EdgeCortix Dynamic Neural Accelerator (DNA), is a flexible IP core for deep learning inference with high compute capability, ultra-low latency and scalable inference engine on BittWare cards featuring Agilex FPGAs.
Specially optimized for inference with streaming and high resolution data (Batch size 1), DNA is a patented reconfigurable IP core that, in combination with EdgeCortix’s MERA™ software framework, enables seamless acceleration of today’s increasingly complex and compute intensive AI workloads, while achieving over 90% array utilization.
 Complemented by the MERA framework that provides an integrated compilation library and runtime, this dedicated IP core enables software engineers to use the Bittware IA-840f and IA-420f FPGA cards as drop-in replacements for standard CPUs or GPUs, without leaving their comfort zone of standard frameworks like PyTorch and TensorFlow. DNA bitstreams for Agilex provides significantly lower inference latency on streaming data with 2X to 6X performance advantage compared to competing FPGAs, and better power efficiency compared to other general purpose processors.
Complemented by the MERA framework that provides an integrated compilation library and runtime, this dedicated IP core enables software engineers to use the Bittware IA-840f and IA-420f FPGA cards as drop-in replacements for standard CPUs or GPUs, without leaving their comfort zone of standard frameworks like PyTorch and TensorFlow. DNA bitstreams for Agilex provides significantly lower inference latency on streaming data with 2X to 6X performance advantage compared to competing FPGAs, and better power efficiency compared to other general purpose processors.
Marcus Weddle, BittWare
Hey this is Marcus with BittWare. What follows is a discussion with EdgeCortix on their machine learning framework, but I wanted to give a bit of background before we dive in.
We see artificial intelligence being talked about just about everywhere today, but this trend really only started in the last 10 years. The idea of using AI is obviously much older than this, so what happened to start this trend? The answer is hardware acceleration, specifically GPUs and FPGAs, and more recently, dedicated ASICs. These devices have really opened up the AI field for researchers developing new techniques and commercial applications to create demand.
And what’s most exciting is we’re really only in the middle of a long growth curve of improvement in AI techniques, hardware capabilities, and expanding use cases.
That being said, AI is a huge topic, so today we’re just focusing on machine learning at the edge—those use cases outside of the cloud or datacenter environment.
With edge devices, as we’ll see, efficiency is critical. That’s where EdgeCortix has focused, by harnessing some of the unique advantages of FPGAs to tailor to the workload plus highly adaptable software that, among other things eliminates retraining.
With me is the founder and CEO of EdgeCortix, Sakya Dasgupta. Welcome!
Sakya Dasgputa, PhD, founder and CEO of EdgeCortix
Thanks, Marcus looking forward to speaking with you.
Marcus
Let’s start by defining the Edge a maybe a little bit better by saying: why not do all the ML inferencing in the cloud or datacenter for example. Why even have to bother doing it at the edge?
Sakya
Absolutely. So purely using the cloud or data centers for deploying machine learning inference solutions is largely limited by five key challenges.
You can break this down across the cost required for processing information at the cloud. The second would be power or what we call power efficiency or energy efficiency. Third, biggest challenge would be in terms of the models. The complexity of these neural networks themselves.
4th critical challenge would be around the privacy of the data that you’re trying to preserve and processing information on the cloud. And then fundamentally you have a limitation on latency or bandwidth.
So let’s break that down a little bit further.
Cost
If you look at cost, a pure cloud native solution is limited by the large amount of cost incurred for not only the compute, but also for storing large amounts of data. And we’re talking about really petabytes of data in most cases.
If you look at the edge, 75% of almost all what you call interesting data for machine learning is residing directly at the cloud, close to what we call these edge devices or edge services. As such, moving all those data to the cloud and then processing and computing is a huge cost challenge.
Power Efficiency
Power and power efficiency becomes a bottleneck given that most of your systems on the cloud are kilowatts, if not more in terms of power consumption and machine learning or AI inference themselves largely consumes a lot of computer resources.
Model Complexity
The models, as I mentioned these are really complex, so most of these models were trained in the cloud. So fundamentally if you now try to take that complex model and bring that to the edge, there is a bottleneck in terms of limited resources on those devices. As a result, they’re not very well suited if you’re looking at a pure cloud based deployment.
Privacy
And then fundamentally if you’re moving all your data from let’s say, closer to edge and then moving back to the cloud, there is a susceptibility of losing privacy of your data for example in healthcare applications or other types of similar scenarios.
