FPGA 장치는 메모리 및 네트워크 연결과 같은 수많은 외부 인터페이스를 지원하면서 점점 더 복잡해지고 있습니다. 필요한 수많은 인터페이스에 대한 IP와 통신 로직은 FPGA에서 재구성 가능한 리소스를 상당수 흡수하여 컴퓨팅에 사용할 수 있는 로직을 감소시킬 수 있습니다. 또한 많은 고속 연결을 상호 연결하는 데 필요한 방대한 수의 라우팅 리소스는 FPGA 설계에서 병목 현상을 일으켜 작동 주파수를 낮추고 결과적으로 성능을 저하시킬 수 있습니다. 이러한 인터페이스 간의 상호 통신이 필요한 경우 특히 그렇습니다.
네트워크 온 칩(NoC)은 모든 인터페이스를 서로 볼 수 있도록 전용 라우팅 및 스위칭 로직을 제공하여 이 문제를 해결하려고 시도합니다. 이는 FPGA 게이트를 사용하는 사용자 정의 로직을 유연한 일반 유선 네트워크로 대체합니다.
NoC는 사용자 게이트에 액세스할 수 있는 여러 엔드포인트를 제공하여 NoC에 연결된 모든 인터페이스와 다른 엔드포인트에 연결된 사용자 구성 요소에 대한 주소 지정이 가능한 액세스를 제공합니다.
그림 1은 여러 사용자 엔드포인트가 두 개의 NoC에 연결된 메모리에 대한 액세스를 제공하는 기본 NoC를 보여줍니다. NoC는 일반적으로 엔드포인트의 연결 방식에 관계없이 동일한 처리량을 제공하는 크로스바와는 다릅니다. 즉, NoC는 특정 액세스 패턴으로 인한 혼잡에 취약합니다. 그림 2는 혼잡이 어떻게 발생할 수 있는지 보여주는 예시입니다. 일부 NoC는 FPGA 로직보다 훨씬 높은 주파수로 네트워크 패브릭을 실행하거나 트래픽이 많은 지역에 여러 경로를 제공함으로써 이러한 문제를 피하려고 시도합니다.o
그림 1 : 메모리 엔드포인트가 있는 NoC 예시
그림 2 : 여러 엔드포인트가 겹치는 인터페이스에 액세스하려는 경우 라우팅 로직은 NoC에서 공유되어야 합니다.
NoC를 갖춘 FPGA의 장점
NoC 사용의 몇 가지 이점은 다음과 같습니다:
NoC를 사용하면 여러 메모리 또는 이더넷 인터페이스에 대한 공유 액세스가 필요한 설계를 위해 맞춤형 중재 로직을 설계할 필요가 없습니다. AFU 엔드포인트는 연결된 다른 모든 AFU와 메모리를 볼 수 있으므로 올투올 통신을 더 쉽게 구현할 수 있습니다.
일반적인 FPGA 라우팅 로직에서 메모리 간 통신을 제거함으로써 FPGA 배치 및 라우팅 툴은 리소스를 더 잘 분리하여 배치를 훨씬 쉽게 찾을 수 있습니다. 따라서 목표 클럭 주파수를 달성할 가능성이 높아집니다.
일부 NoC는 PCIe 인터페이스를 통해 호스트에서 디바이스 메모리로 직접 액세스할 수 있어 애플리케이션 작업을 위한 FPGA 패브릭을 다시 절약할 수 있습니다.
외부 메모리 중재 로직은 여러 NoC 인터페이스를 통해 제공되며, 서비스 품질(QoS)이 NoC에 내장되어 있습니다. 여러 AFU가 사용자 지정 IP 없이도 동일한 리소스를 공유할 수 있습니다.
NOC 사용에는 몇 가지 추가적인 설계 과제가 있습니다:
NoC는 고속 네트워크이므로 일반 FPGA 로직에 비해 상대적으로 많은 양의 전력이 필요할 수 있습니다. 이는 더 적은 FPGA 리소스 사용으로 인한 전력 절감과 균형을 맞춰야 합니다. NoC 작동 주파수를 낮추고 사용하지 않는 NoC 요소를 끄면 전력 소비를 줄일 수 있습니다.
