
ホワイトペーパー
ネットワーキングの例を用いたFPGA RTLとHLS C/C++の比較
概要
FPGAプログラマーの多くは、高水準のツールは高い生産性のための「コスト」として、常に大きなビットストリームを出力すると考えています。しかし、これは常に正しいのでしょうか?この論文では、一般的なネットワーク機能であるRSSを、従来のRTL/Verilogツールと、同じハードウェア上で高位合成(HLS)の両方を使用して作成した実例を紹介します。その結果、HLSの方がFPGAのゲート数とメモリ使用量が少なかったという驚くべき結果が得られました。これには理由があります。詳しくはこちらをご覧ください。
FPGA 開発における HLS のアプローチは、C/C++ 環境で容易に表現できるアプリケーションの部分のみを抽象化することです。HLS ツールフローは、Vivado (Xilinx) または Intel (Quartus) ツールを使用することで、基本的にあらゆるBittWare ボードで利用可能です。
HLSで成功するためには、応募書類の中でどのような部分が適しているのかを認識することが重要です。ガイドラインは以下の通りです:
- ターゲットとなる用途は、一般的には、そもそも高級言語で定義されているIPブロックです。数学のアルゴリズムでもいいし、今回のRSSブロックのように、ネットワークプロトコルの処理でもいい。
- また、ブロックの定義が不十分なため、複数回のインプリメンテーションが必要な場合もあります。ここでの最大の利点は、HLSツールで自動的にネイティブFPGAコードをパイプライン化できることで、パイプラインを素早くハンドコーディングするよりも少ないステージしか生成されない場合があります。また、ハンドコーディングしたパイプラインを変更する場合、1つの並列パスで遅延を変更すると、すべてに波及する可能性があります。HLSツールを使って、ゼロから2回目のパイプラインを自動的に作成することで、このような頭痛の種を解消することができます。
- 最後に、HLSフローは、FPGAのブランドやスピードグレード間でコードを簡単に移植することができます。これは、HLSが適切な数のパイプライン・ステージを自動的に生成するためで、VerilogやVHDLで作業する場合は手動で指定する必要があります。
現在の HLS の限界は、明らかにその範囲が IP ブロックに限定されていることです。アプリケーションチームは、他のコンポーネントの RTL を必要としますが、RTL 部分にBittWareの SmartNIC Shell のようなものを活用すれば、ユーザは独自のアプリケーションを完全に HLS で定義することができるようになるかもしれません。また、HLSは、最も単純なコードや、最適化済みのコンポーネントで構成された大規模な設計には適していないことに注意する必要があります。
私たちのアプリケーションFPGAでRSSをネットワーク化
RSSとは何ですか?RSSとは、"Receiver Side Scaling "の略です。複数のCPUにネットワークパケットを効率よく分散させるためのハッシュアルゴリズムです。RSSは最近のイーサネットカードに搭載されている機能で、一般的にはマイクロソフトが定義した特定のトープリッツハッシュを実装しています。
RSSアプリケーションをホストする環境は、BittWare's SmartNIC Shellです。SmartNIC Shellは、FPGAベースのネットワーキング・アプリケーションを構築する際に、ユーザーに先手を打ってもらうために設計されています。このシェルは、最適化されたFPGAベースの100Gイーサネット・パイプラインを提供し、ホストとの対話のためのDPDKも備えています。ユーザーが行うべきことは、アプリケーションをIPブロックとしてドロップインするだけです。
このケースでは、BittWare 、RSSのFPGA実装をアプリケーションとして作成し、ユーザーでもありました。従来のRTLアプローチでRSSを作成するチームとHLSチームの両方が、SmartNIC ShellをFPGAイーサネットフレームワークとして使用し、RSSアプリケーションそのものに集中することができました。