Latency
And then fundamentally moving large amounts of data as well as processing all of that on the cloud incurs a lot of latency. Most real time applications requires sub-seven to 10 milliseconds of processing. As a result, it would be a deal breaker if you’re doing a pure cloud native solution for almost all real-time requirement applications.
So those are fundamentally some reasons why restricting ourselves to purely a cloud-based solution machine learning would not be the ideal scenario.
Marcus
Yes that makes sense. I was reading about how you narrowed down to FPGAs as one of your deployment platforms—you used a process called co-exploration.
Can you walk me through that and then some of the specific benefits you found with FPGAs that make them well-suited for edge inference?
Sakya
Sure, that’s a great question, so when it comes to machine learning inference, especially if you look at deep neural networks, FPGAs themselves provide the great benefit of complete flexibility. You have the ability to completely change the behavior of the hardware platform when you look at neural networks with multiple layers, there is a lot of heterogeneity even within a single layer of a neural network, as well as if you are comparing across different networks.
Secondly, almost all this neural network computation is not centrally controlled like in case of a CPU. They are not very von Neumann, but rather contains multiple degrees of parallelism which can be best represented as a data flow graph.
As a result, this approach that we take, called co-design or co-exploration, it tries to balance the accuracy requirement of a typical neural network or a deep neural network versus the hardware metrics of interest like latency, memory, power, and we can really tailor-fit the processor architecture to make use of such inherent parallelism, which would then effectively enable us to increase the complete utilization of the hardware significantly better in most cases. And especially if you’re comparing them to general purpose processors like GPUs or CPUs.
So we, as a company, we took that approach and designed dynamic neural accelerator IP as well as the MERA software inherently hand-in-hand using this co-design approach.
Also, fundamentally, if you use the same approach, we can also balance the trade-off between what you would call precision or the resolution at which you are processing information needed for preserving high accuracy of these different models while also reducing the memory footprint of the models, such that they can be optimally fit on a limited amount of memory that you would have inherently on chip the FPGA. This is really how we settled on INT8 bit as being the tradeoff between optimally performing the inference at an accuracy that matches or, you know you can preserve the accuracy significantly to what you had originally, as well as you are optimizing the amount of memory that you will require directly on board and then limit your operations to be not bounded by the amount of data transfer that you would do going off-chip from the FPGA.
As a result, overall, FPGAs provide a good balance between the flexibility to adjust the processor design and control this compute efficiency driven by such a co-design or co-exploration process.
Marcus
Would you see, as workloads change or other hardware features might include dedicated DSP blocks for example that would sway you away from INT8 in the future?
Sakya
Yeah, absolutely. So you know when we started this process, it’s not like INT8 bit representation is the only precision that we currently support. There is essentially a different range of precisions that are supported by our architecture, namely in floating point 16, INT8 bit—and that can vary between the representation for your weights or parameters of the neural network versus also the precision that you would use for storing the activations.
Fundamentally, this co-design process is really a living process that continues throughout the deployment phase.
Fundamentally, if you’re doing the co-design, you can’t change the processor architecture any further. However, even during, for example, cases where your neural network model is changing or there are updates happening, you can redesign certain aspects of your processor architecture to better fit accuracy, latency requirements.
The benefit of FPGA, going back to your previous question, is that we now have the flexibility of changing the processor architecture if you would like. Whereas if you take ASICs or other such types of hardware which are purely fixed—once you fabricate or manufacture them—you don’t really have that level of flexibility anymore.
Marcus
Now let’s talk about some specific hardware. BittWare has the EdgeCortix IP and software together as a framework available on our Intel Agilex-based cards. Can you give some insight on how Agilex performs, and do you see advantages to the expanded PCIe Gen4 bandwidth?
Sakya
Absolutely. We see a ton of advantages combining our AI acceleration IP with the new Intel Agilex cards. Especially if you look at the support of two form factors of BittWare double-width FPGA cards and also the low-profile FPGA card, it enables the user to ideally choose between compute, power, and cost, especially if you’re bundling them with TeraBox servers. This should enable FPGA acceleration to be deployed even in the more challenging harsh environments demanded of edge applications in specific.
Fundamentally, the Intel Agilex is latest generation silicon from Intel. Each of these FPGAs have hardened PCIe protocol support that saves critical FPGA resources and power, which can be really important for many applications where AI is coexisting with other types of FPGA acceleration.
If you also look at the Intel Agilex they are based on the second-generation HYPERFLEX architecture. This brings hardened DSP blocks that, in our case, allowed us to fit thousands of INT8 operators and a unified structure that can easily scale the IP.
