BittWare パートナーIP
NVMeブリッジプラットフォーム
NVMeインターセプトAXI-StreamサンドボックスIP

コンピューテーショナル・ストレージ・デバイス(CSD)は、ストレージ・エンドポイントがコンピューテーショナル・ストレージ機能(CSF)を提供し、ホスト処理をオフロードしてデータ移動を削減することを可能にします。eBPF処理、暗号化、圧縮、ファイルシステム管理、RAIDなどの機能は、IntelliPropのNVMe Bridge Platform (NBP) IP Coreに理想的に適合しています。
IntelliProp IPC-NV171B-BR NVMeブリッジプラットフォーム(NBP)は、IntelliProp NVMeホストアクセラレータコアとIntelliProp NVMeターゲットコアを利用して、NVMeプロトコルブリッジを作成することができます。このブリッジは、コマンド送信、完了通知、データ転送を中断せずに通過させるか、解析や変更のために傍受することができるように設計されています。このアーキテクチャは、AXI Streamプロトコルの "Sandbox "エリアにインターフェースされており、IntelliPropの顧客は独自のカスタムRTLやファームウェアをブリッジに実装できます。
主な特徴
AXI-Streamインターフェースによるカスタマイズ可能なサンドボックス。
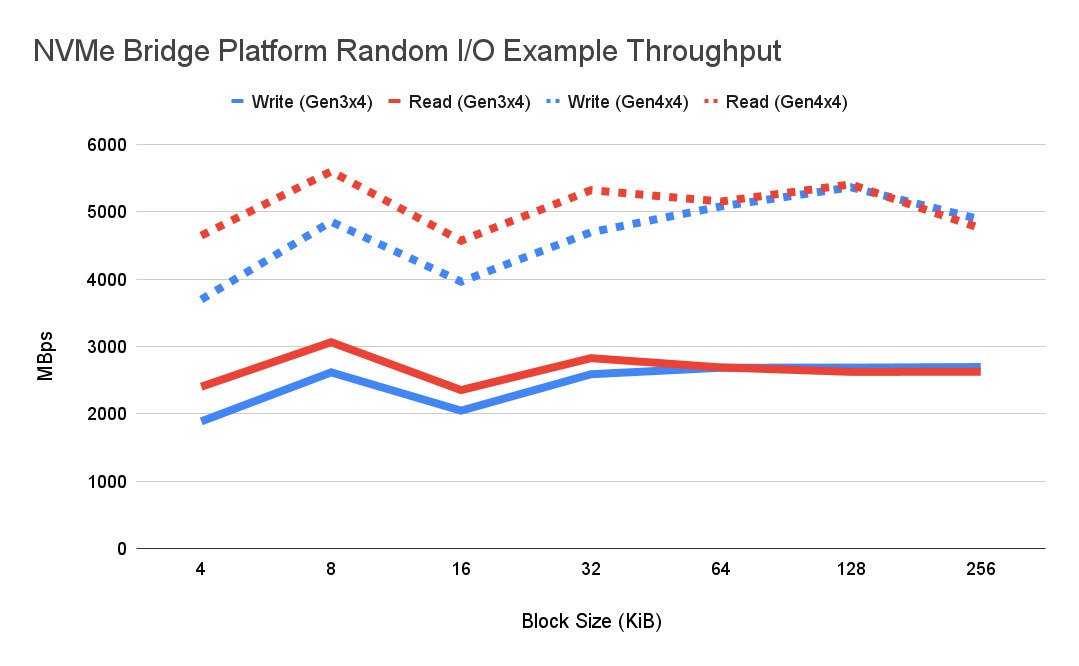
最大6200MB/s PCIe Gen4x4
PCIeスイッチ複数のSSDに対応
マーカス・ウェドルBittWare
IntelliProp社のNVMeブリッジプラットフォームと呼ばれるフレームワークを中心に、ストレージを高速化するFPGAに焦点を当てたビデオにようこそ。
今日はIntelliPropのCEOであるHiren Patelが一緒です。ご出席ありがとうございます!
