FPGA 器件變得越來越複雜,支援多種外部介面,例如記憶體和網路連接。所需眾多介面的IP和通信邏輯可以吸收 FPGA 上的大量可重構資源,從而減少可用於計算的邏輯。互連許多高速連接所需的大量路由資源也可能導致FPGA設計出現瓶頸,從而導致工作頻率降低,從而降低性能。 如果這些介面之間需要相互通信,則尤其如此。
片上網路 (NoC) 試圖透過提供專用的路由和交換邏輯來解決這個問題,使所有介面彼此可見。這用靈活的通用硬連線網路取代了使用 FPGA 門的使用者定義邏輯。
NoC 提供了許多可供使用者入口訪問的端點,從而提供對連接到 NoC 的任何介面的可尋址訪問,以及也連接到不同端點的用戶元件。
圖 1 展示了一個具有多個使用者端點的基本 NoC,這些端點提供對幾個 NoC 連接記憶體的訪問。NoC 不像橫杆,無論端點如何連接在一起,它通常都能提供相同的輸送量。這意味著 NoC 容易受到某些訪問模式的擁塞的影響。圖 2 是擁塞如何發生的範例。一些 NoC 試圖通過以比 FPGA 邏輯高得多的頻率運行網路結構或在高流量區域提供多條路由來避免此類問題。
圖 1:具有記憶體端點的示例 NoC
圖 2:當多個端點嘗試訪問重疊介面時,必須在 NoC 中共用路由邏輯。
使用 NoC 的一些好處是:
使用 NOC 還存在一些額外的設計挑戰:
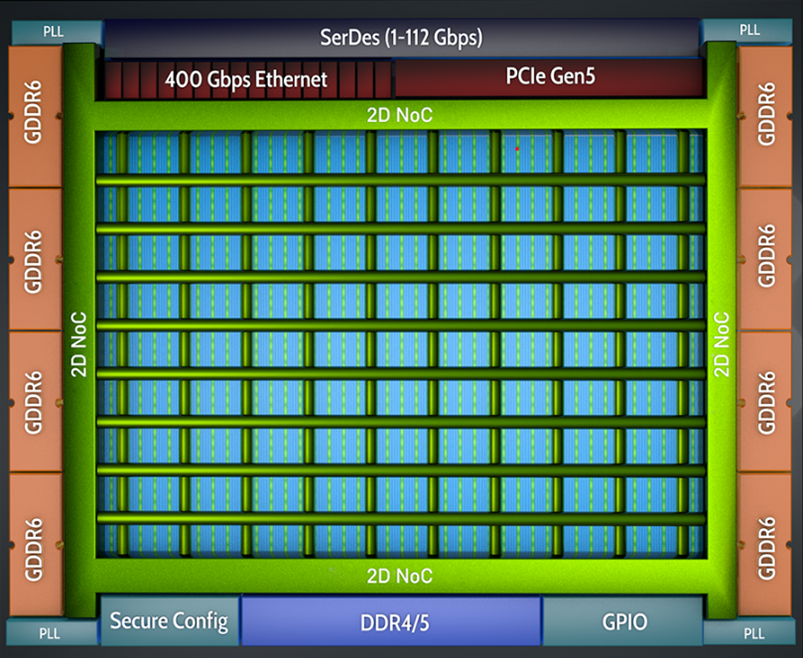
Achronix Speedster7t設備使用2D NOC,在記憶體、PCIe和乙太網之間提供與分佈在設備上的多個使用者端點的連接(見圖3)。
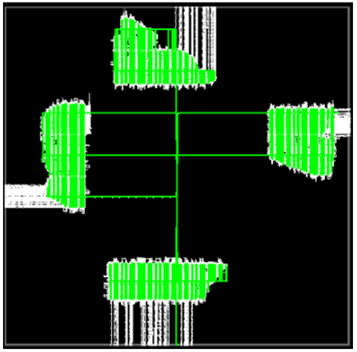
NoC 的 2D 分佈允許器件的不同區域通過 8 條水準和 10 條垂直佈線路徑相互通信,而不會在 FPGA 架構的其餘部分造成擁塞。這樣可以很好地分離 AFU 邏輯,改善路由並最終提高時鐘頻率。圖 4 說明瞭這種行為,顯示了 4 個 AFU 透過 NoC 進行通信,但沒有在晶片上擴展邏輯。
圖3:使用Achronix 2D NOC的內部邏輯互連
圖4:使用Achronix 2D NOC的內部邏輯互連。
Achronix還增加了IP,可以自動將400G乙太網數據分成四個100G流,全部通過NoC介面進行管理。這允許在FPGA用戶架構中以更易於管理的時鐘速度處理400G數據包。