NoC 내의 스위칭 로직은 외부 통신에 지연 시간을 추가합니다. 애플리케이션이 지연 시간에 민감한 경우 NoC 사용을 피해야 합니다. 이 시나리오에서는 일반적으로 NoC를 우회하기 위해 일부 직접 연결이 제공됩니다.
NoC가 있는 FPGA 디바이스
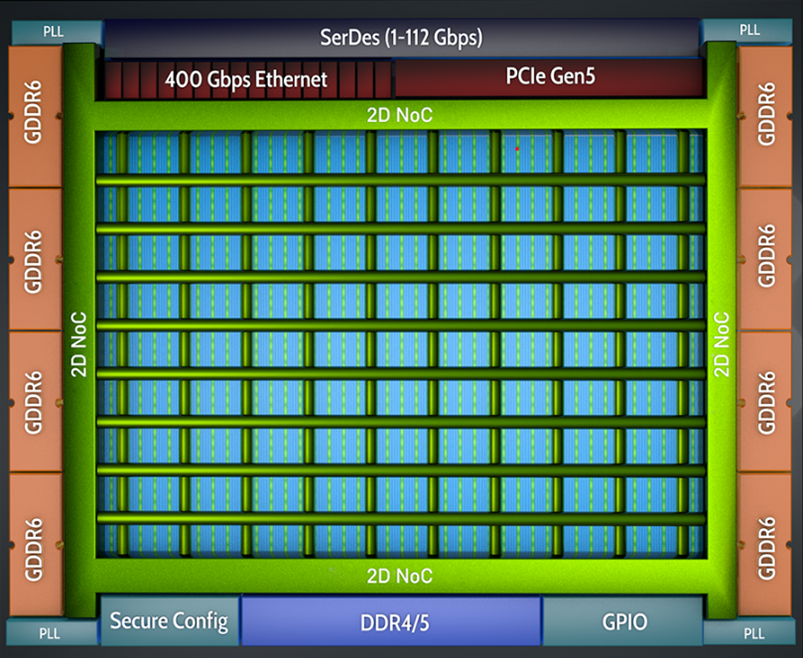
Achronix 2D NoC
Achronix Speedster7t 디바이스는 디바이스 전체에 분산된 여러 사용자 엔드포인트에 메모리, PCIe, 이더넷 간 연결을 제공하는 2D NOC를 사용합니다(그림 3 참조).
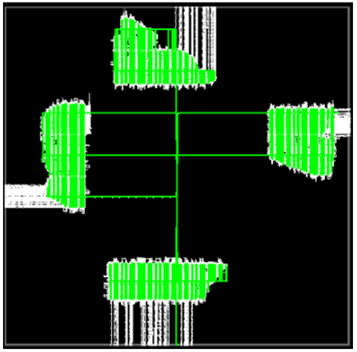
NoC의 2D 분포는 8개의 수평 및 10개의 수직 라우팅 경로를 통해 장치의 서로 다른 영역이 나머지 FPGA 패브릭 내에서 혼잡을 일으키지 않고 서로 통신할 수 있도록 합니다. 이를 통해 AFU 로직이 잘 분리되어 라우팅이 개선되고 궁극적으로 클럭 주파수가 증가합니다. 그림 4는 이 동작을 보여 주며, 4개의 AFU가 NoC를 통해 통신하지만 칩 전체에 로직이 분산되지 않은 상태를 보여줍니다.
그림 3: Achronix 2D NOC를 사용한 내부 로직 상호 연결
그림 4 : Achronix 2D NOC를 사용한 내부 로직 상호 연결.
또한 Achronix는 400G 이더넷 데이터를 4개의 100G 스트림으로 자동 분할하는 IP를 추가했으며, 모두 NoC 인터페이스를 통해 관리됩니다. 이를 통해 FPGA 사용자 패브릭 내에서 400G 패킷을 보다 관리하기 쉬운 클럭 속도로 처리할 수 있습니다.