Moreover, the PCIe Gen 4 support on these FPGA cards essentially enables us to have more than 30% improvement as compared to the bandwidth that is available on previous generation—PCIe Gen 3 for example. This can have a very strong impact on machine learning inference, wherein we are largely moving really high-resolution data from the host to the FPGA and back and forth quite often. As a result, having more bandwidth available—so rather increasing the speed—can have a dramatic impact on the overall efficiency or performance.
And then fundamentally, there is also sufficiently large amounts of memory that is available in terms of DDR4 support. If you look at the double-width FPGA card we have, I believe, up to 128 gigabytes, which if you couple that with the relatively large amounts of on-chip BRAM on these FPGAs itself, this should provide really good scalability options for many applications.
Overall, when we looked at the Intel Agilex and fit our IP, this has really enabled us to fit up to 20 trillion operations, or 20 TOPS of dedicated AI compute, which we believe enables us to bring 6X better performance advantage using our IP on these cards as compared to other competing FPGA acceleration solutions in the market today.
Marcus
Okay Sakya so now we’re looking at that graph that compares the BittWare cards to some of the other solutions. You’ve got the low-profile IA-420F card at 6-7X better and then the IA-840F even higher. It’s very impressive. We see a GPU on this chart—and you had mentioned 20 TOPS you’re getting on Agilex now—I know in the past you’ve said there’s a difference in how the TOPS on a GPU is utilized. What is that difference exactly and how do we better compare performance apart from just stating TOPS?
Sakya
Sure, absolutely. That’s another great question. So if you compare TOPS in general, it’s not completely representative of the overall performance of the FPGA or any compute processor for that matter.
So for example, if you take two devices in this case—an FPGA with 20 TOPS in this case—our DNA IP-enabled 20 TOPS BittWare FPGA vis-à-vis a GPU that has 20 TOPS.
Fundamentally, GPUs are not very good users of the total amount of compute that’s available on them. We call this utilization.
Most modern GPUs, even CPUs, are using somewhere around 20% to 30% at max, in terms of the overall compute that’s available.
So if you have 20 TOPS, you’re really just scratching the surface in terms of 20% of that being utilized at any given point in time.
If we now compare that to the DNA IP-enabled FPGAs—because of the runtime reconfiguration capability that we have on our IP—it enables us to utilize nearly 90% of the compute, in this case 90% of the 20 TOPS is being utilized for any given AI workload or application.
As a result, the efficiency—the frames per second per watt—based on that utilization, is significantly higher using our solution as compared to an equivalent GPU or FPGA solution.
Marcus