インテリプロップCEO ヒレン・パテル
ありがとうございます、マーカス-嬉しいです。
マーカス
まずはシンプルなビルディング・ブロックから始めましょう。SSDストレージは非常に高速なストレージですが、これをホストのPCIeバスに接続するのではなく、その真ん中にFPGAを配置することになります。最初の疑問は、なぜそんなことをするのか、ということです。
ヒレン
SSDの前にFPGAを配置することで、データを直接SSDに保存し、後でPCIeを通じてホストから読み出すことができるデータ収集システムを構築することができます。
しかし、ここでもプリロード可能なデータ収集があります。また、ブリッジを使用することで、現在開拓されている新しい市場(成長中)である計算ストレージを攻撃することもできます。
ある種のアクセラレータ機能をFPGAに直接オフロードすることができ、FPGAはSSDからデータを取得して処理し、それをプッシュバックしたり、ホストにプッシュバックしたりすることが可能です。これが今、最も大きな2つの理由です。
マーカス
データ収集やデータキャプチャにおいて、FPGAを使用することの特徴は何でしょうか?なぜなら...データ収集の方法は他にもありますから...FPGAを使い、さらにこのブリッジフレームワークを使うことの特徴は何でしょうか?
ヒレン
またまた、いい質問ですね。FPGAでは、FPGAを真っ白なキャンバスのように考えることができますね。FPGAにはたくさんのインターコネクトがあります。他の種類のデータ収集や温度センサーなどを設置するための接続ポイントがたくさんあり、そのデータをSSDに取り込むことができるのです。それが主な基準のひとつです。
もうひとつの基準は、FPGAに強力なプロセッシングを組み込んでいることです。SSDに入る前のデータに対して、あらゆる処理を行うことができるのです。
特にブリッジは、なぜブリッジを使うのでしょうか?ブリッジは主にデータの通過を許可するもので、書き込みを許可したり、読み込みを許可したりします。しかし、特定のコマンドを傍受することも可能です。ホストからFPGAに直接コマンドを発行し、FPGAがSSDからさらにデータを取得したり、検索やアクセラレーション のような必要な処理を行い、データをプッシュバックすることができるのです。このように、FPGAにはさまざまな使い道があるのです。
FPGAはカスタマイズが可能なため、1つのFPGAを複数の製品に組み込むことができます。FPGAをブランク製品としてSSDの前に置き、異なるアルゴリズムや異なるアクセラレーション を攻撃することができるのです。
あるアルゴリズムは圧縮で、もう一つは解凍で、暗号化かもしれません。また、検索のようなことも可能です。これらはすべて、特定のニーズに的を絞ったアクセラレーター機能であり、一長一短ではありません。
マーカス
Hiren氏は、フレームワークのブリッジコンポーネントで、ホストCPUがSSD(SSDはFPGAに直接接続されているが、ホストPCIeバスには接続されていない)を見ることができるというコンセプトを紹介されましたね。これにはメリットがあると思いますが、これを実現するために、ユーザーは特別なAPIを実行したり、ソフトウェアを変更する必要があるのでしょうか?
ヒレン
いいえ、箱から出して使うわけではありません。ブリッジ・プラットフォームをシェルに組み込んだだけで、ホストPCとSSDの間に私たちを差し込むことができます。いいえ、何も変更する必要はありません。
さて、アクセラレーション 機能やデータキャプチャに着手する場合、追加のドライバが必要になることがあります。CLIがあり、ベンダー固有のコマンドをブリッジに直接送信することができ、ブリッジはこれをインターセプトして、必要なデータを処理することができます。
マーカス
では、具体的なBittWare のハードウェアとパフォーマンスについて説明します。BittWare IA-840fのようにSSDをFPGAに直接取り付けることができるFPGAカードは、市場にはそれほど多くないということは重要なことだと思います。また、このカードに搭載されているAgilex FPGA は、Intel の最新シリコンを採用しているのも特徴です。では、こうしたものがもたらすメリットや指標にはどのようなものがあるのでしょうか。
ヒレン
ええ、もちろんです。これらの新しいFPGAは、PCIeの高速化、高速化に向かっているのは明らかです。現在、Agilex のボードはGen4まで到達し、Gen5も間もなく登場すると思われます。このようなボードは、それ自体が驚異的な成果だと思います。
