when you can start getting into the acceleration functions or data capture, you may need additional, you know, either drivers or you can do everything through vendor specifics. There are CLIs that allow you to send vendor specific commands directly into the bridge—the bridge can intercept these and then process the data as it needs.
Marcus
Now let’s talk about the specific BittWare hardware and performance. I think it’s important to note that there really aren’t that many FPGA cards on the market that can directly attach SSDs to the FPGA like we have with the BittWare IA-840f, which you can see here. We also have the advantage of the latest silicon from Intel with the Agilex FPGA on this card. So what are some of the benefits and metrics that these things can bring?
Hiren
Yeah, certainly. Obviously these newer FPGAs are pushing towards the faster and faster gen rates at PCIe. Today I believe these Agilex boards could get to Gen 4 with Gen 5 coming soon. And I think these boards—that’s a tremendous achievement in itself.
And then, again, with the bridge you get the Gen 4 x16 going towards the PC, and then on the backside—you’ve got the ability to aggregate multiple SSDs. Just using four SSDs at Gen4 x4 can help saturate some of that.
We can also put in eight drives at Gen 3 x4 lanes to help saturate that.
So we can have four drives back there, eight drives back there—we can have a lot of. But basically all that traffic goes through that FPGA—allows us to do either computational storage on it or data acquisition.
Marcus
What are some of those bandwidth figures? Let’s say you’ve got four drives connected to the FPGA or even the FPGA connects to a PCIe switch with eight drives—so what are some performance figures to expect at the Gen4 PCIe level?
Hiren
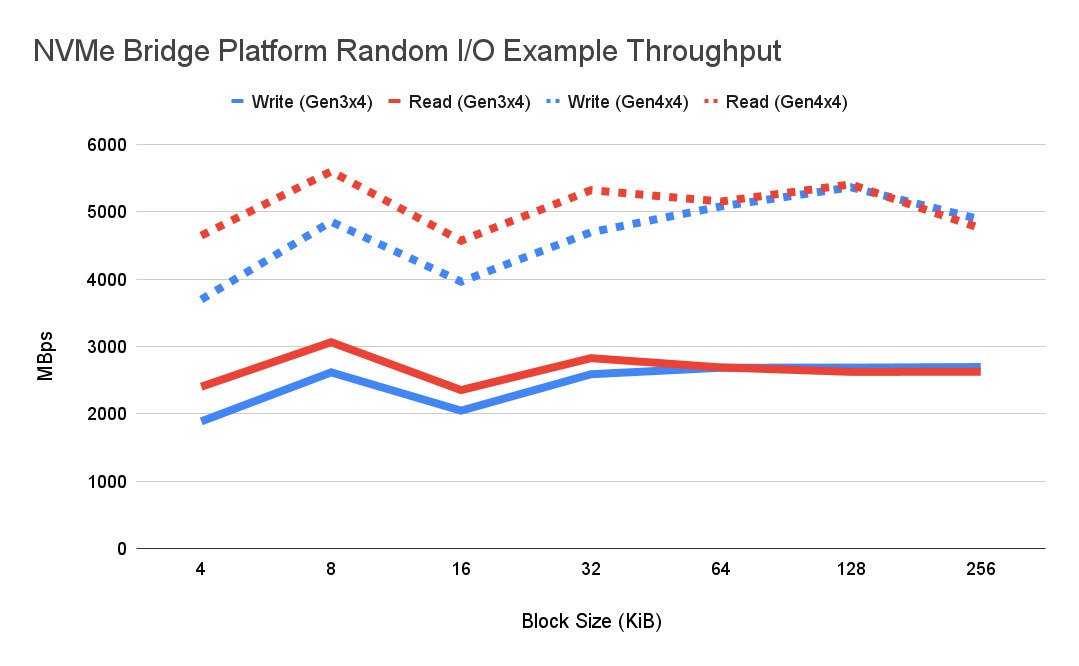
So at the Gen 4 level, I would suspect it—just on a single drive—I’m suspecting we should probably get closer to the 6,000 megabytes per second. At the Gen 3 rate, we’re already able to showcase our bridge running at over 3,000 close to 3,500 megabytes per second. I’d expect a doubling of that at Gen 4.
