BittWareウェビナー
次世代インテル®Agilex™FPGAによるハイパフォーマンス・コンピューティング
バルセロナ・スーパーコンピューティング・センターのアプリケーション例をご紹介します。
オンデマンド配信中(収録されたQ&Aをご覧いただけます。)
FPGAは、電力効率や特定のワークロードへの適応性などの利点により、より多くのハイパフォーマンス・コンピューティング・アプリケーションに採用されつつあります。このウェビナーでは、次世代I-SeriesおよびM-Seriesデバイスを含む最新のIntel®Agilex™ FPGAに焦点を当てます。
このウェビナーの特別ゲストはCésar González氏で、バルセロナ・スーパーコンピューティング・センターでのFPGAの使用について、アクセラレーション プロジェクトと最近発表された論文で説明します。低分子の構造を決定する彼の研究は、OpenCL高レベルプログラミングを利用しています。Césarは、IntelのMaurizio Paoliniとともに、このコードをIntelAgilex FPGAを搭載したBittWare IA-840fカードoneAPIに移植し、233倍のスピードアップを達成した結果を発表します。

また、PCIe Gen5、CXL、HBM2e-plusを搭載したものを含む次世代Agilex FPGAについて、これらのデバイスをサポートするBittWare カードも紹介します。
HPCに携わる方、最新のFPGAがどのように新しいレベルのアクセラレーション パフォーマンスを提供しているかに興味をお持ちの方は、ぜひこのウェビナーにご参加ください!
パネリストとの質疑応答も収録したオンデマンドですぐに視聴できます!

スピーカー

Christian Stenzel |インテルEMEAテクニカルセールススペシャリスト

クレイグ・ペトリ| マーケティング担当副社長、 BittWare

Maurizio Paolini| インテルEMEA クラウド&エンタープライズアクセラレーション 部門 フィールドアプリケーションエンジニア

César González| バルセロナ・スーパーコンピューティングセンター、カタルーニャ先端化学研究所(CSIC)。
ビデオトランスクリプト
マーカス)
次世代インテルAgilex FPGA によるハイパフォーマンス・コンピューティング」ウェビナーへようこそ。今回はバルセロナ・スーパーコンピューティング・センターのアプリケーション例を取り上げます。私はBittWare のホスト、マーカス・ウェドルです。
まずは、プレゼンターとその内容を紹介しよう。
一人目はインテルのクリスチャン・ステンツェル。彼はザイリンクスでFAEからアカウント管理、ビジネス開発まで幅広い職務を16年間経験し、2015年にAltera 。Intelの買収後、クラウドとエンタープライズのテクニカル・セールス・スペシャリストに異動し、EMEAのクラウドとエンタープライズ市場でIntel FPGAアクセラレーション 戦略を推進しています。クリスチャンは、なぜHPCにFPGAなのか?また、IntelAgilex ファミリーのデバイスについても紹介する。
BittWare彼は、FPGA の分野で数十年の経験を持ち、エンジニアとしてスタートした後、製品管理と戦略を担当し、現在は販売・マーケティング担当副社長を務めています。クレイグがAgilex FPGA を搭載したBittWare製品、oneAPI のサポート、BittWareの新しいパートナー・プログラムについて説明し、最後に CXL について紹介する。
HPCアプリケーションの部では、IntelのFAEであるMaurizio Paulini氏と、特別ゲストスピーカーであるCesar Gonzalez氏の2名が講演を行います。Cesarは、バルセロナ・スーパーコンピューティング・センターでのFPGAを使った彼の仕事のアプリケーション面について説明し、MaurizioはoneAPIについて、CesarのアプリケーションをAgilex.付きのBittWare カード上のoneAPIに最近移植したことを含めて詳しく説明する。
ライブセッションをご覧の方は、ぜひ質問機能を使ってご質問ください。
では、インテルのクリスチャン・ステンツェルの話を始めよう!