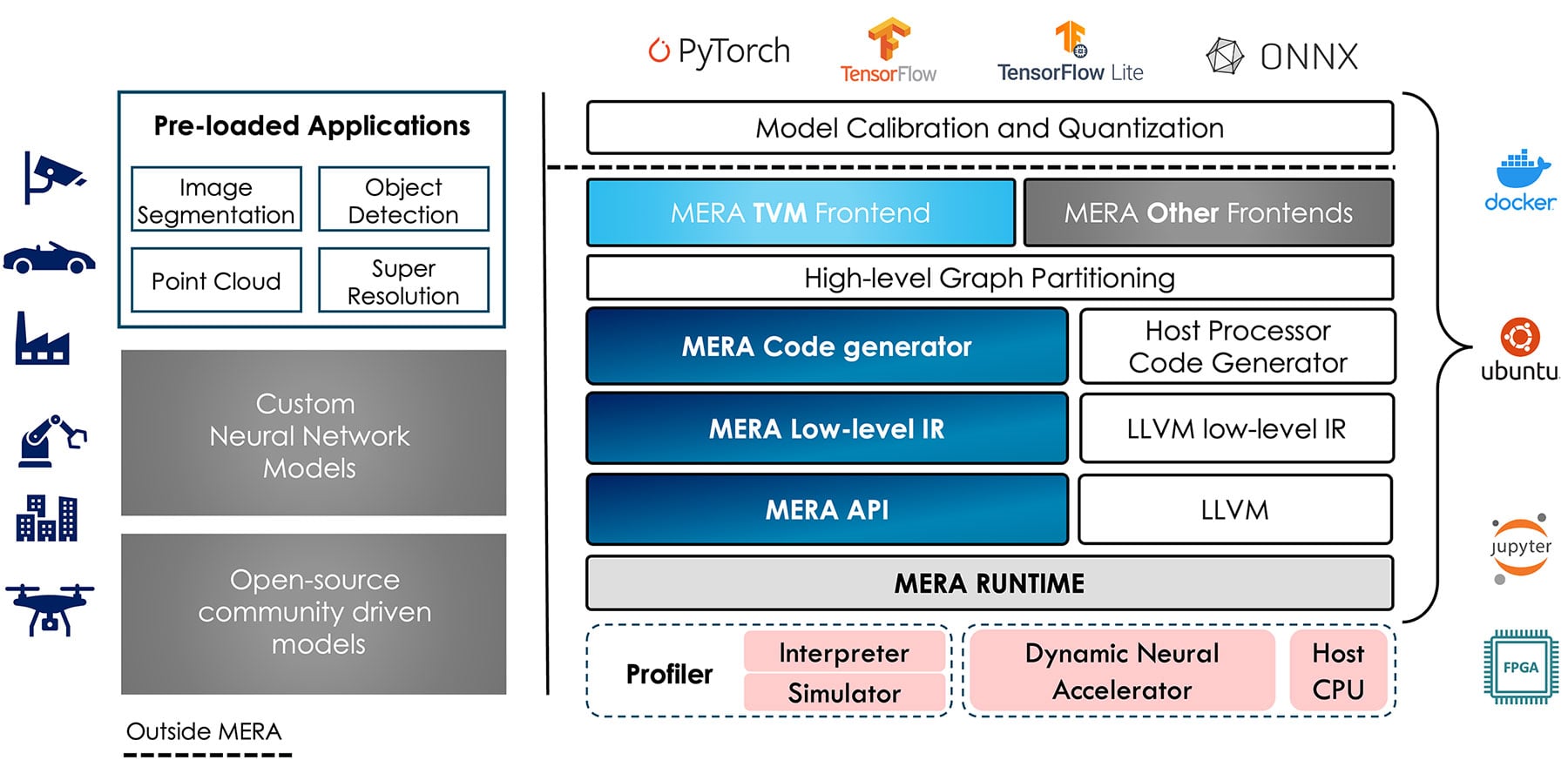 Okay thanks for that clarification on TOPS. So I wanted to now talk about the MERA software. As you said, the IP running on the FPGA is called DNA, which provides very high efficiency, but the MERA software itself gives significant time-saving advantages like using standard frameworks, and not requiring re-training if you were coming from a GPU for example. Can you elaborate on some of these software advantages in MERA?
Okay thanks for that clarification on TOPS. So I wanted to now talk about the MERA software. As you said, the IP running on the FPGA is called DNA, which provides very high efficiency, but the MERA software itself gives significant time-saving advantages like using standard frameworks, and not requiring re-training if you were coming from a GPU for example. Can you elaborate on some of these software advantages in MERA?
Sakya
Yes, that’s right. So we designed the MERA framework with flexibility of really machine learning engineers in mind that does not require any FPGA-specific skill, which has really been a pain point in using FPGAs for AI acceleration.
As a result, one of the fundamental benefits of MERA is a nearly plug and play environment that:
First, allows us to port any existing deep neural network application which was already pre trained—let’s say on a GPU—seamlessly to this FPGA enabled with the DNA IP without any retraining or architectural changes being required.
Second, MERA can be installed using a public PyPi repository, which means anybody with access to essentially pip can be able to download, or rather, is enabled, is able to download MERA directly on that device which has the FPGA running on it, and then it would come with built-in support for Python or C++, and also it natively supports all the major machine learning frameworks like Pytorch, TensorFlow, and TensorFlow Lite.
Third, it also has built in support for open source Apache TVM, which is really a very popular deep learning compiler. This enables users to deploy any pre-trained deep neural network model after a simple calibration and quantization step while staying completely within the machine learning framework of choice.
There is essentially no need for our IP-specific model, quantization or pruning.
Now that’s a huge advantage compared to either competing solutions or other such infrastructures with FPGAs as well as application-specific hardware.
Given that almost all such processes require certain level of fine tuning, which are very hardware specific, by eliminating that complete aspect we are giving a lot more autonomy to the machine learning engineers to really seamlessly transfer their code that they know already works in a GPU.
Fourth, there is a diverse support of deep neural network operators. As such, most modern DNNs or deep neural networks can be deployed out of the box. And we are also providing a pretested collection of 50 plus models across different applications that a user can play with.
Fifth, there is also provision for what we call profiling tools like a built-in simulator interpreter that enables the user to test performance very quickly without having to actually deploy the solution on the FPGA itself. This enables them to confirm both the model accuracy as well as estimate performance relatively quickly.
