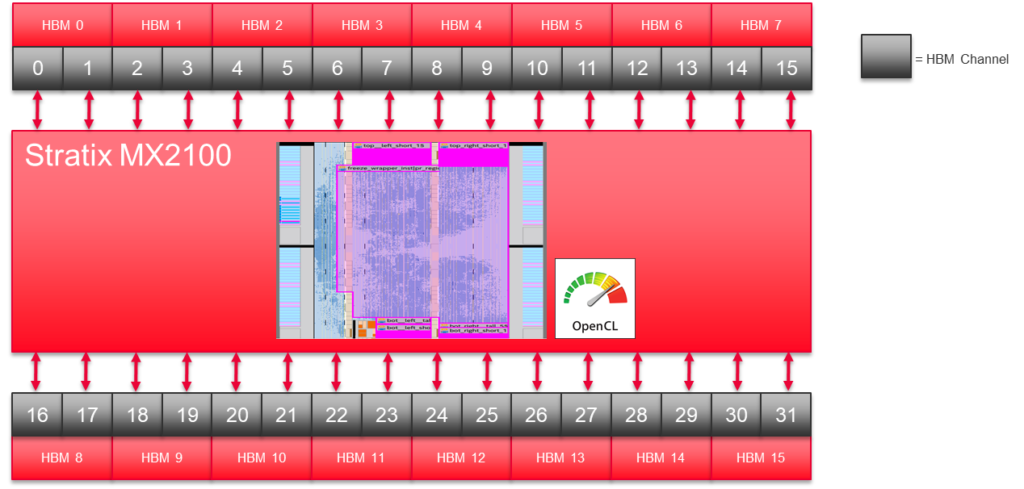
 Stratix 10 MXには32個の擬似HBM2メモリチャンネルがあります。私たちの2D FFTの実装では、その半分のチャンネルを使用しています。
Stratix 10 MXには32個の擬似HBM2メモリチャンネルがあります。私たちの2D FFTの実装では、その半分のチャンネルを使用しています。
- チップ内に2つの2D FFTカーネルを配置することができます。1つのカーネルは、チップの北側にあるすべての擬似チャネル・インターフェースを使用します。 もう1つは、南側のチャネルを使用します。
- 1つの2D FFTで32チャンネルすべてを使おうとすると、デモコードでは扱いたくなかったルーティングの課題が発生します。
FPGAのHBM2チャンネルに1列ずつ配置
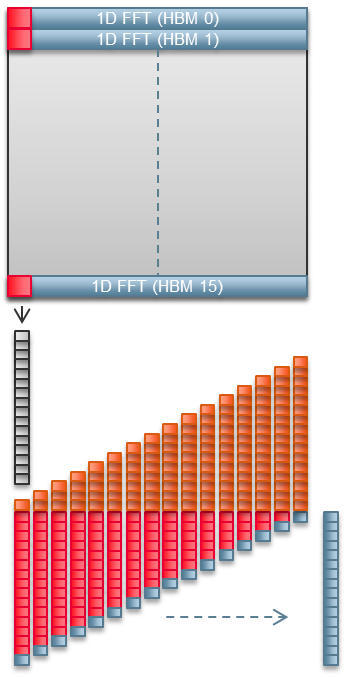
2D FFTは、多数の1D FFTを使用して実装されています。単一の1次元FFTは、それが使用するHBM2チャネルを飽和させます。16個のHBM2チャンネルを使用することで、2D FFTの実装は1024行のマトリックスの16行を並列に処理します。 ハイエンドGPUであれば、おそらく1回のパスで1024行すべてを処理することができます。FPGAの場合は64パスが必要です。ただし、どちらの場合もHBM2/GDDR6の帯域幅が制限要因となるため、パスの数は重要ではありません。400MHz Fmaxは十分です
各HBM2チャンネルを飽和させ、最適な32バイトバーストを行うには、400MHzのOpenCLクロック周波数が必要です。より高速にすることは価値がありません。もっと遅くても最適ではありません。Intelの現在のDPC++の実装は、BittWareの既存のOpenCLボードサポートパッケージを利用しています。したがって、どちらの実装も FPGA からは OpenCL のように見えます。どちらの実装も、400MHzを達成するために同じ調整を必要とします。この微調整は、ソースコードでの表現が異なるだけです。1D FFT出力
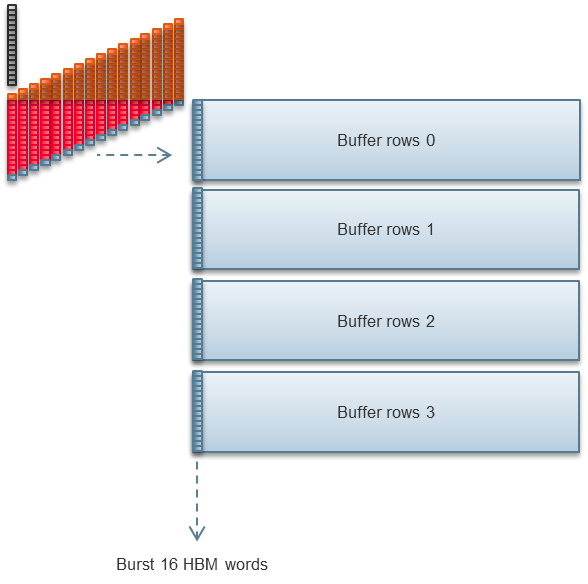
1D FFTは、結果を直接HBM2に出力するわけではありません。代わりにFPGAの内部メモリに書き込まれます。FPGAの追加ロジックは、複数の1D FFTの結果を収集し、それらの結果をコーナーターンしてHBM2に書き戻す。