FPGA デバ イ ス は複雑 さ を増し、 メ モ リ やネ ッ ト ワー ク 接続な ど の多数の外部 イ ン タ ーフ ェ イ ス をサポー ト す る よ う にな っ てい ます。こ の よ う な多数の イ ン タ ーフ ェ イ ス に対応す るIP や通信 ロ ジ ッ ク は、FPGA の リ コ ン フ ィ ギ ュ レーシ ョ ン可能 リ ソ ース の大半を占め る ため、 コ ン ピ ュ ー ト に使用で き る ロ ジ ッ ク が減少 し ます。高速接続を多数相互接続す る ために必要な膨大な数の配線 リ ソ ース も 、FPGA デザ イ ンのボ ト ルネ ッ ク の原因にな り 、 動作周波数が低 く な る ため性能が低下 し ます。 こ れ ら の イ ン タ ーフ ェ イ ス間で相互通信が必要な場合は特にそうです。
Networks On Chips(NoC)は、専用のルーティングとスイッチング・ロジックを提供し、すべてのインターフェイスを互いに見えるようにすることで、この問題に対処しようとしている。これは、FPGAゲートを使用したユーザー定義ロジックを、柔軟な汎用ハードワイヤード・ネットワークに置き換えるものです。
NoCは、ユーザー・ゲートにアクセス可能なエンドポイントを多数提供し、NoCに接続されたあらゆるインターフェースや、別のエンドポイントに接続されたユーザー・コンポーネントへのアドレス可能なアクセスを提供する。
図1は、複数のユーザー・エンドポイントがNoCに接続された数個のメモリにアクセスする基本的なNoCを示している。NoCはクロスバーとは異なり、エンドポイントがどのように接続されているかに関係なく、通常は等しいスループットを提供する。つまり、NoCは特定のアクセス・パターンで輻輳の影響を受けやすい。図2は、輻輳がどのように発生するかの例である。NoCの中には、ネットワーク・ファブリックをFPGAロジックよりもはるかに高い頻度で動作させたり、トラフィックの多い領域に複数のルートを設けたりすることで、このような問題を回避しようとするものもありますo。
図1:メモリエンドポイントを持つNoCの例
図2:複数のエンドポイントが重複するインターフェイスにアクセスしようとする場合、NoCではルーティング・ロジックを共有する必要がある。
NoCを使用する利点には、以下のようなものがある:
NOCを使うには、設計上の課題がいくつかある:
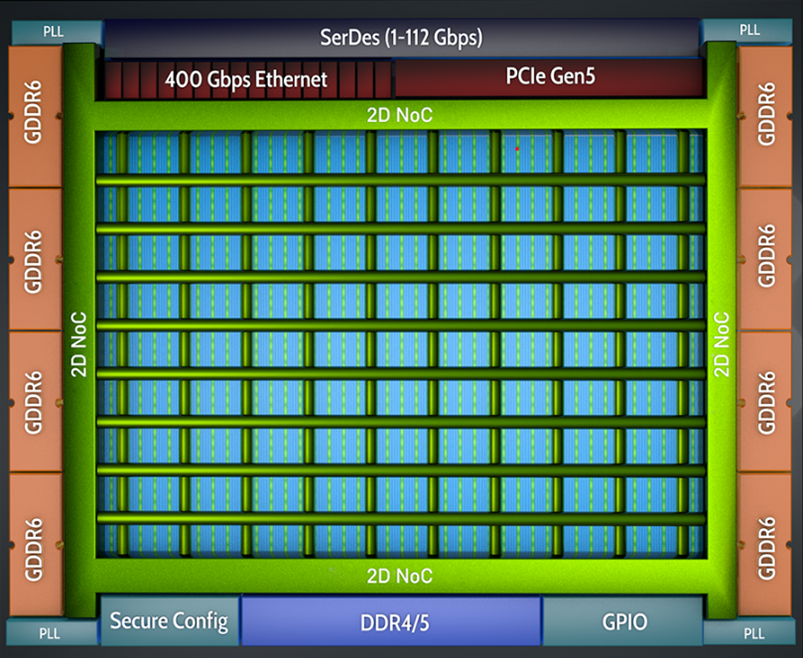