So those are some of the benefits, I would say, of MERA as a framework.
Marcus
Okay we’ve covered hardware. We’ve covered software. Let’s get to some use cases, and I wanted to talk through a couple of them which I found interesting. First of all is super resolution. What is it and how does the EdgeCortix framework perform with this?
Sakya
Sure. So if you look at super resolution, that’s really the ability to increase or even decrease the resolution of an image or a video frame drastically.
You’re talking about going from, let’s say, something that is as small as 360p—so you have a very small resolution of pixel density and going to a very high resolution like 4K. That’s a huge jump in resolutions, or vice versa—reducing resolution from 4K to 360p.
Applications that require such ability to move between resolutions or applications that want you to preserve bandwidth. For example, if you are performing certain streaming applications with video, you may want to preserve the bandwidth by going down to a lower resolution, transmitting the data, and then reclaiming the resolution at the user’s end.
Traditionally, to do super resolution you would use classical methods that are very lossy. As a result, you would lose a lot of the information—content of the image—resulting in pixelation when you’re going from a very small resolution to high resolution.
Using neural networks that were trained on these images and videos, in order to be able to extrapolate that information content, we can preserve majority of that information in our largely lossless manner.
As a result, that extrapolation allows us to preserve a lot of the information without the level of pixelation that you would see in classical non-machine learning based methods.
In case of EdgeCortix’ framework, we are able to run these relatively complex super resolution models directly on the FPGA with very high resolutions.
As a result, we can go from small 360p or 480p resolution directly to 4K within milliseconds, enabling us to transmit large volumes of data for video streaming applications.
Marcus
That’s excellent. I think that’s a great example of being adaptable to new applications for AI. Another use case that may be of interest is using sensor data that might not be image based. This is where you can actually fingerprint radio frequency data, using AI to predict things like location or identifying a device. Tell me more about how this works.
Sakya
So that’s an interesting question. In general, we have seen multiple applications spanning across both defense communications as well as for consumer applications that requires us to identify the source of where data is being generated or where information is being transmitted from. And typically, you do that using what we call radio frequencies. And, just like humans have fingerprints, you can now capture the radio frequencies and then create essentially unique fingerprints of where that data is being generated from. It could be a router, it could be a cell phone tower. It could also be a single cell phone. As a result, we can now take all of this data, convert those to images and then train a deep neural network, in this case convolution neural networks, that can identify those unique features, and in most cases classify whether that device is a real device. For example, if it’s a known device, it can also classify or localize where that information is originating form.
Having that ability to perform or really process such neural networks on the FPGA opens up the field in terms of different types of application spanning across infrastructure edge as well as in defense or communications, which requires very specific localization or identification as well as authentication of sources of where signals are being generated.
So absolutely it’s a growing field and we are seeing a lot of applications spanning across both defense and consumer sectors.
Marcus
It’s great to see these emerging use cases, and so my last question continues that—what’s next for edge AI? Do you see continuing iterations of co-exploration as hardware or use cases change or emerge? How do you balance the tradeoffs of flexibility versus efficiency at the edge?
Sakya
Yeah, so that’s a great question and you know, absolutely, I think the field is completely open. We are just starting to scratch the surface in terms of beginning with co-designing our neural networks, vis-à-vis the hardware platform that it’s going to run on. Especially FPGAs, going back to the original question, provides the right substrate of flexibility in order for us to fine tune certain aspects of the processor architecture if we don’t get it right in the first place.
At the same time, there are new types of models that are completely being invented continuously. Previously, convolutional neural networks were very very hot for videos and images. We now have models like transformers that are slightly different from those convolution models. As a result, you would want to have a tighter integration and fit between different generations of these neural networks that we know works better at a given point in time versus the hardware platform that it’s going to run on.
You really don’t want a one size fits all kind of scenario. You want a lot of flexibility of the substrate that you’re going to run this on versus the neural network’s features or degrees of parallelism.
Overall, the tradeoff between flexibility and efficiency is something that you know is continue to live for a very long time. Especially if you think about the edge—given that you always have limited resources, there are constraints of power, there are constraints, in many cases, of mobility—the only real knob or handle that we have to turn to increase our performance is of efficiency or resource management.
So as a result I see this whole area of co-exploration to be something that is only going to grow further from here.
Marcus
All right Sakya we’ve covered a lot of ground—thank you so much for speaking with us.
Sakya
Thanks Marcus, it was a pleasure. Thank you.
Marcus
Thanks for watching our discussion with the CEO and founder of EdgeCortix, Sakya Dasgupta.