Marcus
And then another question that often comes up with people deploying FPGAs is how much of their own IP can they fit in the FPGA along with the Bridge IP? In other words, how much room do you leave for others? So could you just briefly speak to that…
Hiren
Yeah sounds great. On this particular board, I think there’s an AGF027 part in there. That part has, I’d say, probably about 900,000 ALEs/ALMs. We use about 100,000 for our bridge. That’s for a single drive connection. If you have multiple drive connections, you’d be adding about 4,000 ALMs to expand that.
So yeah, not too bad. Still, only about 10%. So customers still have a good amount of logic available to add their acceleration function.
Marcus
Hiren you mentioned you could connect one drive or multiple drives directly to the card. Now, if you wanted to connect more drives, and the card can physically connect like say eight drives—how exactly is that done?
Hiren
I think with even a single card, you might be able to get multiple drives connected and then you can also expand this into a backplane that might have a PCIe switch that can then get you to additional drives. So eight drives could be connected into a PCIe switch the PCIe switches then connected into the BittWare card. So I think that’s one possible solution or topology that’s capable here.
Marcus
Let’s go back to that second group of use cases that we had talked about—that’s where the FPGA is an inline accelerator. This is part of this bigger picture of computational storage acceleration and it’s becoming really popular for CPU offload. Can you talk me through some of those use cases for the inline accelerator for computational storage?
Hiren
Yes, certainly. So we’ve got a lot of customers that do today that do data-at-rest encryption. So our FPGA sits in front of an SSD or multiple SSDs and the customers using the sandbox areas we call it or the customer acceleration areas as data at rest encryption. But customers can also do search engines, search offloads, compressions eBPF is another growing area as well.
So those are some of those things that customers can do. If we take compression or decompression, as an example, one of the things you can do with our bridges—you can actually have the server or the host send compressed data through the bridge unaltered onto the SSD.
But when that data is retrieved, you could have a decompression hardware engine built into the FPGA. That decompression engine can then decompress the data before it’s sent on back to the server host, and I think that’s one use case that we see as well.
Other use cases like I said are eBPF and then and I know Intelliprop is working on some reference designs on that and so if there’s and you know that’s another use case that we see growing as well: eBPF virtual machines.
Marcus
The one use-case that you touched on earlier, but i wanted to hear more about, is having the host issue a search command—but then offloading the search itself to the FPGA and the direct attached SSDs. So how does this work how do you offload search because it’s a bit more complicated than offloading compression?
Hiren
Yeah, that’s a great question. One of the things we showcased at SuperCompute ’21 back in November in Saint Louis is we showed our inline bridge actually offloading search engines. So we had the CPU preload the SSD with a bunch of data. We had the server send a vendor specific command into the middle of the bridge where our RTL code saw the vendor specific command, got a range of LBAs or address space to go and do a certain pattern search—and we also received the pattern from the server. Once we receive the pattern and the range of LBAs to go search, we went off, read the entire drive section that we were supposed to read, looked for that particular 32-bit pattern, found all the instances of it—which LBAs that they occurred on—we package that up and sent a completion back to the server host.
Normally without our accelerator, the server would have read all that data into its system memory, done the search, and then throwing the data away. And without all that data movement it simply had to issue a command to us and we just sent back a response that said “Here’s all the locations we found it in.” The FPGA was honestly able to do that and much, much faster, and we had graph showing this as well.
Yeah so now we’re looking at some of that demo. The upper line is showing the CPU load running at roughly 90% while it’s doing its direct search but then in between that the FPGA offload version is of course many times faster and it’s offloading the CPU…and which FPGA are we using here?
So, yeah, that that demo in the video is done on a Intel Stratix 10 DX.
How can someone recognize when they need to use this particular framework IP with the bridge? How does someone recognize when they need that bridge component in particular?
Yeah, that’s a great question. Again, it’s a pass-through bridge. What we’ve done is we’ve eliminated all the NVMe complexity—we’ve created an AXI stream interface that customers can put their logic into. So, customers are good at doing the acceleration function—they’re experts at that—they might not be experts at NVMe and that’s where the framework really shines. We present the data and the commands and all of that as control and data information via AXI stream right into the middle and let the customers then decide what they want to do with that logic.
And then on the other side, we’ve got a control and data plane as well—AXI stream again—that continues to move that data onto the SSD.