AchronixSpeedster7t デバイスは、メモリ、PCIe、イーサネット間の接続をデバイスに分散した複数のユーザー・エンドポイントに提供する2D NOCを使用しています(図3を参照)。
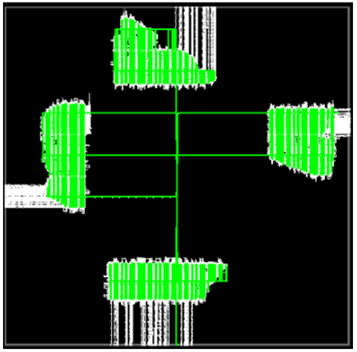
NoCの2D分布により、FPGAファブリックの残りの部分で混雑を引き起こすことなく、デバイスのさまざまな領域が8本の水平配線パスと10本の垂直配線パスを介して相互に通信できる。これにより、AFUロジックがうまく分離され、配線が改善され、最終的にクロック周波数が向上します。図4はこの動作を示しており、4つのAFUがNoCを介して通信していますが、チップ全体にロジックが広がっていません。
図3:Achronix 2D NOCを使用した内部ロジックの相互接続
図4 : Achronix 2D NOCを使用した内部ロジック相互接続。
また、400Gイーサネット・データを4つの100Gストリームに自動的に分割するIPも追加され、これらはすべてNoCインターフェイスで管理される。これにより、400GパケットをFPGAユーザー・ファブリック内でより管理しやすいクロック速度で処理できるようになる。
Speedster7 デバイスは、BittWareの St7-VG6 PCIe カード.
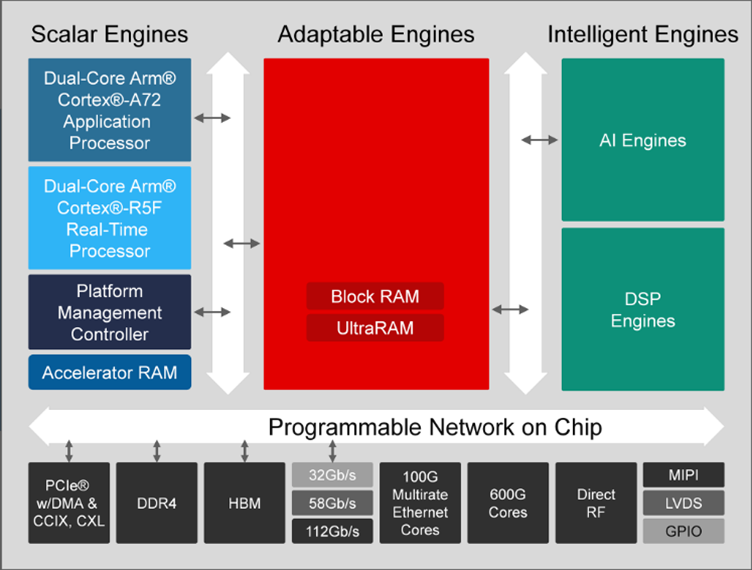
AMD ACAPデバイスは、スカラー・エンジン、リコンフィギュラブル・ロジック、DSP/AIエンジンなど、デバイス上の異種ロジック間の通信にNoCを使用している。プログラマブル・ロジックには、メモリ、AI、PCIeエンドポイントへの通信を可能にする複数のエンドポイントが用意されている(図5参照)。NoCには、FPGA内でデータを移動させるための水平パスと垂直パスがある。NoCパスの数はデバイスによって異なる。
図5:プログラマブルNoCを備えたAMD ACAP
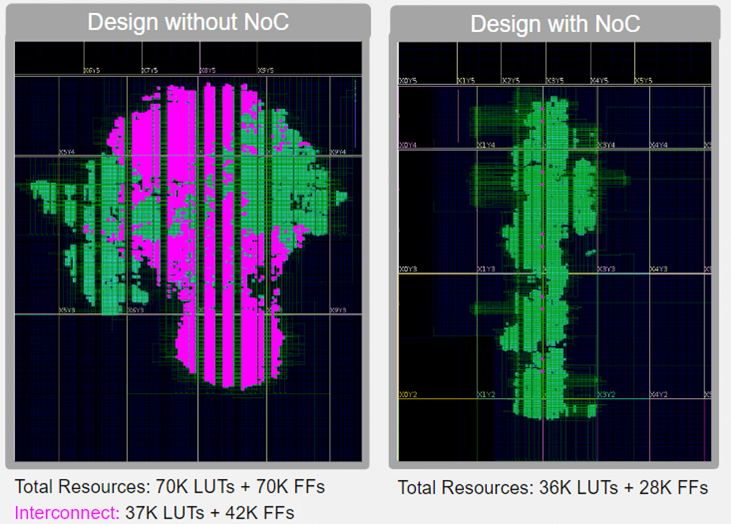
NoCを使用することで、同じ通信をプログラマブル・ロジック内で行うよりもリソースを節約できる。これを図6に示す。このような単純な現実世界の設計では、通常、モジュール間の通信にパケット・ルーティング技術を使用することはないため、この比較は完全には妥当ではありません。し か し 、 こ の よ う なネ ッ ト ワー ク を ゲー ト だけで実装す る には、FPGA リ ソ ース が多 く 必要にな る こ と を示 し てい ます。