BittWare'sのRSS実装
FPGAベースのRSS実装は、特にDPDKのソースツリーにあるCコードに基づいており、そのコードのテスト関数もツリーで入手できます。また、このRSSアプリケーションでは、一般的な128エントリーのテーブルではなく、64エントリーのインダイレクトテーブルを使用しています。このHLSの研究で重要なのは、FPGAに取り込む関数がC言語で定義されていることです。これは、HLSの成功のための第一条件であるCまたはC++での定義を満たしています。
タプルを使ってパケットをグループ化する
RSS関数の目的は、CPU間でパケットを分散させ、関連するパケットのストリームを一緒にしておくことです。異なるトープリッツ鍵セットによって、異なる分散パターンが得られます。しかし、どの鍵セットであっても、RSS関数は各パケットの送信元と送信先のIPアドレス、送信元と送信先のポートを入力として使用します。これら4つの要素を組み合わせたものを4タプルと呼びます。
RSSアプリケーションでは、4タプルはすでに解析され、パケットのメタデータに追加されていると仮定していることに注意してください。SmartNIC Shellの別のモジュールは、このパケット分類機能を処理します。私たちはこのモジュールを「パーサー」と呼び、BittWare のホワイトペーパーで紹介する予定です。
私たちのRSS実装は、現在、分類のために96ビットのフィールドを受け入れます-IPv4ソース/宛先とポートの4タプルのために十分です。パケットがIPペイロードを含まない場合、96ビットのタプルフールドはゼロとなります。
多くのRSS実装では、4タプルの代わりに5タプルを使用しています。この場合、プロトコル番号に対応するために 8 ビットが追加されます。RSS の HLS ユーザは、ソースコードを少し変更するだけで、この変更に容易に対応することができます。このように、4 タプルから 5 タプルへ迅速に対応する能力は、HLS が成功するための第 2 の基準である、複数回の実装が必要であることを示す一例です。
FPGA開発ツール関連用語
FPGA内で動作するIPの開発には、もともとASIC開発用に作られた言語が使われるのが通例です。これらの言語を何と呼ぶかについては、まだコンセンサスが得られていない。レジスタトランスファー言語の略である「RTL」を使う場合もあれば、ハードウェア定義言語の略である「HDL」を使う場合もある。また、ハードウェア定義言語の略である「HDL」を使う人もいる。最も一般的なHDLは、VHDLとSystemVerilogの2つです。社内では、BittWare 、両方を使用していますが、大規模なプロジェクトではSystemVerilogを使用し、その完全な検証機能セットを使用しています。
検証はFPGA設計プロセスの重要な部分であり、ASIC設計においても重要な部分です。ASIC業界におけるコストの上昇は、シリコンのファーストパスを確実に成功させるために、高度な検証言語とテクニックの必要性を促しました。このニーズはVerilog言語にHVL(ハイレベル検証言語)の機能を取り込ませ、最終的には現在のSystemVerilog IEEE 1800標準に統合されました。現代のASIC検証は、テストベンチを構築するための標準的な方法を提供するUVM(Universal Verification Methodology)へと移行しています。
FPGA開発における経済性の違いや、ラボですぐにデザインをテストできることから、FPGA開発者におけるUVMの採用は遅れています。しかし、高密度FPGAの複雑化に伴い、多くのグループがASIC設計フローで使用されているものと同じ検証手法を採用するようになりました。BittWare では、FPGA の検証に対して流動的なアプローチをとっています。安価なシミュレータや無償のシミュレータに搭載されているSystemVerilogやVHDLの機能をベースにしたシンプルなテストベンチを使用することが多いです。しかし、必要に応じて、SystemVerilogとUVMの全機能をベースにした最新のテストベンチを構築しています。
