FPGA 设备已变得越来越复杂,支持大量外部接口,如内存和网络连接。所需的众多接口的 IP 和通信逻辑会占用 FPGA 上大量的可重新配置资源,从而减少了可用于计算的逻辑。许多高速连接的互连所需的大量路由资源也会造成 FPGA 设计的瓶颈,导致工作频率降低,从而降低性能。 如果这些接口之间需要相互通信,情况更是如此。
片上网络(NoC)试图通过提供专用路由和交换逻辑来解决这一问题,使所有接口相互可见。这就用灵活的通用硬连线网络取代了使用 FPGA 门的用户定义逻辑。
NoC 提供了许多可供用户门访问的端点,可为连接到 NoC 的任何接口以及连接到不同端点的用户组件提供可寻址的访问。
图 1 展示了一个基本的 NoC,其中有多个用户端点,可访问连接到 NoC 上的多个存储器。NoC 与横梁不同,无论端点如何连接在一起,横梁通常都能提供相同的吞吐量。这意味着 NoC 在某些访问模式下容易出现拥塞。图 2 举例说明了拥塞是如何发生的。一些 NoC 试图通过以比 FPGA 逻辑高得多的频率运行网络结构或在高流量区域提供多路由来避免此类问题。
图 1:带有内存端点的 NoC 示例
图 2:当多个端点试图访问重叠的接口时,必须在 NoC 中共享路由逻辑。
使用 NoC 的一些好处是
使用 NOC 会增加一些设计挑战:
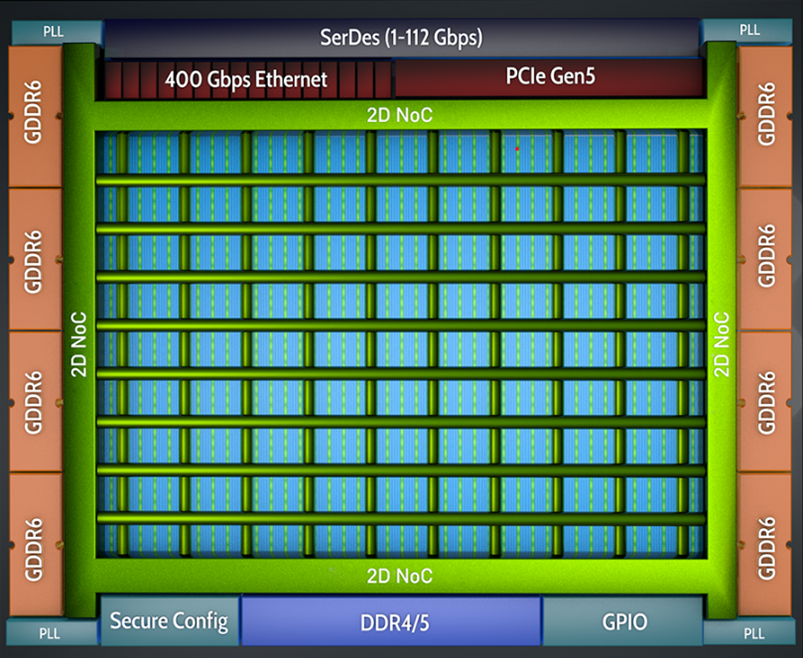
Achronix Speedster7t 设备使用 2D NOC,为分布在设备上的多个用户终端提供内存、PCIe 和以太网之间的连接(见图 3)。
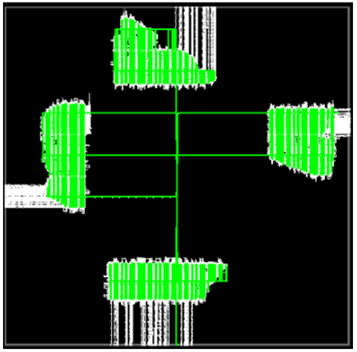
NoC 的二维分布允许器件的不同区域通过 8 条水平和 10 条垂直路由路径相互通信,而不会造成 FPGA 结构其余部分的拥塞。这就实现了 AFU 逻辑的良好分离,改善了路由,并最终提高了时钟频率。图 4 展示了这一行为,显示 4 个 AFU 通过 NoC 进行通信,但没有在芯片上分散逻辑。
图 3:使用 Achronix 2D NOC 的内部逻辑互连
图 4:使用 Achronix 2D NOC 的内部逻辑互连。
Achronix 还增加了 IP,将 400G 以太网数据自动划分为四个 100G 数据流,所有数据流都通过 NoC 接口进行管理。这样就能在 FPGA 用户结构中以更易于管理的时钟速度处理 400G 数据包。
BittWare 的 St7-VG6 PCIe 卡.