Speedster7設備採用BittWare的St7-VG6 PCIe卡。
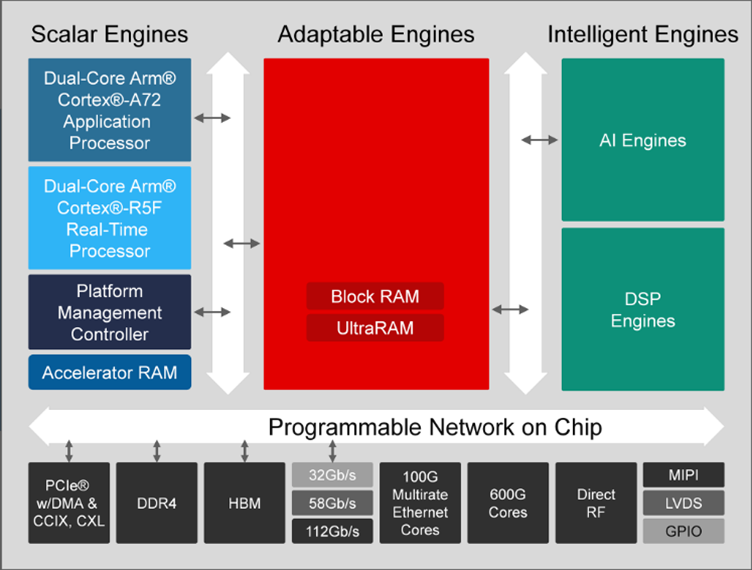
AMD ACAP 設備使用 NoC 在裝置上的不同邏輯類型之間進行通信,例如標量引擎、可重構邏輯和 DSP/AI 引擎。在可程式設計邏輯中向使用者提供了多個端點,允許與記憶體、AI、PCIe 端點進行通信(參見圖 5)。NoC 具有水平和垂直路徑,用於在 FPGA 周圍行動資料。NoC 路徑的數量因設備而異。
圖 5:具有可程式設計 NoC 的 AMD ACAP
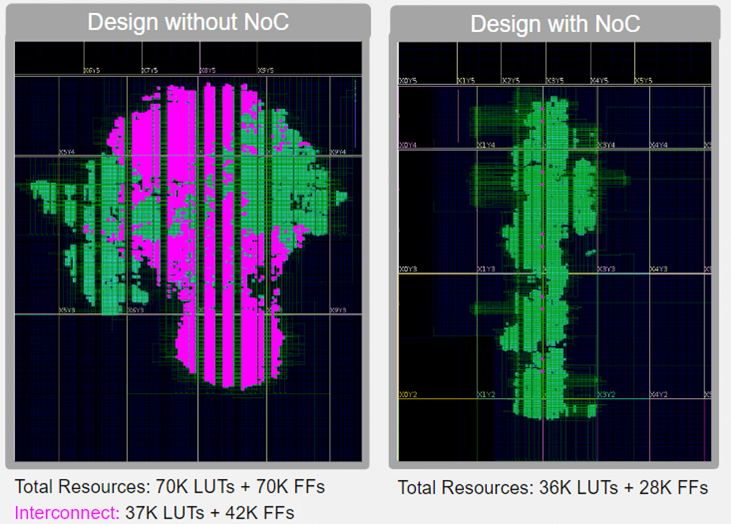
與在可程式設計邏輯中執行相同的通信相比,使用 NoC 可以節省資源。如圖 6 所示。這種簡單的實際設計通常不會使用數據包路由技術在模組之間進行通信,因此比較並不完全有效。然而,它確實說明瞭僅使用門實現這些網路所需的大量FPGA資源。
在設備上,高速網路為使用者提供了一種新的設計方法。以前,AFU 之間基於網路的內部通信速度很慢,需要大量資源,而 NoC 使這種通信變得免費且快速。如果可以分離邏輯以使用NoC通信,那麼其好處將是更小的設計,更好的分離,從而提高性能。使用專用 NoC 時,布線結果也將更加一致,從而增強了對設計性能估算的信心。
圖 6:使用 NoC 節省資源
Versal Adaptive SoC採用在BittWare的AV-860h和AV-870p PCIe卡上。
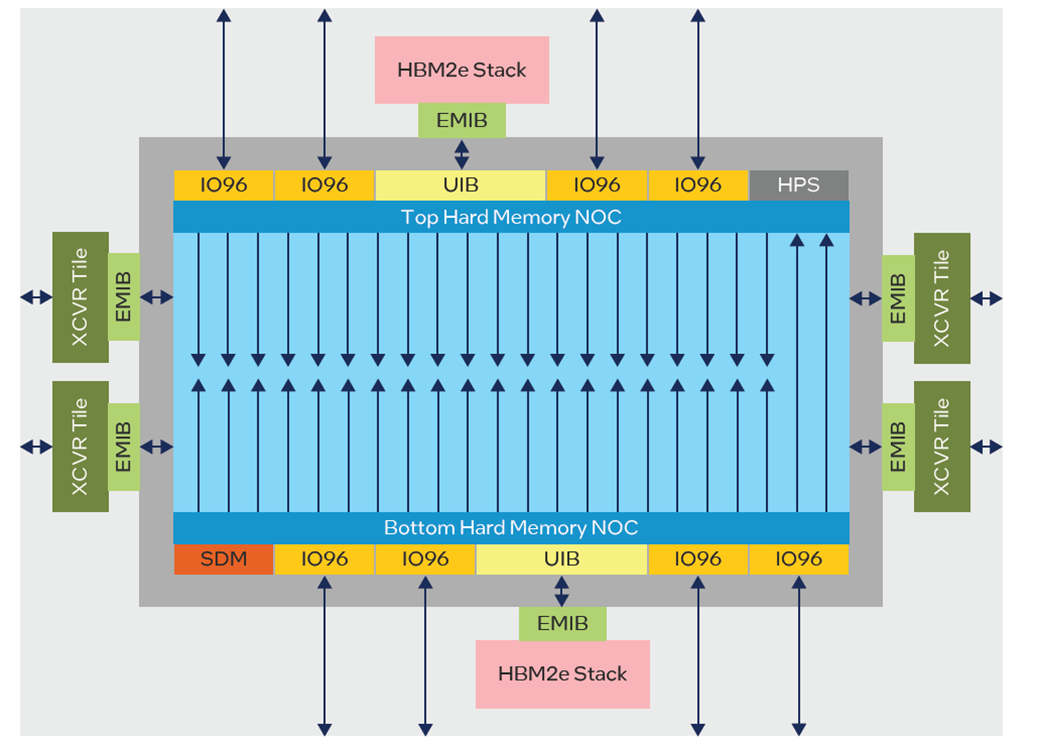
隨著英特爾 Agilex 7 FPGA 的 M 系列的推出,NoC 被用於獲得更好的記憶體性能。這主要集中在改善對 HBM 和 DDR 記憶體介面的訪問上,其中有很多。以前,在 Stratix-10 MX 上,如果需要 HBM 之間的共用訪問,則需要使用者仲裁邏輯。現在,NoC 為每個 NAP 提供對所有 HBM 記憶體的訪問。Agilex M系列器件具有兩個水準NoC,即器件的頂部和底部,以及多個高速垂直NoC路徑,可快速深入FPGA架構。頂部的 NoC 有 20 個 NAP,底部的 NoC 有 22 個 NAP(圖 7),它們也可以通過垂直 NoC 路徑相互通信。NAP 的數量被設計為為為每個連接的介面、HBM、DDR 和通用 IO 組提供一個直接連接。
圖 7:Agilex M-S系列 NoC