(キリスト教徒)
マーカス、本日はお招きいただきありがとうございます。まず最初に、インテルの免責事項についてお知らせします。
さて、ハイパフォーマンス・コンピューティングについて話そう。HPCは広範な市場であり、大きなものから小さなものまで、より深く理解するために利用されている。宇宙の探求から、よりクリーンなエネルギーの研究、気象や気候のモデリング、量子物理学、バイオインフォマティクス、分子動力学、原子力の研究などなど。
研究者や科学者は、より複雑な問題や増え続けるデータに直面しており、データを処理しシミュレーションを実行するために、より多くのコンピュートを必要としている。言い換えれば、HPCの顧客はパフォーマンス競争にさらされているのです。
典型的なHPCデータセンターでは、CPUは計算を実行するためのデフォルト・オプションとして使用され、GPUは並列問題のためのナンバーワン・アクセラレータとして使用されます。FPGAは、CPUやGPUが不得意とする問題を解決するために、HPCシステムを補完する第3の要素であり、FPGA上で最もよく動作するワークロードが常に存在します。
歴史的にFPGAのプログラミングは難しく、特別なRTLプログラミング・スキルが必要でした。マウリツィオはセッションの後半で、oneAPIがどのようにRTLスキルなしでFPGAプログラミングを可能にするかについて話す。
FPGAのユニークな能力を見てみよう。
前述したように、HPCではパフォーマンスが重要です。データをどのように処理するか、あるいはあるアルゴリズムをどのようにアーキテクチャに合わせる必要があるか、アーキテクチャがほぼ固定されているCPUやGPUとは異なり、FPGAは完全な柔軟性を提供します。内部FPGAハードウェア・アーキテクチャは、対象のアルゴリズムに最適に適合するように構築(「コンフィギュレーション」と呼ぶ)でき、高性能で低レイテンシーを実現する。例えば、イーサネット回線を介して、あるいはメモリから直接入力されたデータは、ホストCPUを呼び出すことなくリアルタイムで処理できる。これがインラインまたは「バンプ・イン・ザ・ワイヤー」アクセラレーション の使用例である。あるいは、完全なアルゴリズムをFPGAにオフロードし、結果をホストCPUに書き戻すこともできる。これがルックサイドアクセラレーション 。
高度なスケーラビリティは、FPGAを変更したり、フィールド・プログラマビリティを使用したりして、ワークロードをその場で変更することで達成できる。FPGAはまた、互いに干渉することなく、複数のワークロードを並行して実行することができます。FPGAは本質的にIOが豊富で、アクセラレーション カードには多くの異なるインターフェイスがあります。FPGAをクラスタリングしてワークロードを複数のFPGAに分散させたり、高速チップ間通信で処理段階を可能にしたりすることで、性能をスケールアップできます。
生産性の向上は、既存のサーバーにFPGAアクセラレーション カードを簡単にインストールし、アプリケーションを高速化するためにシステムを構成する簡単な方法を提供するインテル・オープンアクセラレーション スタックのおかげです。
HPCデータセンターでは、消費電力が非常に重要です。FPGAは、CPUやGPUに比べて少ないクロックサイクルと低いクロック周波数でハードウェアが機能を実行できるため、消費電力が低くなります。消費電力の低減はエネルギーの節約を意味し、ひいてはOpExとTCOの支出を削減できることを意味します。
次は価格だ。標準クラスタ用のFPGAアクセラレーション カードには多くのオプションがある。クラスタのパフォーマンスを向上させるためにFPGAアクセラレーション カードをインストールすることは、パフォーマンス目標を達成するためにクラスタをアップグレードまたは更新するよりも費用対効果が高くなります。
スライド4へ移動 -Agilex: データ中心世界のためのFPGA
それでは、10nmプロセス技術で製造されたFPGAファミリAgilex 。Agilex はインテルのファブで製造されています。第二に、インテルが依存度を減らすためにファブの建設に投資しているという発表を、おそらく皆さんも目にしたことがあるでしょう。
Agilex に戻ると、Agilex にはさまざまな機能を持つサブファミリーがあり、今日はこれ以上詳しく説明する時間がありません。詳しくは弊社までお問い合わせいただくか、intel.com/agilex をご覧ください。
Agilex Agilex は、最大40 TFLOPSのDSP性能も提供します。 は、PCIe Gen5、Compute Express Link (CXL)とともに、次世代HBMであるDDR5をサポートしており、HPC顧客にとって特に興味深いものです。Agilex
最後に、私が触れた重要なメッセージを紹介します:HPCの顧客は性能競争にさらされている。FPGAは、パフォーマンスを向上させ、全体的なTCOを削減できる独自の機能を提供することで、システムを補完することができます。