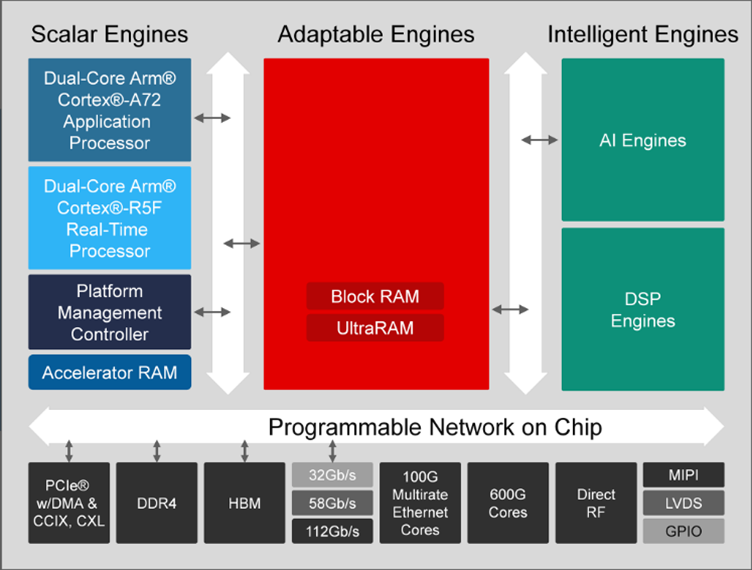
AMD ACAP 设备使用 NoC 在设备上的不同逻辑类型(如标量引擎、可重配置逻辑和 DSP/AI 引擎)之间进行通信。可编程逻辑中为用户提供了多个端点,允许与内存、人工智能、PCIe 端点进行通信(见图 5)。NoC 有水平和垂直路径,用于在 FPGA 中移动数据。NoC 路径的数量因器件而异。
图 5:配备可编程 NoC 的 AMD ACAP
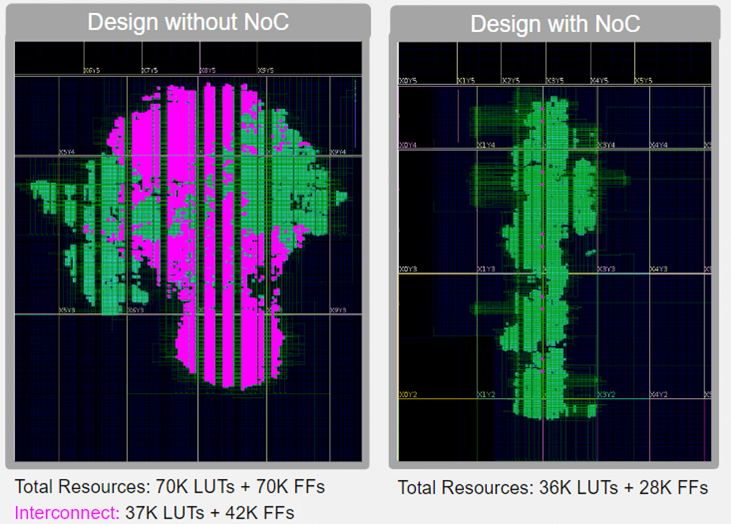
与在可编程逻辑中执行相同的通信相比,使用 NoC 可以节省资源。图 6 举例说明了这一点。这样一个简单的实际设计通常不会使用分组路由技术在模块之间进行通信,因此这种比较并不完全有效。不过,它确实说明了仅使用门实现这些网络所需的大量 FPGA 资源。
设备上的高速网络为用户提供了一种新的设计方法。以前,AFU 之间基于内部网络的通信速度很慢,而且需要大量资源,而 NoC 则使这种通信变得自由和快速。如果能将逻辑分离以使用 NoC 通信,其好处是设计更小,分离度更高,从而提高性能。在使用专用 NoC 时,路由结果也将更加一致,从而提高对设计性能估计的信心。
图 6:通过使用 NoC 节省资源
Versal 自适应 SoC 在 BittWare 的 AV-860h和 AV-870pPCIe 卡上。
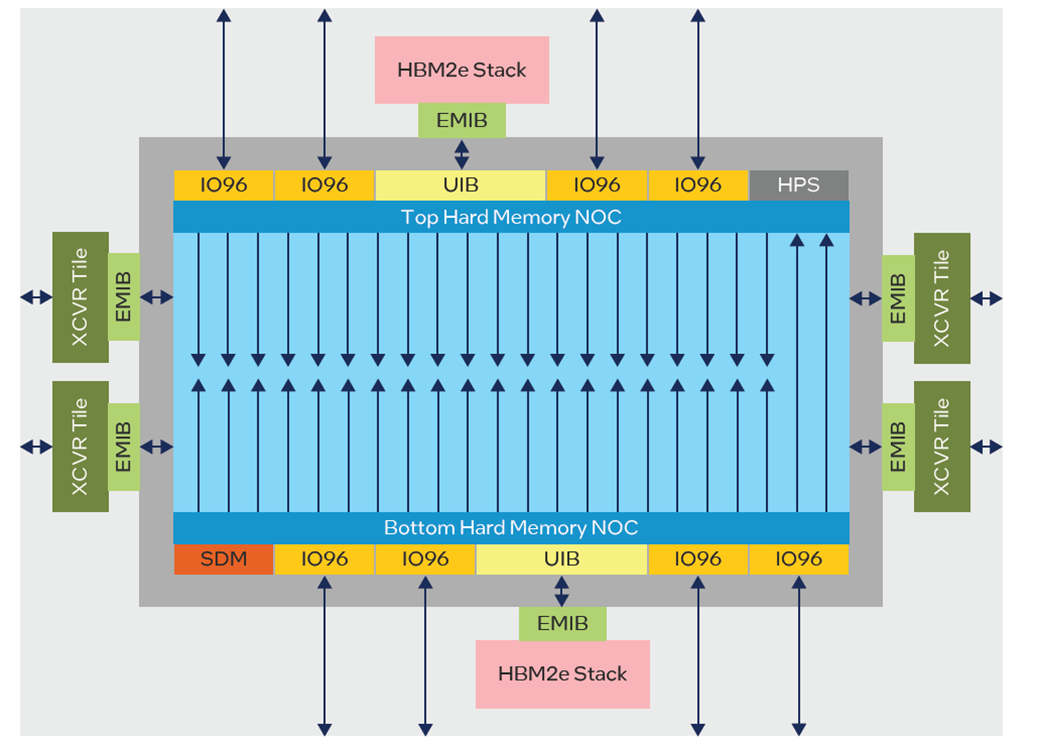
随着 M 系列英特尔 Agilex 7 FPGA 的推出,NoC 被用于提高内存性能。其重点是改进对 HBM 和 DDR 内存接口的访问,这些接口有很多。以前,在 Stratix-10 MX 上,如果需要在 HBM 之间共享访问,则需要用户仲裁逻辑。现在,NoC 为每个 NAP 提供对所有 HBM 内存的访问。Agilex M 系列器件有两个水平 NoC(器件顶部和底部)和多个高速垂直 NoC 路径,用于快速访问 FPGA 结构深处。顶部 NoC 有 20 个 NAP,底部 NoC 有 22 个 NAP(图 7),它们还可以通过垂直 NoC 路径相互通信。NAP 数量的设计目的是为每个连接接口、HBM、DDR 和通用 IO 组提供一个直接连接。
图 7:Agilex M 系列NoC