It works in both directions, so in ease of use, it’s really where we shine. As customers—their expertise is on the acceleration function—they can then put that into the sandbox and away we go
It’s a lot shorter time to market. And with BittWare’s help on the BittWare board, we actually shorten that time even further. Because now they’ve got silicon they can actually plug the sandbox bridge into—the NVMe Bridge platform—and then now they’ve got a platform that they can continue to build their acceleration function on.
Marcus
Okay so building on that—and this is my last question—for viewers out there thinking about building this NVMe Bridge IP themselves versus using IntelliProp…how long did it actually take IntelliProp to make this and how easy is it now that you have it to build applications out using it?
Hiren
Yea, so sounds good. So this, again, is a framework we’ve kind-of, I’d just say that we’ve kind-of extrapolated out or hidden the fact that you’ve got to interact with NVMe. You don’t have to know anything about NVMe. You just need to know what addresses and control information you’re getting.
That bridge itself probably took us, IntelliProp, about a year and a half to develop and get right—to get the performance down that we wanted. Ultimately, we’re saving time for our customers.
Just as an example, going back to that SuperCompute ’21 demo we did, we did that in about a month. Without the bridge it would have taken us a lot longer. Just having the bridge, knowing the control information—the data information we were getting, took us a month just to really do the acceleration search function and the ability to send data back.
So again, it’s a framework, it’s all pre-built, it’s flushed out. You just have to focus in on your acceleration.
Marcus
Alright, excellent. Thank you for speaking with me today, Hiren, about all this—I appreciate it.
Hiren
Thank you.
Marcus
So that’s the NVMe bridge platform, a framework from IntelliProp that’s available on BittWare FPGA cards. Specifically, we look today at the IA-840F with direct attached SSDs. To learn more visit the BittWare website and thank you for watching.
Features
- Fully compliant to the NVM Express 1.4c industry specification
- Automated initialization with PCIe Hard Block
- PCIe switch support for multiple SSDs
- Automated command submission and completion
- Scalable I/O queue depth
- Decoupled front and back-end interfaces allows flexible user logic and applications
- Flexible data buffer type and size
- AXI Stream driven command and data paths
- Data Stream includes command parameters inline
- Support for block sizes from 512 byte to 4kB
- Application layer interface allows the processor to assume control or modify Admin commands
- Verilog and VHDL wrappers
NVMe Bridge Platform I/O Throughput
NVMe Bridge Platform IP Core Facts
Provided with Core
- Documentation: comprehensive user documentation
- Design file formats: Encrypted Verilog
- Constraints files: Provided per FPGA
- Verification: ModelSim verification model
- Instantiation templates: Verilog (VHDL wrappers available)
- Reference designs and application notes: Synthesis and place and route scripts
- Additional items: Reference design
Simulation tool used:
QuestaSim (contact IntelliProp for latest versions supported)
Support:
Phone and email support will be provided for fully licensed cores for a period of 6 months from the delivery date.
Notes:
Other simulators are available. Please contact IntelliProp for more information.
Block Diagram, Data Sheet and Product Details


Applications
The NBP IP can be used in Computational Storage Devices (CSD) or Computational Storage Arrays (CSA) with PCIe Gen4 to Host, and multiple PCIe Gen4 SSDs through a switch or separate PCIe connections.
Functional Description
The IntelliProp NBP, IPC-NV171B-BR, implements a protocol bridge by receiving and parsing commands via the IntelliProp NVMe Target Core and forwarding them to the IntelliProp NVMe Host Accelerator Core for delivery to the NVMe SSD Endpoint. Customizable bridging logic between these two cores facilitates command management, including forwarding and tracking outstanding commands and routing data accesses appropriately, while use of the “Sandbox” area provides visibility and flexibility into the buffered data as it is transferred between the Host and the Target.
Registers in the bridging logic provide firmware with a mechanism to control data movement, to manually issue individual commands, and to control status and behavior of the bridging function. A processor or other management agent is expected to receive and properly complete administrative commands from the NVMe Target Core, while I/O commands are executed autonomously by the bridging logic. As a result, the NBP provides transparency between the Host and the Endpoint SSD, while offering the designer flexibility in command and data manipulation.
Empty heading
Empty headi
Block Descriptions
NVMe Target Core
The NVMe Target Core is the standard release IntelliProp core (IPC-NV163A-DT), and defines hardware that works in conjunction with the PCIe core to implement a compliant NVMe device interface. The NVMe Target Core retrieves a command submission entry from the system host via the PCIe interface, and places the entry in one of many command FIFO’s. There are two data axi streams (full duplex), a command context stream and a completion context stream. Upon receipt of a command completion, the NVMe Target Core automatically populates internal fields and posts the completion to the Host system.