現在では、Agilex FPGAだけではデータセンターで使用することはできない。もちろん、FPGAをホストするエンタープライズ・クラスのカードが必要で、必要なインターフェイスや、たとえばメモリなどボード上の必要な部品がすべて揃っていなければならない。BittWare 、Agilex をベースとしたアクセラレーション カードが市場に出回っており、データセンターのパフォーマンスを向上させることができます。ではクレイグ、どうぞ。
(クレイグ)
ウェビナーをご覧の皆さん、ようこそ。
ご存じない方のために説明しておくと、BittWare はモレックスの一部であり、ハイパフォーマンス・コンピューティングを含むさまざまな市場で主要顧客にサービスを提供する世界最大級の設計・製造企業である。
BittWare はモレックスのデータセンター・グループの一員である。
BittWare アクセラレーション 本日のウェビナーでは、インテルAgilex FPGA に焦点を当てます。
これらの高性能プログラマブル・アクセラレータにより、お客様はインテルFPGAベースのソリューションを迅速かつ低リスクで開発・導入することができます。
当社の製品はラピッドプロトタイピングやベンチマークに使用されるが、最終的にはコスト効率の良い大量導入を目的としている。
ハイパフォーマンス・コンピューティングについて考えるとき、私たちはその言葉を3つの主要な応用分野に分けて考える:コンピュート、ネットワーク、ストレージです。
これらの中には、FPGAに適したワークロードが数多くある。例えば、自然言語認識、推薦エンジン、ネットワーク監視、推論、セキュア通信、分析、圧縮、検索、その他多数。
BittWare では、このようなワークロードをインテルFPGAに実装する際のコスト、労力、リスクの低減に努めています。
最初の方法は、FPGAデバイス(この場合はインテルAgilex FPGA)を使用してプラットフォーム製品を作成することです。
これらは主にPCI Expressカードで、HHHL、FHHL、デュアルスロットGPUなどのフォームファクターがありますが、U.2などのストレージフォームファクターもサポートしています。
各カードやモジュールは、既存および新規のインフラとの互換性を確保するため、公式仕様に準拠している。
カードは個別に購入することもできますし、FPGA用に最適化されたサーバー(私たちはこれをTeraBoxと呼んでいます)に再統合して納品することもできます。多くの場合、スライドに挙げたような大手プロバイダーのサーバーを活用します。
現在、インテルAgilex の3製品を出荷しています。
GPUサイズのIA-840fカードは、現在のフラッグシップです。AGF-027、4バンクのDDR4メモリ、ネットワーク・ポート、拡張ポートを備えています。Stratix 10 MXカードでは数年前からoneAPIをサポートしていますが、oneAPIツールフローをサポートするAgilex ベースのカードは840fが初めてです。
インテルのoneAPIは、統一されたソフトウェア・プログラミング・モデルを導入するための大胆で歓迎すべき取り組みです。oneAPIを使用することで、当社の顧客は単一のコードベースから、アーキテクチャを問わずネイティブな高級言語パフォーマンスでプログラミングできるようになります。
oneAPIには直接プログラミング言語が含まれています:Data Parallel C++と、APIベースのプログラミングのためのライブラリ群があり、クロスアーキテクチャ開発を容易にする。
Data Parallel C++は、使い慣れたC++をベースに、Khronos GroupのSYCLを組み込んでいます。これにより、複数のアーキテクチャにまたがるコードの再利用が劇的に簡素化され、アクセラレータのカスタムチューニングが可能になる。
基本的に、FPGA は通常 x86 または GPU テクノロジーを使用するソフトウェア顧客に開放される。Agilex 、oneAPIを使った開発とベンチマークを希望する顧客は、BittWare '840fカードを検討すべきである。
BittWare は、インテルStratix 10 カードの oneAPI サポートのパイオニアです。これらの実装では、ボード・サポート・パッケージとしてOpenCLレイヤーを使用しました。設計例とホワイトペーパーは、ウェブサイトのリソースセクションにあります。
インテル®Agilex ベースの製品では、oneAPI の実装にインテル® オープン FPGA スタック(OFS)を使用しています。
FPGAのプログラミングを完全に省きたいお客様には、BittWare Partner Programを通じて、Atomic Rules、Edgecortix、Eideticomなどのドメイン・エキスパートによるアプリケーション・コードであらかじめプログラムされたFPGAアクセラレータ・カードをご購入いただけます。
2023年以降の新技術を見据えたとき、ハイパフォーマンス・コンピューティングの将来にとってCXLほど重要なものはないだろう。