さらに、ブリッジを使用すれば、Gen4 x16をPCに接続し、裏側には複数のSSDを集約することができます。Gen4 x4で4台のSSDを使用するだけで、その一部を飽和させることができます。
また、Gen3 x4レーンに8台のドライブを搭載して飽和させることもできます。
。つまり、後ろに4台、後ろに8台と、たくさんのドライブを搭載することができます。しかし、基本的にはすべてのトラフィックがFPGAを経由するため、計算ストレージやデータ収集が可能になります。
マーカス
帯域幅の数値はどのようなものですか?例えば、FPGAに4台のドライブを接続し、FPGAが8台のドライブを搭載したPCIeスイッチに接続する場合、Gen4 PCIeレベルではどのようなパフォーマンスが期待できるのでしょうか。
ヒレン
ですから、Gen 4のレベルでは、1台のドライブで6,000メガバイト/秒に近づくのではないかと考えています。Gen3では、すでに3,000メガバイト/秒から3,500メガバイト/秒を超える速度で動作するブリッジを展示することができます。Gen 4では、その2倍になると期待しています。
マーカス
そして、FPGAを導入する際によく出てくるのが、Bridge IPと一緒に自社のIPをどれだけFPGAに入れられるか?言い換えれば、どれだけのスペースを他の人のために残すことができるのでしょうか?それについて簡単に説明してください。
ヒレン
ええ、素晴らしい音です。このボードには、AGF027という部品があると思うんです。その部品は、おそらく約90万個のALE/ALMを搭載していると思います。私たちはブリッジに10万個ほど使っています。これは、1つのドライブ接続の場合です。複数のドライブを接続する場合は、約4,000個のALMを追加して拡張することになります。
そうそう、悪くはないんだけどね。それでも、10%程度です。つまり、顧客は、アクセラレーション の機能を追加するために、まだ十分な量のロジックを利用することができるのです。
マーカス
Hirenさんは、1台のドライブまたは複数のドライブをカードに直接接続できるとおっしゃっていました。もっと多くのドライブを接続したい場合、カードは物理的に例えば8台のドライブを接続することができますが、それはどのように行うのでしょうか?
ヒレン
カード1枚でも複数のドライブを接続できるかもしれませんし、バックプレーンに拡張してPCIeスイッチを搭載し、さらにドライブを追加することも可能です。つまり、8台のドライブをPCIeスイッチに接続し、PCIeスイッチからBittWare カードに接続することができます。これが1つの可能なソリューションであり、可能なトポロジーだと考えています。
マーカス
FPGAをインライン・アクセラレータとして使用するケースです。これは、計算機ストレージという大きな絵の一部です。アクセラレーション 、CPUオフロードのためにとても人気があります。計算機ストレージのインライン・アクセラレータのユースケースをいくつか紹介してください。
ヒレン
はい、もちろんです。現在、多くのお客様がデータ・アット・レストの暗号化を行っています。FPGAはSSDや複数のSSDの前に置かれ、お客様はサンドボックス領域と呼ぶか、お客様のアクセラレーション 領域をデータ・アット・レストの暗号化として使用します。また、検索エンジン、検索オフロード、圧縮、eBPFも成長分野です。
このように、お客さまができることはたくさんあります。例えば、圧縮や解凍を例にとると、当社のブリッジでできることの1つに、サーバーやホストが圧縮したデータをそのままブリッジを通してSSDに送ることがあります。
しかし、データを取得する際に、FPGAに圧縮解除のハードウェア・エンジンを組み込むことができます。この解凍エンジンは、データを解凍してからサーバー・ホストに送り返すことができますので、このような使用例もあります。
その他のユースケースとしては、eBPFや、Intellipropがそのリファレンスデザインに取り組んでいることも知っています。
マーカス
先ほども触れられましたが、もっと詳しくお聞きしたいのは、ホストが検索コマンドを発行し、検索そのものをFPGAとSSDにオフロードする、というユースケースです。検索をオフロードするのは、圧縮をオフロードするよりも少し複雑なので、どのような仕組みになっているのでしょうか?