HLS(High Level Synthesis)は、HDLよりも高い抽象度で動作する言語に与えられる名前です。実際には、HLSは通常、CまたはC++の特殊バージョンを指します。しかし、他のHLS言語も存在します。たとえば、BittWare が配布しているサードパーティの IP の中には、BlueSpec で記述されているものがあります。これらの HLS ツールはすべて、モジュールレベルでテストベンチを生成するための簡単でプッシュボタン式の方法を備えている傾向があります。システムレベルではまだUVMが必要です。
最後に、現在最も高いレベルにあるのがOpenCLです。これはGPUチップ用に開発された並列プログラミング言語で、FPGAの世界でも再利用されています。現在、OpenCLの用途はほとんどHPC(ハイパフォーマンス・コンピューティング)であり、インテルベースのサーバーが実行できる速度よりも速く実行する計算アルゴリズムを実装するために使用されています。
HLS Coding for Performance
HLSを使用すると、ソフトウェアのようなツールフローが提供されますが、開発者は、パイプラインや反復間隔など、従来のプロセッサ用のCコードを書くときには触れなかったようなハードウェア中心の概念を学ぶ必要があります。
HLSコードは、通常パイプライン化された組み込みデザイン用のIPコンポーネントを開発するために主に使用されます。当社のRSSアプリケーションも例外ではありません。RSSの最小限の性能要件は、各512ビット入力ワードが、飽和状態の100Gb/sネットワーク・インターフェイスに追いつくのに十分な速度で処理されることです。これは、300MHzの周波数でクロックサイクルごとに新しいワードを処理することに相当します。この周波数は、最速のFPGAでも400MHzをはるかに超えない周波数で動作するため、難しい。明らかに、1クロックごとに新しい単語を処理しなければなりません。
これは、パイプラインの特定のロジックが完了するまでに必要なクロックサイクル数を意味する反復インターバル(II)の概念を導入しています。RSSモジュールでは、1クロックごとに結果を得る必要があり、IIは1である。
IIが高くなる原因としては、以下のようなものがあります:
- ループ間の依存関係は、パイプラインの次の出力が、パイプライン内の別の変数の将来の結果を必要とする場合に発生します(例:再帰)。アキュムレータのような単純な再帰演算は、FPGAに1クロックサイクルで計算を完了するロジックが含まれているため許容されます。しかし、より複雑な再帰演算を行う場合は、より高いII値が必要になります。
- RSSデザインでは、パイプラインの各ステージが3.3ns以内に完了することが要求されています。HLSツールは、各ステージがこのタイミング要件を満たすように、必要な箇所にレジスタを挿入します。しかし、組み合わせロジックがパイプライン化できない場合は、必ずしもそうすることができません。深い組み合わせロジックの例としては、複数のネストされたループのインデックス計算があります。
- ターゲットクロックの周波数が高すぎて、FPGAファブリックの配線パスが単純に長すぎてタイミング要件を満たすことができない場合、IIは増加します。この問題の解決策としては、ロジックを半分のクロック周波数で動作する2つのパスに分割することが考えられます。
コードの本体は、必要な入力タプルの語数分ループして新しいハッシュを作成します。この例では、96ビットのハッシュ値に対して、3語の入力タプルを使用しています。
int input_len = 3;
/*
* The hash calculation is calculated per input tuple word.
*/
int32_t ret = 0;
int j, i;
for (j = 0; j < input_len; j++) {