Agilex 7 M系列FPGA採用在BittWare 的IA-860m PCIe卡上。
我們分享了一些使用 NoC 優化與高頻寬外部記憶體連接的方法。
Achronix Speedster7t使用NoC提供對連接的GDDR6記憶體的訪問。為了實現全頻寬(每個 GDDR6 為 56 GBytes/秒,或總 448 GB/s),每個 GDDR6 需要兩個至少以 875 MHz 運行的 AFU,這對於 256b 寬的 NAP 來說是激進的。假設有 8 個 GDDR6 記憶體控制器,那麼一個不太激進的應用程式至少需要 32 個端點,以 438 MHz 的速度運行,沒有網路衝突來使 GDDR6 頻寬飽和。圖 8 說明瞭如何實現 32 點端點設計,確保 AFU 分佈以避免 NoC 衝突。
圖 8:從 GDDR6 記憶體實現峰值性能的最低配置
如果 AFU 需要相互通信,Speedster7t 提供垂直 NoC 路由,可以獨立於水平發生的任何通信運行。對於上面的示例,這將允許 AFU 在不降低 NoC 記憶體性能的情況下交換資訊。
圖 9:使用垂直 NoC 網路在 AFU 之間進行通信
在 Agilex M 系列上,HBM 記憶體以 32 個獨立記憶體介面的形式呈現,其中 16 個位於設備頂部,16 個位於設備底部。為了實現平衡的性能,M 系列 NoC 具有到每個記憶體控制器 HBM 和 DDR 的唯一網路路由,這應該會產生更低的延遲(更少的跳數)和更少的 NoC 衝突(圖 10)。NoC 也只需要以結構速度運行,從而大大降低了功耗。
圖 10:使用多個端點最大化 Agilex M 系列 HBM 帶寬。
圖 10 顯示了一種可能的設計配置,其中 32 個端點並行訪問 HBM 記憶體,沒有 NoC 衝突。AFU之間的水準通信需要使用標準的FPGA路由資源。
FPGA 變得越來越複雜,支援更多、更快的介面。與所有這些器件通信所需的邏輯可能會消耗大量的FPGA資源。在創建高級語言板支援包 (BSP) 時,這尤其是一個問題。NoC 可以在這方面提供説明,讓 BSP 更容易存取盡可能多的外部介面。這允許更小、更靈活、更易於開發 BSP。
NoC 顯著提高了性能和生產力。每個晶片供應商都有獨特的方法,使用NoC概念的目標不同。與不使用專用片上網路相比,所有這些都顯著提高了性能,從而節省了資源並提高了設計靈活性,而無需使用可程式設計邏輯門。
瞭解有關我們的 FPGA 加速卡的更多資訊→