ヒレン
ええ、いい質問ですね。11月にセントルイスで開催されたSuperCompute '21で、インラインブリッジを使った検索エンジンのオフロードを展示しました。CPUがSSDに大量のデータをプリロードしました。サーバーがベンダー固有のコマンドをブリッジの中央に送信し、RTLコードがベンダー固有のコマンドを見て、LBAの範囲またはアドレス空間を取得し、特定のパターン検索を実行します(サーバーからパターンも受信します)。パターンと検索するLBAの範囲を受け取ると、私たちは実際にドライブセクション全体を読み、特定の32ビットパターンを探し、そのすべてのインスタンス(どのLBAで発生したか)を見つけ、それをパッケージ化してサーバーホストに返送しました。
通常、アクセラレータがなければ、サーバーはすべてのデータをシステムメモリに読み込み、検索し、データを捨てていたでしょう。しかし、FPGAを使えば、そのようなデータの移動がなくとも、私たちにコマンドを発行するだけで、"これが見つかった場所です "という応答が返ってきます。FPGAは、それをはるかに高速に実行することができました。これを示すグラフもあります。
では、そのデモの一部をご覧ください。
Stratix 上の線は、直接検索している間のCPU負荷が約90%であることを示しています。しかし、その間にあるFPGAオフロード版は、もちろん何倍も高速でCPUをオフロードしています。
この特定のフレームワークIPをブリッジで使用する必要があるとき、誰かがどのように認識できるのでしょうか?
ええ、いい質問ですね。繰り返しになりますが、これはパススルー型のブリッジです。NVMeの複雑さをすべて排除し、AXIストリーム・インターフェイスを作成し、お客様がロジックを組み込めるようにしました。そのため、お客様はアクセラレーション 。その機能は得意ですが、NVMeの専門家ではないため、このフレームワークの真価が問われるところです。データ、コマンド、その他すべての情報を、AXIストリームを介した制御およびデータ情報として中央に提示し、そのロジックで何をしたいかをお客様に決めていただきます。
そして反対側には、同じく制御およびデータプレーンがあり、再びAXIストリームがSSDにデータを移動し続けます。
この両方向で機能するので、使いやすさはまさに当社の強みですね。
お客さまの専門知識はアクセラレーション 。それをサンドボックスに入れれば、すぐに使えるようになります。そして、BittWareがBittWare のボードでサポートすることで、さらに時間を短縮することができるのです。なぜなら、サンドボックス・ブリッジをNVMe Bridgeプラットフォームに接続できるシリコンを手に入れ、さらにそのプラットフォーム上でアクセラレーション 。
マーカス
では、最後に質問ですが、NVMe Bridge IPを自分で作ろうと考えている方と、IntelliPropを使おうと考えている方とで、IntelliPropがこれを作るのにどれくらい時間がかかったか、また、これを使ったアプリケーションを作るのはどれくらい簡単か、教えてください。
ヒレン
そうですね、いい感じです。このフレームワークは、NVMeと対話しなければならないという事実を、ある種、外挿したり隠したりしたものだと言えるかもしれません。NVMeのことを何も知らなくてもいいのです。ただ、どのようなアドレスと制御情報を得ることができるかを知っていればいいのです。
このブリッジの開発には、インテリプロップ社として1年半ほどを費やし、私たちが望む性能を実現することができました。最終的には、お客さまの時間を節約することができました。
例えば、「SuperCompute '21」のデモを例にとると、1カ月ほどで完成させることができました。ブリッジがなければ、もっと時間がかかっていたでしょう。ブリッジがあれば、制御情報、データ情報がわかるので、アクセラレーション の検索機能とデータを送り返す機能を実現するだけで、1ヵ月かかりました。
つまり、フレームワークであり、すべて事前に構築され、流されているのです。あなたはただ、アクセラレーション に集中すればいいのです。
マーカス
なるほど、素晴らしい。ヒレンさん、今日はいろいろとお話しいただき、ありがとうございました。
ヒレン
ありがとうございます。
マーカス
これがNVMeブリッジ・プラットフォームで、IntelliProp社のフレームワークで、BittWare のFPGAカードで利用可能です。具体的には、IA-840FとダイレクトアタッチSSDの組み合わせを紹介します。詳しくは、BittWare のウェブサイトをご覧ください。また、ご覧いただきありがとうございました。
特徴
- NVM Express 1.4cの業界仕様に完全に準拠しています。
- PCIe Hard Blockによる初期化の自動化
- 複数のSSDに対応したPCIeスイッチ
- コマンドの送信と完了を自動化
- スケーラブルなI/Oキューの深さ