CXLはCompute Express Linkの略で、新しいアクセラレータ・リンク・プロトコルです。これは、ホストとアクセラレータ間のコヒーレント通信を可能にすることで、既存のPCIeプロトコルをベースとし、さらに機能を追加したものである。この場合、インテルAgilex FPGAである。これにより、CXLリンクは、ヘテロジニアス・コンピューティング用のルックアサイド・アクセラレータやインライン・アクセラレータと併用することで、効率的で低レイテンシ、高帯域幅のパフォーマンスを実現します。
BittWare は、CXL をサポートする新しい FPGA アクセラレータカード 3 種を発表した。440iと640iはシングル幅のHHHLとFHHLカードで、IシリーズのAgilex FPGAをサポートしています。
400ギガビット・イーサネットに対応するF-TileとPCI Express Gen 5 x16に対応するR-Tileを活用しています。
GPUサイズの「860m」カードは、画期的なMシリーズAgilex FPGAを搭載しており、パッケージ内では最大32GBのHBM2メモリ、外部ではDDR5メモリをサポートしています。これは、ハイパフォーマンス・コンピューティング、特にメモリに制約のあるアプリケーションにとって驚異的なデバイスです。
BittWare は、Agilex I-Series および M-Series FPGA ファミリの両方が、FPGA リソースの使用を最小限に抑えながら、Gen 5 x16 コンフィギュレーション・サポートの全帯域幅を可能にするハード IP を備えているため、CXL をサポートすることができます。
最初のCXL対応FPGAカードは2023年第1四半期に出荷する予定です。
では、なぜCXLがそれほど重要なのでしょうか?私たちの顧客は、より高い性能、より優れたエネルギー効率、そしてアプリケーション内でさまざまなメモリにアクセスできる計算能力を必要としていることを明確にしています。
CXLは、FPGAを搭載したヘテロジニアス・コンピューティング・アーキテクチャの新たなレベルの性能を可能にするというのが、コンセンサスである。
IntelAgilex FPGAは、競合ソリューションと比較して、ポートあたり4倍のCXL帯域幅と2倍のPCIe帯域幅を提供します。
クラウド・コンピューティングがユビキタス化するにつれ、顧客はより高速で効率的なデータ処理を実現するためにアーキテクチャを進化させる必要がある。
これは、先に述べた3つの主要なアプリケーション分野での技術革新を意味する。具体的には、計算負荷の高いワークロードのためのアクセラレーター技術、オンザフライでデータを処理できるネットワーク領域のSmartNIC、そしてストレージプレーン内で膨大な量のデータを静止状態で処理できるコンピュテーショナル・ストレージの緊密な結合である。
コンピュート、ネットワーク、ストレージの各技術はすでにPCI Express上で接続されていますが、アプリケーションのパフォーマンスを一段と向上させるには、CXLの利点を活用する必要があります。
CXLプロトコルでは、CXLが接続されたデバイスの3つの使用形態が記述されています。
タイプ1デバイスは、アクセラレータがプロセッサのメモリへのコヒーレントアクセスを必要とし、ホスト自身のメモリへのアクセスがないSmartNICのようなストリーミングや低レイテンシのアプリケーションに使用できる。
CXL.IO、CXL.Cache、CXL.Memの3つのCXLサブプロトコルをすべて扱うため、タイプ2のデバイスは最も複雑な実装となる:CXL.IO、CXL.Cache、CXL.Memの3つのCXLサブプロトコルをすべて処理するため、実装は最も複雑です。このタイプは、AI推論、データベース分析、スマートストレージなどの複雑なタスクに使用されることを想定しています。
タイプ3 のデバ イ ス を使用す る と 、CXL デバ イ ス に接続 さ れてい る すべての メ モ リ にホ ス ト か ら コ ヒ レ ン ト リ にア ク セ ス で き る よ う にな り ます。こ の場合、FPGA は独自の圧縮アルゴ リ ズ ム や暗号化アルゴ リ ズ ム な ど の特殊なFPGA ロ ジ ッ ク を イ ンプ リ メ ン ト す る こ と がで き る ため、 有用な利点を提供で き ます。
ご存じない方のために説明すると、インテルFPGA CXL IPはハードIPとソフトIPの組み合わせである。
インテルのCXL IPを使用してアプリケーションを設計するには、別途IPライセンスを購入する必要があります。
インテル® CXL ライセンスを有効にすると、Quartus Prime ツールの中にインテル® IP が表示されます。
Agilex R-Tile用のCXLハードIPが有効になると、次に適切なソフトIPがデザインに追加されます。