オンデバイスの高速ネットワークは、ユーザーに新しい設計アプローチを提供する。以前はAFU間の内部ネットワークベースの通信は低速で、多大なリソースを必要としていたが、NoCはこれを自由かつ高速にする。NoC通信を使用するためにロジックを分離することができれば、設計の小型化、分離の改善、したがって性能の向上というメリットが得られる。また、専用のNoCを使用することで、ルーティング結果もより一貫したものになり、設計性能の見積もりに対する信頼性が高まります。
図6:NoCの使用によるリソースの節約
Versal Adaptive SoCは、BittWareに搭載されています。 AV-860hおよび AV-870pPCIeカードに搭載されています。
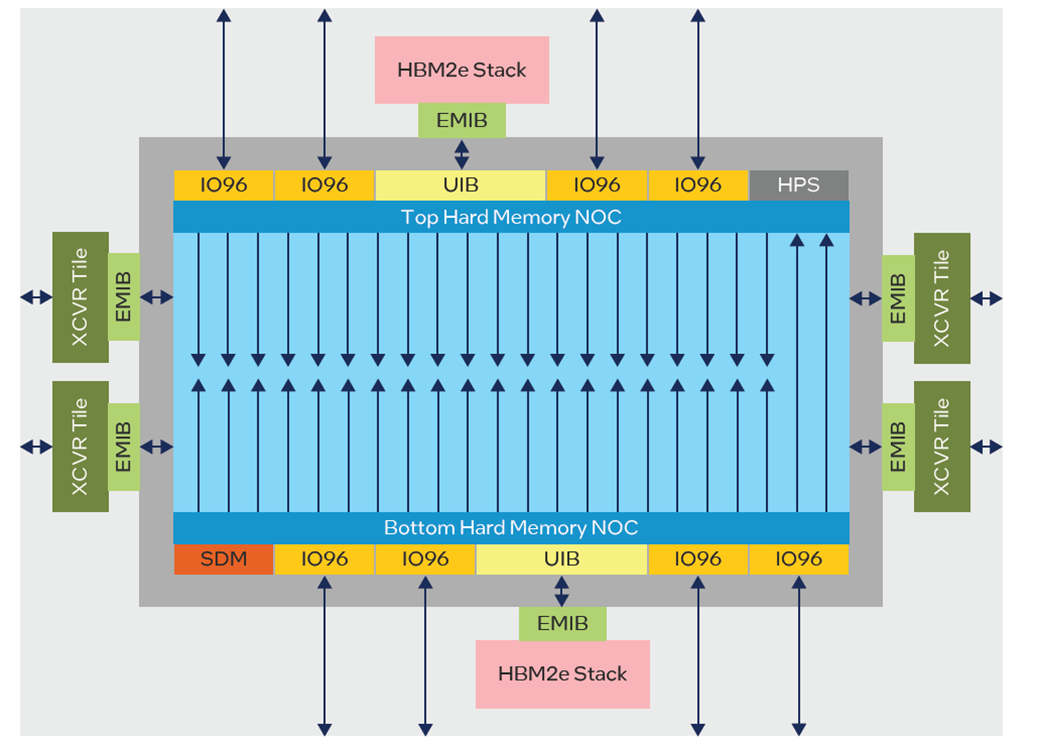
インテルAgilex 7 FPGAのMシリーズが登場したことで、NoCはより優れたメモリ性能を実現するために使用されるようになった。これは、HBM および DDR メモリ・インターフェイスへのアクセス向上に重点を置いています。従来、Stratix-10 MXでは、HBM間の共有アクセスが必要な場合、ユーザー・アービトレーション・ロジックが必要でした。現在では、NoCが各NAPのすべてのHBMメモリへのアクセスを提供します。Agilex Mシリーズ・デバイスには、デバイスの上部と下部の2つの水平NoCと、FPGAファブリックの奥深くへの高速アクセス用の複数の高速垂直NoCパスがあります。トップNoCには20個のNAP、ボトムNoCには22個のNAPがあり(図7)、これらは垂直NoCパスを介して相互に通信することもできる。NAPの数は、各接続インターフェース、HBM、DDR、および一般的なIOグループに1つの直接接続を提供するように設計されています。
図 7:Agilex M シリーズNoC
Agilex 7 M シリーズ FPGA は、BittWareに搭載されています。 IA-860mPCIe カードに搭載されています。
NoCを使用した広帯域外部メモリへの接続を最適化する方法をいくつか紹介する。
AchronixSpeedster7t は NoC を使用して、接続された GDDR6 メモリにアクセスします。完全な帯域幅(GDDR6あたり56 GBytes/秒、全体では448 GB/秒)を達成するには、各GDDR6に少なくとも875 MHzで動作する2つのAFUが必要で、これは256b幅のNAPではアグレッシブです。GDDR6 メモリコントローラが 8 つあることを考えると、あまりアグレッシブでないアプリ ケーションでは、GDDR6 帯域幅を飽和させるようなネットワークの競合がない 438MHz で動作するエンドポイントが最低 32 個必要になります。図 8 は、NoC の競合を回避するために AFU を分散させ、32 ポイントのエンドポイント設計を実装する方法を示しています。