- フロントエンドとバックエンドのインターフェースが分離されているため、柔軟なユーザーロジックやアプリケーションを実現可能
- 柔軟なデータバッファの種類とサイズ
- AXI Stream駆動のコマンドパスとデータパス
- データストリームは、コマンドパラメータをインラインで含む
- 512バイトから4kBまでのブロックサイズに対応
- アプリケーションレイヤーインタフェースにより、プロセッサがAdminコマンドを制御または変更することができる。
- VerilogおよびVHDLラッパー
NVMeブリッジプラットフォームI/Oスループット
NVMeブリッジプラットフォームIPコアの実情
提供されるコア付き
- ドキュメンテーション:包括的なユーザードキュメント
- デザインファイル形式: 暗号化Verilog
- 制約ファイル:FPGA毎に提供
- 検証する:ModelSim検証モデル
- インスタンス化テンプレートです:Verilog (VHDLラッパーあり)
- リファレンスデザイン、アプリケーションノート 合成と配置・配線スクリプト
- 追加項目です:リファレンスデザイン
使用したシミュレーションツール
QuestaSim(最新の対応バージョンはIntelliPropにお問い合わせください。)
サポート:
フルライセンスを取得したコアに対して、納品日から6ヶ月間、電話およびメールによるサポートを提供します。
注)
その他のシミュレーターもございます。詳しくはIntelliProp社にお問い合わせください。
ブロック図、データシート、製品詳細


アプリケーション
NBP IPは、PCIe Gen4 to HostのComputational Storage Devices(CSD)やComputational Storage Array(CSA)で使用でき、スイッチや個別のPCIe接続を介して複数のPCIe Gen4 SSDを搭載することができます。
機能説明
IntelliProp NBP(IPC-NV171B-BR)は、IntelliProp NVMe Target Core経由でコマンドを受信して解析し、NVMe SSD Endpointに配信するためにIntelliProp NVMe Host Accelerator Coreに転送することでプロトコルブリッジを実装しています。これら2つのコア間のカスタマイズ可能なブリッジングロジックは、未処理のコマンドの転送や追跡、データアクセスの適切なルーティングなどのコマンド管理を容易にします。また、「サンドボックス」領域の使用により、ホストとターゲット間で転送されるバッファリングデータに対する可視性と柔軟性を提供します。
ブリッジングロジックのレジスタは、データ移動を制御し、個々のコマンドを手動で発行し、ブリッジング機能のステータスと動作を制御するメカニズムをファームウェアに提供する。プロセッサやその他の管理エージェントは、NVMeターゲットコアから管理コマンドを受信して適切に完了することが期待されますが、I/Oコマンドはブリッジングロジックによって自律的に実行されます。その結果、NBPはホストとエンドポイントSSDの間に透明性を提供すると同時に、設計者にコマンドとデータ操作の柔軟性を提供します。
空の見出し
空っぽの頭
ブロックの説明
NVMeターゲットコア
NVMeターゲット・コアは、標準リリースのIntelliPropコア(IPC-NV163A-DT)で、PCIeコアと連携して準拠したNVMeデバイス・インターフェースを実装するためのハードウェアを定義しています。NVMeターゲット・コアは、PCIeインターフェースを介してシステム・ホストからコマンド送信エントリーを取得し、多数のコマンドFIFOの1つにエントリーを配置する。データアキシストリーム(全二重)、コマンドコンテキストストリーム、完了コンテキストストリームの2つがある。コマンドの完了を受信すると、NVMeターゲットコアは自動的に内部フィールドに入力し、完了をホストシステムにポストします。
NVMeコマンドアクセラレータ
自動化された内部ステートマシンは、NVMeターゲットコアと対話し、Submission Queueエントリをフェッチし、Completion Queueエントリをポストします。データとコマンドは、4つのAXI Streamインタフェースを介してユーザーロジックに提示されます。NVMeターゲットコアからIOコマンドを受け取ると、NVMeコマンドアクセラレータはAXIストリームを介してコマンドを転送し、PCIeエンドポイントコアと連携してユーザーシステムとNVMeホストの間でデータを移動させます。統合レジスタにより、システム構成とコアのステータスをユーザーが制御することができます。
NVMeコマンドトランスレーター