BittWareの PCIe カードに搭載されているAgilex I-Series FPGA は、CXL 1.1 および 2.0 に対応しています。
さらに先を見据えて、インテルはPCIe Gen 6仕様につながるCXL 3.0をサポートするロードマップを持っている。
だから、CXLは重要になる。このウェビナーを見ている人は、新技術を理解し評価する仕事をしているのであれば、CXLを考慮しなければならない。
これを支援するため、BittWare は、完全なCXL開発およびベンチマーキング・プラットフォームを構築している。
Intel Sapphire Rapids Xeon CPUを搭載した2Uラックマウントサーバーです。BittWareIntelAgilex I-Series FPGAカードも統合済みです。
Linuxオペレーティング・システムは、開発開始に必要なインテルQuartus 、CXLライセンスとともにプリインストールされる。
このバンドルには、CXLを活用したアプリケーション・サンプル・リファレンス・デザインが含まれています。
サーバーとFPGAハードウェアをカバーするテクニカルサポートと包括的な保証が、テクニカルサポートサービスとともに提供されます。
これはほんの一部です。詳細は追って発表いたします。詳細はBittWare までお問い合わせください。
それでは、ウェビナーの次のパートをマウリツィオにバトンタッチします。ありがとうございました。
(マウリツィオ)
ありがとう、クレイグ。
それでは、このケース・スタディで使用したプログラミング・モデルであるoneAPIを見てみよう。
IA-840fのようなプログラマブルアクセラレーション カードは、ヘテロジニアス・コンピューティング・アーキテクチャのための強力なビルディング・ブロックです。ヘテロジニアス・アーキテクチャーは、ハイパフォーマンス・コンピューティングで普及しています。なぜなら、すべてのワークロードが同じではなく、CPU、GPU、FPGA、専用アクセラレーターなど、すべてに適合する単一のコンピューティング・アーキテクチャーは存在しないからです。ヘテロジニアスアーキテクチャを採用することで、プログラマはスループット、レイテンシ、電力効率の観点から、各ワークロードに最適なものを選択できるようになります。
しかし、異種アーキテクチャー向けのコードを開発するのは簡単な作業ではなく、大きな課題を伴う。今日、データ中心の各アーキテクチャは、異なる言語とライブラリを使用してプログラムする必要がある。つまり、別々のコード・ベースを維持しなければならず、プラットフォーム間の移植には多大な労力を要する。さらに、プラットフォーム間でツールのサポートに一貫性がないため、開発者は異なるツール・セットを習得するのに時間を浪費しなければならない。
要するに、ハードウェア・プラットフォームごとにソフトウェアを開発するには個別の投資が必要で、その作業を別のアーキテクチャに再利用することはほとんどできない。
この問題に対するインテルのソリューションはoneAPIで、CPUとアクセラレータ・アーキテクチャにまたがって統一されたソフトウェア開発環境を提供するプロジェクトである。
これはプロプライエタリなプロジェクトではない。その代わりに、エコシステム全体で互換性のある実装を開発することを目的とした、仕様の共同開発のためのオープンな業界イニシアチブに基づいている。
このプログラミングモデルは、次のスライドで説明する一連のツールキットとしてインテルによって実装された。
oneAPIプログラミング言語はデータ並列C++である。これは、データ並列プログラミングの生産性を高めるために設計された高水準言語です。幅広い互換性のためにC++言語をベースにしており、GPUソフトウェア開発者になじみのあるプログラミングモデルで、独自言語からのコード移行を簡素化します。
言語の出発点は、業界コンソーシアムKhronos Groupの下で開発されているSYCLです。インテルとコミュニティは、拡張機能を通じて言語のギャップに対処しており、私たちはそれを標準化する予定です。
データ並列C++は、異なるハードウェア・ターゲット間でのコードの再利用を可能にする:CPU、GPU、FPGAなどである。しかし、パフォーマンスを最大化するためには、各アーキテクチャーに合わせてチューニングする必要がある。
先に述べたように、インテルのoneAPIのリファレンス実装はツールキットのセットである。
ツールキットには以下が含まれる:
- CPU、GPU、FPGAをターゲットとしたデータ並列C++コンパイラで、実績のあるLLVMコンパイラ・テクノロジーとインテルのコンパイラ・リーダーシップの歴史を活用しています。
- ソースコードからソースコードへの移植ツールで、CUDAで書かれた既存のコードを持つ開発者のDPC++への移行を容易にします。
- APIベースのプログラミングでは、アクセラレーション のメリットを享受できる、複数のワークロードドメインにまたがるさまざまなパフォーマンスライブラリが用意されている。ライブラリ関数はターゲットアーキテクチャごとにカスタムコーディングされているため、開発者がサポートされているアーキテクチャ間でコードを移行する際に、開発者によるチューニングは必要ない。