for (i = 0; i < 32; i++) {
if (tuple_in_i[j] & (l << (32 - i ))) {
ret ^= rte_cpu_to_be_32(((const uint32_t *)rss_key) [j]) << i |
(uint32_t) ((uint64_t) (rte_cpu_to_be_32 (((const uint32_t *)rss_key) [j + 1])) >>
(32 - i));
}
}
}
return ret;

このコードは、RSS計算の心臓部を実装しています。DPDKのソースツリーから抽出されたオリジナルから変更されていません。したがって、このRSSブロックの場合、移植作業はブロックのAXIインターフェースの定義と、II.のような定義にプラグマステートメントを追加することですべて完了した。
入力の長さが一定の場合、FPGAは2つのループを完全にアンロールして、完全にパイプライン化されたコードを作成することができます。
IPコンポーネントをスマートNICフレームワークに統合するには、インタフェースとコントロールプレーンを定義し、外部インタフェースへの読み書きを行うロジックも定義する必要があります。スマートNICフレームワークは、コンポーネント間の通信にAXIインターフェイスプロトコルを使用します。

AXIインターフェースの定義とプラグマステートメントの追加により、コード行数が多くなり、ここで図に示すことはできません。全ソースコードファイルは、BittWare から入手できます。
ザイリンクスコンパイラの定数はインテルバイトオーダー(リトルエンディアン)ですが、ネットワークプロトコルはネットワークバイトオーダー(ビッグエンディアン)であるため、エンディアンに問題があります。これはパフォーマンスやリソースの使用には影響しませんが、HLSで処理する前に入力データのエンディアンを変更する必要があります。
ネイティブプログラミングとHLSの比較:その結果
2つのFPGA RSSの実装があるのは、最初のバージョンがVerilogで書かれたからです。これは、私たちが評価している「FPGAネイティブコーディングは常に最小のリソース使用量になる」という仮定の下で起こったことです。しかし、BittWare のエンジニアがその判断に異議を唱え、このアプローチをテストするためにHLSでRSSを再実装しました。彼の判断は正しく、BittWare 、SmartNIC ShellのRSSモジュールとParserモジュールはHLSコードに置き換えられました。
2つのRSSの実装
| 特徴 | ベリログ | HLS C |
|---|---|---|
| CLBs | 44,435 | 2,385 |
| ビーラム | 12 | 1 |
| レジスター | 52,352 | 4,843 |
| コード行数 | 650 | 459 |
2つの実装の最大の違いは、Verilog/RTL版ではFIFOを使用し、HLS C++版では使用していないことです。HLSに移行することで、リソース使用量が実際に減少したのは驚きでした。
時間短縮についてはどうでしょうか?大雑把に言うと、RTLのネイティブ版では1ヶ月、HLSのコードでは1週間で完成というタイムスケジュールが見えてきました。
Intel HLSとXilinx HLSの比較
この例では、Xilinx HLS を使用しています。しかし、高レベル言語を使用する主な利点の1つは、異なるテクノロジーアーキテクチャ間の根本的な違いをある程度まで抽象化できることです。インテルには、C++をコンパイルしてRTLコードをゲートする同等のコンパイラもあります。
同じコードをインテルi++コンパイラでコンパイルするためには、データ型の微妙な変更と#pragmasの変更が必要です。IntelとXilinxの最大の違いは、IntelではAvalonストリーミング・インターフェースを使用し、XilinxではAXIを使用していることです。このため、一方から他方へ変換するための簡単なシムインターフェースが必要になります。