図8:GDDR6メモリのピーク性能を達成するための最小構成
AFUが相互通信を必要とする場合、Speedster7t 、水平方向の通信とは独立して実行できる垂直方向のNoCルーティングが提供される。上記の例では、NoC上でメモリ性能を低下させることなく、AFUが情報を交換できるようになる。
図9:垂直NoCネットワークを使ったAFU間の通信
Agilex Mシリーズでは、HBMメモリはデバイスの上部に16個、下部に16個、合計32個の独立したメモリ・インターフェースとして提供される。バランスの取れた性能を実現するため、MシリーズNoCは、HBMとDDRの各メモリ・コントローラへの独自のネットワーク・ルートを持ち、これにより、NoCのレイテンシーが低く(ホップ数が少ない)、競合が少なくなるはずです(図10)。また、NoCはファブリック速度のみで動作する必要があるため、消費電力を大幅に削減できます。
図10:複数のエンドポイントを使用することで、Agilex MシリーズHBM帯域幅を最大化。
図10は、32個のエンドポイントがHBMメモリに並列にアクセスする設計で、NoCの競合がない場合に考えられるコンフィギュレーションを示しています。水平AFU間通信には、標準的なFPGA配線リソースを使用する必要があります。
FPGAはますます複雑化し、サポートされるインターフェイスも高速化しています。これらすべてのデバイスと通信するために必要なロジックは、FPGAリソースを大量に消費する可能性があります。これは特に、高級言語のボード・サポート・パッケージ(BSP)を作成する際に問題となります。NoCは、BSPができるだけ多くの外部インターフェイスに簡単にアクセスできるようにすることで、この問題を解決できます。これにより、BSPを小型化し、柔軟性を高め、開発しやすくすることができます。
NoCは性能と生産性の大幅な向上をもたらす。各チップ・ベンダーは、NoCコンセプトの使用目標が異なる独自のアプローチを採用している。いずれも、専用のオンチップ・ネットワークを使用しない場合に比べ、性能の大幅なステップアップを実現し、プログラマブル・ロジック・ゲートを消費することなくリソースを節約し、設計の柔軟性を向上させます。
FPGAアクセラレータカードについて詳しくはこちら→FPGAアクセラレータカードについて詳しくはこちら