Agilex 7 M 系列 FPGA 采用 BittWare 的 IA-860mPCIe 卡上。
我们分享一些利用 NoC 优化与高带宽外部存储器连接的方法。
Achronix Speedster7t 利用 NoC 访问连接的 GDDR6 内存。要实现全带宽(每个 GDDR6 56 GBytes/Sec,或总体 448 GB/s),每个 GDDR6 需要两个至少以 875 MHz 运行的 AFU,这对于 256b 宽的 NAP 来说是比较激进的。考虑到有 8 个 GDDR6 内存控制器,不那么激进的应用至少需要 32 个端点,以 438 MHz 的频率运行,且没有网络冲突,使 GDDR6 带宽达到饱和。图 8 展示了如何实施 32 点端点设计,确保 AFU 分布合理,避免 NoC 冲突。
图 8:实现 GDDR6 内存峰值性能的最低配置
如果 AFU 需要相互通信,Speedster7t 提供的垂直 NoC 路由可独立于任何水平通信运行。在上述示例中,这将允许 AFU 交换信息,而不会降低 NoC 上的内存性能。
图 9:使用垂直 NoC 网络在 AFU 之间进行通信
在 Agilex M 系列上,HBM 内存以 32 个独立内存接口的形式呈现,其中 16 个位于设备顶部,16 个位于设备底部。为了实现均衡性能,M 系列 NoC 为每个内存控制器、HBM 和 DDR 提供了独特的网络路由,从而降低了延迟(跳数更少),减少了 NoC 上的冲突(图 10)。NoC 也只需要以 Fabric 速度运行,从而大大降低了功耗。
图 10:通过使用多个端点最大化 Agilex M 系列 HBM 带宽。
图 10 显示了 32 个端点并行访问 HBM 内存的设计的可能配置,没有 NoC 冲突。AFU 之间的水平通信需要使用标准 FPGA 路由资源。
FPGA 越来越复杂,支持的接口越来越多,速度越来越快。与所有这些设备通信所需的逻辑会消耗大量的 FPGA 资源。在创建高级语言电路板支持包(BSP)时,这尤其是一个问题。NoC 可以帮助 BSP 更容易地访问尽可能多的外部接口。这使得 BSP 更小、更灵活、更易于开发。
NoC 大大提高了性能和生产率。每个芯片供应商都有自己独特的方法,使用 NoC 概念的目标也各不相同。与不使用专用片上网络相比,它们都能大幅提升性能,节省资源,提高设计灵活性,而且不需要消耗可编程逻辑门。
了解更多关于我们的FPGA加速器卡→