コ・シミュレーション
機能的に検証された後は、コ・シミュレーション環境を呼び出して、正確なRTLシミュレーションをサイクルさせるのは簡単な作業です。Vivado-HLSは、オリジナルのC++コードによって生成されたベクターによって駆動されるRTLテストベンチを自動的に生成します。ユーザが必要とする修正は、設計に含まれる無限ループやブロッキング・インターフェイスを処理することだけです。RSSモジュールは、ファームウェア・パイプラインの一部として無限に実行されるように設計されています。そのため、シミュレーションが完了することはなく、コ・シミュレーションがハングアップしてしまいます。これを避けるため、RSSコードのメインループ「while (1)」を、テストベンチからのすべての入力を消費し、必要なすべての出力を生成するのに十分な長さの固定長に変更しました。
コ・シミュレーションは、RTLがツールによって正しく生成され、モジュールのタイミング特性が元の設計パラメータに適合していることを、さらに確信させるものです。
コ・シミュレーションフローは、インテルHLSツールスタックの一部としても利用可能です。
IPブロックによるHLS構築
HLS ツールフローは、使用されるインターフェイスプロトコルをビルトインで認識する必要があります。BittWare の IP ブロックは、一般的に Advanced extensible Interface (AXI) を使用して通信します。具体的には、パケットデータを渡すためのAXI4-Streamと、コントロールプレーンとしてのAXI4-Liteです。
100GbEでは、BittWare 、512ビット幅で300MHzのクロックを持つAXI4-Streamインターフェイスを使用します。各パケットに関連するメタデータは、パケットデータのTLAST信号がアサートされるパケットの終了時に有効となる独自のバスで続きます。パケットメタデータは、ブロック間やリリース間で進化します。通常、以下のような情報が含まれています:
- パケットが到着した物理イーサネットコネクタの番号
- パケットに関連するMACが識別したあらゆるエラー
- 80ビットIEEE-1588形式のタイムスタンプ、または64ビット短縮形式のタイムスタンプ。
- 次の機会にパケットをストリームから削除する必要があることを示す "deleted "ビット
- パケットの宛先を示す、通常「キュー」と呼んでいる数字です。パイプラインのIPブロックの1つで計算される(多分このブロックも)。
RSSブロックの制御プレーンは以下の通りです:
- イネーブル/ディセーブルビット
- トープリッツハッシュの16ビットキー20個分
- 64エントリーのインダイレクトテーブル
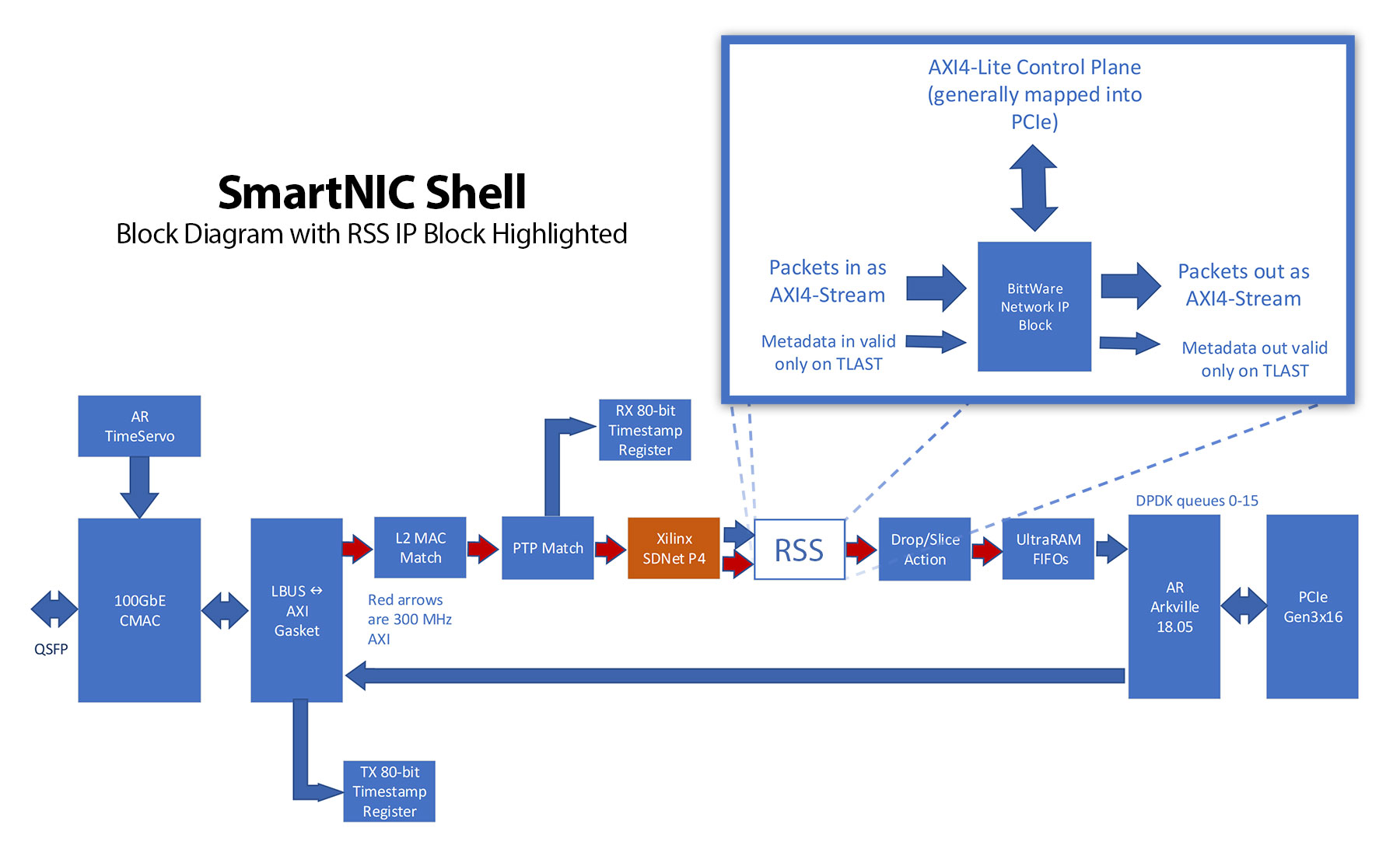
SmartNIC Shellフレームワークの実装例のブロック図です。ここでは、RSSブロックをHLSの実装に置き換えています。
結論
今日のハイレベルなFPGA開発ツールは、市場投入までの時間を短縮し、ハードウェアエンジニアへの依存を軽減するように設計されています。しかし、これらのツールを使用すると、速度やシリコンリソースのいずれにおいても、アプリケーションのパフォーマンスが常に妥協されるという前提は誤りである。
BittWareの SmartNIC Shell 用の IP ブロックを開発するために HLS を使用すると、開発期間が約 1 ヶ月から 1 週間に短縮されることがわかりました。また、実装に使用するゲート数も少なくなりました。
RSSブロックのソースコードは、XUP-P3Rボードの所有者とSmartNIC Shellのユーザー向けに公開されています。HLSコード内でAXIインターフェイスを使用する方法を示す優れた図解です。詳しくは、BittWare の担当者にお問い合わせください。
HLSは、ネイティブの開発ツールに加え、すべてのBittWare FPGAボードで利用可能です。また、OpenCL開発をサポートするさまざまなボードも提供しています。