- そして最後に、VTune ProfilerとAdvisorパフォーマンス・ツールの強化バージョンを含む解析およびデバッグ・ツールです。
現在のところ、FPGAのAPIベースのプログラミング・サポートは限られている。
FPGA上でデータ・パラレルC++コードのビルドと実行を開始するには、ユーザーは開発ソフトウェア・スタックをダウンロードしてインストールする必要がある:
- インテル oneAPI ベースツールキットは、コードエミュレーションとレポート生成によるスタティックパフォーマンス解析をサポートします。
- Intel FPGA Add-on for oneAPI Base Toolkit (IntelQuartus Prime を含む) は、FPGA ビットストリームのコンパイルと FPGA 上でのコード実行をサポートします。
- そして最後に、使用するカードのボード・サポート・パッケージ。これはカードベンダーから提供される。このケーススタディで使用したIA-840fカードの場合、ボード・サポート・パッケージはBittWare 。
oneAPI開発スタックは、従来のRTLベースのFPGA設計手法に精通していないソフトウェア・プログラマに、FPGAプラットフォームへの容易なアクセスを提供します。RTLでの設計は、FPGAアーキテクチャの詳細やタイミング・クロージャなどの高度なトピックを深く理解することを意味します。oneAPIを使用すると、そのような詳細はコンパイラとBSPによって処理され、FPGAのプログラミングに必要な労力は他のプラットフォームと同等になります。
それではセサルに、今日取り上げるケーススタディの紹介をしてもらおう。
(セザール)
こんにちは、バルセロナ・スーパーコンピューティング・センターのセサル・ゴンザレスです。FPGAデバイスを使った私たちの研究を紹介したいと思います。
まず最初に、我々のスーパーコンピューターをお見せしたい:"マーレノストラム"バルセロナを訪れたら、ぜひ見学してください(もちろん、サグラダ・ファミリアのようなモニュメントも見学できます)。
我々がやろうとしていること:他のシステムでは決定できないような小さな分子の構造を決定しようとしている。どうやってやるかというと、分子のスペクトルを使ってやるのだ。分子のスペクトルがわかったら、どうやって構造を見つけるのか?
つまり、3D空間で分子のモデルを作り、その理論モデルのスペクトルを後で作り、実際のスペクトルと比較することができる。
スペクトルが同じであれば、構造 がわかっていることになる。そうでない場合は、モデルを再設定して新しいスペクトルを計算し、実際のスペクトルと一致するかどうかを確認することができます。
それで、最初のときは何をしていたんだっけ?それが本物かどうかをチェックするためにテストを行ったんだ。スライドをご覧ください。
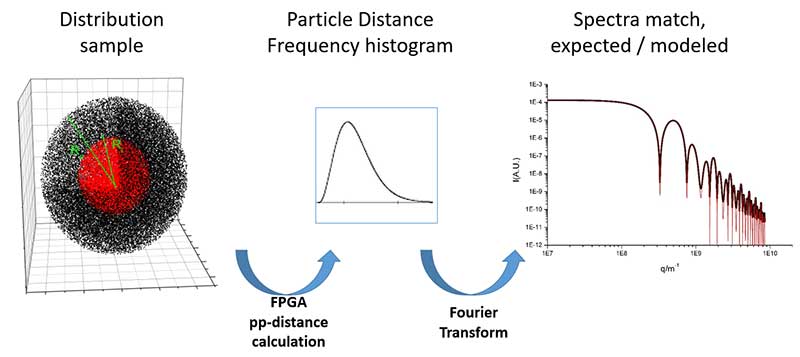
そこで、この二重球のスペクトルの解析解がわかったので、この球の理論スペクトルを計算し、後でスペクトルの解析解と比較する。
つまり、このモデルのスペクトルを計算するには(テストのように使う)、このモデルにおける2つの粒子の距離をすべて計算しなければならない。
粒子の数が非常に多くなると、すべての距離を計算する時間が非常に長くなるからです。200万個の電子のサンプルの分布をここに示します。
この2つの密度球モデルのヒストグラムを計算したんだ。なるほど。
2つの粒子を取り、その距離を計算し、[最初の]粒子の密度と2番目の粒子の電子密度を掛け合わせ、この重みをヒストグラムの距離の場所に置く。
例えば2つの粒子、距離100オングストローム:このペアの電子重量を、ヒストグラムの100オングストローム...x[軸]...に入れます。なるほど。
つまり、200オングストロームの距離があれば、反対側に入れる。200オングストロームの距離がもう1つか2つあれば、ヒストグラムに追加してヒストグラムを取ります。そして、ここではFPGAの距離計算を使っている。
後日、ヒストグラムが揃ったところでフーリエ変換を行うと、計算したもの、つまりこの赤い線が解析解(もう一方の線)と同じかどうかがわかり、これが一致することがわかる。これで、前世紀の理論が正しかったことが証明されたわけだ。
そこで私たちは、構造がわかっている実在の分子を用いて、その分子の理論モデルを作り、後でそのスペクトルが本当にその分子のスペクトルと一致するかどうかを調べるという、もうひとつのステップに入った。
これがベヘン酸銀のセルである。このセルには2分子のベヘン酸銀があります。私たちはベヘン酸銀の実際の構造を知っているのでこれを作り、後で模型を作ります。これがその模型です。セルの25×25×3の繰り返しを置くだけです。そしてFPGAを使って理論的なスペクトルを計算します。
何があるんだ?