NVMe Command Accelerator
Automated internal state machines interact with the NVMe Target Core to fetch Submission Queue entries and post Completion Queue entries. Data and commands are presented to user logic via 4 AXI Stream interfaces. Upon receipt of an IO command from the NVMe Target Core, the NVMe Command Accelerator forwards the command via an AXI Stream, then interacts with the PCIe Endpoint Core to move data between the user system and the NVMe Host. Integrated registers allow user control of system configuration and core status.
NVMe Command Translator
Negotiates NVMe commands, data, and completions with the NVMe Command Accelerator via 4 AXI Stream interfaces. There are two data AXI streams (full duplex), a command context stream and a completion context stream. Upon receiving a command, this block allocates buffer space to accommodate the data transfer from the NVMe SSD, then forwards the command to the NVMe Host Accelerator for issuance to the SSD. Upon return of both data and the NVMe completion from the SSD, this block returns a completion to the NVMe Command Accelerator and deallocates buffer space. Integrated registers allow user control of system configuration and core status.
Sandbox
The user logic space in the NBP allows flexibility for users to insert custom logic between the NVMe Command Accelerator and Command Translator. This logic must comply with the standardized AXI Stream interfaces to transfer commands, completions, and data. Commands and completions may be either passed through directly, or modified (and tracked internally) at runtime. Data contains command parameters inline, and may therefore be dissociated from the corresponding command context. Without restrictions on data ordering or latency, user logic may take a variety of forms depending on the application.
NVMe Host Accelerator Core
The NVMe Host Accelerator Core is the standard release IntelliProp core (IPC-NV164A-HI), and implements hardware to build commands in a command queue and notify the NVMe SSD of the available commands via the PCIe Root Complex Core interface. The NVMe Host Accelerator Core has a hardwired interface to setup commands and retrieve completions. The AXI slave and NVMe Host Accelerator Core registers are also available to allow a microprocessor to setup command submissions and retrieve completions.
Empty heading
Empty heading
Detailed Feature List
Overall
- Complete off-the-shelf solution; operational out-of-the-box
- Supports multiple NVMe SSDs (or HDD) directly or via an included PCIe Switch
- PCIe Gen4 to Host, and multiple PCIe Gen4 SSDs through a switch or separate PCIe connections
- Sandbox with AXI Stream interface for Control and Data
- System attached processor for additional flexibility in computational functions
Sandbox Specific
- Four AXI Stream interfaces provide commands, completions, and data (full duplex including sideband metadata)
- Processor connections for additional flexibility
- Implement options include RTL or FW for acceleration
FPGA/Hardware Specific
- PCIe Gen4 hard blocks pre connected
- 6200 MB/s throughput maximum (Gen4x4 interface)
- Integrated with Intel Quartus 21.3 Pro tools
Synthesis scripts and timing constraints
Empty heading
Empty heading8
Supported FPGA Devices
| Device | Speed | ALUTs | FFs | M20k |
|---|---|---|---|---|
| Altera Agilex F-Series | -2 | 31674 | 22136 | 190 |
| Altera Stratix 10 DX | -1 | 31589 | 20038 | 190 |
Deliverables
The core includes everything required for successful implementation:
- Encrypted synthesizeable RTL code for IP core definition
- Encrypted ModelSim/QuestaSim simulation model
- Comprehensive user documentation
- Reference design
- Example simple reference project including:
- NVMe Host Accelerator IP core instance
- NVMe Target IP core instance
- NVMe Command Accelerator
- NVMe Command Translator
- Example Sandbox block
- Processor
- Memories
- Synthesis and Place & Route scripts
- Reference core control firmware
- Example simple reference project including:
Terms and Conditions
Modifications: Core modifications are generally not permitted to IntelliProp’s IP cores. Any modifications that are requested must be presented to IntelliProp to determine the plausibility of integrating such changes.
Support: Phone and email support will be provided for fully licensed cores for a period of 6 months from the delivery date.
Interested in Pricing or More Information?
Our technical sales team is ready to provide availability and configuration information, or answer your technical questions.
"*" indicates required fields