4つのAXI Streamインターフェースを介して、NVMeコマンドアクセラレータとNVMeコマンド、データ、コンプリーションをネゴシエートする。2つのデータAXIストリーム(全二重)、コマンドコンテキストストリーム、コンプリーションコンテキストストリームがある。コマンドを受信すると、このブロックはNVMe SSDからのデータ転送を収容するためのバッファ領域を確保し、次にSSDに発行するためにNVMe Host Acceleratorにコマンドを転送します。SSDからデータとNVMe完了の両方が戻ると、このブロックはNVMeコマンドアクセラレータに完了を返し、バッファ領域を確保解除します。統合レジスタにより、システム構成とコアのステータスをユーザーが制御できます。
サンドボックス
NBPのユーザーロジックスペースは、NVMeコマンドアクセラレータとコマンドトランスレータの間に、ユーザーがカスタムロジックを柔軟に挿入できるようにします。このロジックは、コマンド、コンプリート、データを転送するための標準化されたAXI Streamインターフェイスに準拠する必要があります。コマンドとコンプリーションは、直接渡されるか、実行時に修正(および内部追跡)されるかのいずれかです。データにはコマンド・パラメータがインラインで含まれるため、対応するコマンド・コンテキストから切り離すことができる。データの順序やレイテンシーに制約がないため、ユーザーロジックはアプリケーションに応じてさまざまな形式をとることができる。
NVMeホストアクセラレータコア
NVMe Host Accelerator Coreは、標準リリースのIntelliPropコア(IPC-NV164A-HI)であり、コマンドキューにコマンドを構築し、PCIe Root Complex Coreインターフェースを介してNVMe SSDに使用できるコマンドを通知するハードウェアを実装しています。NVMe Host Accelerator Coreは、コマンドをセットアップし、完了を取得するためのハードワイヤード・インターフェースを備えています。また、AXIスレーブおよびNVMe Host Accelerator Coreのレジスタは、マイクロプロセッサがコマンドの送信を設定し、完了を取得するために利用可能です。
空の見出し
空の見出し
機能詳細について
全体
- 完全なオフザシェルフ・ソリューション、すぐに運用可能
- 複数のNVMe SSD(またはHDD)を直接または付属のPCIeスイッチ経由でサポートします。
- PCIe Gen4からHostへ、スイッチまたは個別のPCIe接続で複数のPCIe Gen4 SSDを接続可能
- 制御・データ用AXI Streamインターフェイスを備えたサンドボックス
- システムアタッチドプロセッサーにより、計算機能の柔軟性を向上。
サンドボックス専用
- 4つのAXI Streamインターフェースがコマンド、コンプリート、データ(サイドバンドメタデータを含む全二重)を提供します。
- 柔軟性を高めるプロセッサー接続
- 実装オプションには、RTLまたはFWのアクセラレーション
FPGA/Hardware Specific
- PCIe Gen4ハードブロックは接続済み
- 最大6200MB/sのスループット(Gen4x4インターフェース)
- IntelQuartus 21.3 Pro tools
Synthesis scripts and timing constraintsと統合。
空の見出し
空の見出し8
対応するFPGAデバイス
| デバイス | スピード | ALUTS | エフエフエス | M20k |
|---|---|---|---|---|
| Altera Agilex Fシリーズ | -2 | 31674 | 22136 | 190 |
| Altera Stratix 10 DX | -1 | 31589 | 20038 | 190 |
成果物
コアには、導入を成功させるために必要なものがすべて含まれています:
- IPコア定義のための暗号化された合成可能なRTLコード
- 暗号化されたModelSim/QuestaSim シミュレーションモデル
- 充実したユーザーマニュアル
- リファレンスデザイン
- を含むシンプルな参考企画例:
- NVMe Host Accelerator IPコアインスタンス
- NVMeターゲットIPコアインスタンス
- NVMeコマンドアクセラレータ
- NVMeコマンドトランスレーター
- サンドボックスブロックの例
- プロセッサー
- 思い出の品
- 合成とPlace & Routeスクリプト
- リファレンスコア制御ファームウェア
- を含むシンプルな参考企画例:
ご利用条件
改造についてIntelliPropのIPコアは、通常、コアの変更は許可されていません。要求された変更は、そのような変更を統合する妥当性を判断するために、IntelliPropに提示されなければなりません。
サポートを提供します:フルライセンスを取得したコアは、納品日から6ヶ月間、電話およびメールによるサポートを提供します。
価格や詳細についてご興味のある方は、こちらをご覧ください。
当社のテクニカルセールスチームは、在庫状況や構成情報を提供したり、技術的な質問に答えたりする準備ができています。
"*"は必須項目