緑の線はベヘン酸銀の実際のスペクトル。青い線は、ハートリーフォックによる量子分布を用いて電子を計算したもの。
黒い線は電子がランダムに分布している状態で、赤い線は電子ではなく原子で性能を計算している装置である。
私たちが使っているのは...実際のモデルと一致するかどうかを見るための別のテストです。ハートリーフォックの量子分布を使ってみると、デバイスのように完全に一致することがわかります。
私たちにとって重要なのは、ピークがどこにあるかということだからだ。ピークが所定の位置にあれば、構造を知ることができる。
ご覧のように、電子のランダム分布を使用した場合、グラフの最後にある実際のスペクトルと、電子の量子分布密度を使用したハートリーフォックの分布とでは、解に違いがある。
インテルと私の所属するカタルーニャ先端化学研究所、そしてベヘン酸銀のスペクトルを測定したALBAシンクロトロンに感謝します。
また、バルセロナ・スーパーコンピューティング・センターの抄録集に掲載されている私たちの研究の状況もご覧ください。ありがとうございました。
(マウリツィオ)
ありがとう、セサル。
では、このケーススタディで実装されたアルゴリズムを見てみよう。 これは粒子対距離アルゴリズムまたはpp-distanceアルゴリズムと呼ばれ、次のように説明することができます。
3次元空間に位置するN個の粒子集合が与えられたとき、それぞれの可能な粒子対について、粒子間の距離を計算する。
我々の事例では、各ペアのパワー密度は、計算された距離に対応するビンに累積される。距離は単精度浮動小数点を使用して計算され、ビニングのために整数に変換される一方、累積は倍精度浮動小数点を使用して実行される。
この問題の複雑さはN乗である。なぜなら、N個の点集合の点の組の数は同じ係数でスケーリングするからである。
このアルゴリズムはもともとOpenCLで実装され、2つの異なるプログラマブルアクセラレーション カードでテストされた:IntelArria 10 GXカード(IntelArria 10 1150 FPGAベース)とIntel D5005カード(IntelStratix 10 SX 2800 FPGAベース)。このアルゴリズムはDPC++に移植され、BittWare IA-840fカード(IntelAgilex AGF027 FPGAベース)に実装されている。
この実装に使用したツールチェーンは、oneAPIリリース2022.2とQuartus Prime Pro 21.4である。このプレゼンテーションの後半で、上記のすべての構成で達成した結果を見てみましょう。
では、このアルゴリズムのリファレンス実装を簡単に見てみましょう。これはOpenCLカーネルで、入力としてセット内の点の数、結果に使用するビンの数、点データ-座標と関連するパワーを格納する配列へのポインタを取り、累積結果の配列を返します。カーネルの核となるのは、2つのネストされたループのセット(赤枠)で、その中で点のペアの距離が計算され、パワー密度の累積が行われる。
前のスライドのリファレンス実装は、FPGA上で実行する前に適切に最適化されている。クリスチャンが先に述べたように、FPGAでは実装するアルゴリズムに合わせて内部アーキテクチャが構成される。
つまり、FPGA用にコーディングするということは、計算データパスのアーキテクチャを形成するということであり、これは計算アーキテクチャが固定されているCPUやGPUの場合とは異なります。FPGA用に最適化する場合、プログラマはoneAPIツールチェーンが提供する情報(コードの静的解析と動的プロファイリングレポート)を使用して、実装されたデータパスのパフォーマンスボトルネックを特定し、コーディングテクニックを使用してそれを除去または緩和します。FPGA向けコードの最適化について詳しく知りたい方は、インテルとGitHubのウェブサイトでドキュメント、トレーニング資料、チュートリアル、設計例を入手できます。
私たちの場合、メモリアクセスと計算効率を向上させるために、元のコードにいくつかの最適化を適用した。その結果、元のコードに対して1,000倍以上も性能が向上した。
前のスライドで、このコードがもともとOpenCLで書かれ、DPC++に移植されたことを述べました。さて、コードの移植は非常に簡単な作業で、必要な変更はごく限られていました。基本的には、カーネルのコード・アーキテクチャをDPC++のコーディング・スタイルに合わせる必要がありました。つまり、カーネル自体にラムダ関数を使用し、データ移動のためのアクセサを定義し、プラグマと属性の構文を新しい言語に合わせました。一方、OpenCLでは明示的に管理しなければならない多くの詳細が、DPC++ではランタイムによって自動的に処理されるため、ホストコードは大幅に簡素化されました。その結果、DPC++ホスト・コードのサイズは、OpenCLホスト・コードの半分になりました。
では、結果を見てみよう。
FPGA用のコードはパラメトリックであることに注意。これにより、ユーザーは実装のアーキテクチャ空間を探索し、ターゲット・カーネルのクロックと周波数、およびデータ並列性の間の最適なトレードオフを見つけることができる。
この表の結果は、それぞれのケースで見つかった最良のトレードオフを示している。
最初の行は、ホストCPU(Xeon Ice Lakeプロセッサ)上でシングルスレッド・コードとして実行されるアルゴリズムの逐次実装を指している。この実装では、200万ポイントのデータセットを9,600秒(2時間40分)で処理しています。
IA-840fカード上で動作するDPC++実装は、倍精度浮動小数点ですべての累積を実行する場合、同じデータ量を61秒-シーケンシャル実装の157倍-で処理する。部分的な累積に40ビット整数を使用した場合、処理時間は41秒に短縮され、233倍高速になる。
また、旧世代のハイエンドFPGAと比較した場合、Agilex FPGAは、より高いクロック周波数と高いデータ並列性を可能にし、その結果、性能は2倍になる。
以上でこのプレゼンテーションを終わります。お付き合いいただきありがとうございました。それでは質疑応答の時間です。
(マーカス)
では、マーカスが戻ってきましたので、Q&Aを行いたいと思います。すでに多くの情報が寄せられ、いくつかの質問も寄せられています。パネリストに質問がある場合は、質問機能を使ってタイプしてください。
特にマウリツィオとセザールには、バルセロナ・スーパーコンピューティング・センターでのHPC......彼らのHPCの仕事に関するプレゼンテーションや詳細について、ぜひお礼を言いたかった。
この新しいAgilex FPGAファミリーは、HPCワークロードに適した性能と機能の優れた組み合わせをもたらします。oneAPIプログラミングモデルは、コードの移植性、柔軟性、そしてMaurizioが話したようなことを可能にするので、HPCに携わる人なら誰でも検討すべきものです。
私たちは、Arria 10ベースのカードからStratix 10(どちらもOpenCLを使用)にコードが移植されたことを確認しました。その後、マウリツィオがBittWare's new IA-840fAgilex card上でoneAPI...oneAPIを使用して移植したのですが、非常に迅速でスムーズなワークフローの変更でした。これが利点のひとつです。
そして、最後に聞いたように、パフォーマンスも。Agilex 、このHPCワークロードで非常に印象的なパフォーマンスとアクセラレーション 。
それから、CXLについても聞きました。クレイグが、BittWare から間もなく発売される新しいCXL開発バンドルについて触れました。 その詳細についてお聞きになりたい方は、私たちにご連絡ください。
それでは質問に移ります。
最初にセイザーにお聞きしたいことがあります。使用したFPGAについて話しましたが、特定のアプリケーションにFPGAを使うという決断はどこから来たのですか?
(セザール)
というのも、チームの全員が、ハイパフォーマンス・コンピューティング・コンポーネントのプラグマを直接理解しているからです。私たちにとって、すべての人がカーネル(OpenCLカーネル)を理解できることは非常に重要です。
また、FPGAで行ったすべての経験は、後でGPUに実装することができます。いずれにせよ、GPUを使用することで、いくつかの制限や便利な点、不便な点が見えてきます。例えば、モデルが10倍大きければ、GPUにかかる時間は2倍になります。一方、FPGAにかかる時間は同じです。しかし、FPGAがGPUより優れているわけではない。我々には異なる環境がある。私たちにとっては、FPGAの方が優れています。博士号を取得した当初、私はインテルにある質問をした:「火星に行くとしたら、何を持っていきますか?GPUかFPGAか?(笑)。
(マーカス)
いい質問だね。いい例えだね、感謝するよ。
簡単に振り返っていただけますか?使用したプロセスについて詳しく話してくれましたが、最終的な結果はどのようなものですか?冒頭でおっしゃったとおりですが、この結果をどのようなケースで使うのでしょうか?
(セザール)
分子の構造が分かれば、病気の人のための治療法や薬を作ることができる。ですから、私たちは生物医学とナノテクノロジーの基礎に取り組んでいるのです。ですから、医師やその他の人たちにとって、この分子や他の分子をどうやってブロックできるかを知ることはとても重要なことなのです。これは非常に重要なことなのです。