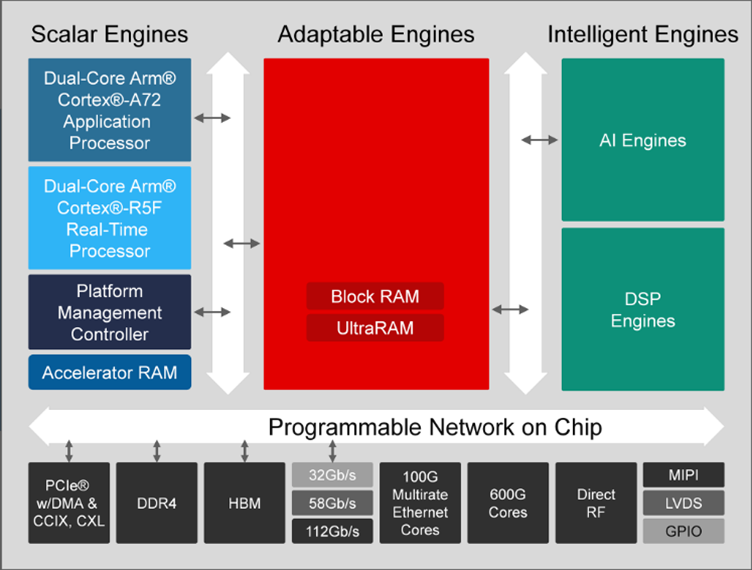
AMD ACAP 장치는 스칼라 엔진, 재구성 가능 로직 및 DSP/AI 엔진과 같은 장치 상의 서로 다른 로직 유형 간 통신을 위해 NoC를 사용합니다. 프로그래머블 로직에서 메모리, AI, PCIe 엔드포인트와 통신할 수 있는 여러 엔드포인트가 사용자에게 제공됩니다(그림 5 참조). NoC에는 FPGA 주변에서 데이터를 이동하기 위한 수평 및 수직 경로가 있습니다. NoC 경로의 수는 디바이스마다 다릅니다.
그림 5: 프로그래머블 NoC를 갖춘 AMD ACAP
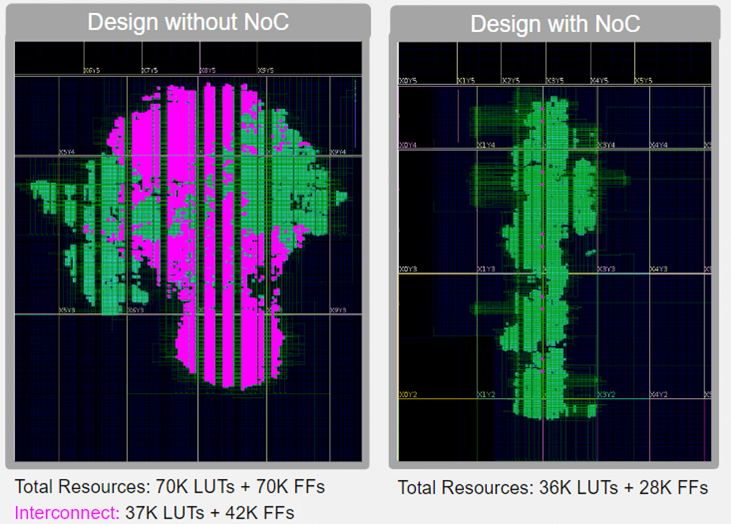
NoC를 사용하면 프로그래머블 로직 내에서 동일한 통신을 수행할 때보다 리소스를 절약할 수 있습니다. 이는 그림 6에 설명되어 있습니다. 이러한 단순한 실제 설계에서는 일반적으로 모듈 간 통신에 패킷 라우팅 기술을 사용하지 않으므로 비교가 완전히 유효하지는 않습니다. 하지만 게이트만 사용하여 이러한 네트워크를 구현하는 데 필요한 FPGA 리소스의 수가 상당하다는 것을 보여줍니다.
온 디바이스 고속 네트워크는 사용자에게 새로운 설계 방식을 제공합니다. 이전에는 내부 네트워크 기반 AFU 간 통신이 느리고 상당한 리소스가 필요했지만, NoC는 이를 자유롭고 빠르게 만듭니다. 로직을 분리하여 NoC 통신을 사용할 수 있다면 설계가 더 작아지고, 분리가 잘되어 성능이 향상되는 이점이 있습니다. 또한 전용 NoC를 사용하면 라우팅 결과가 더 일관적이므로 설계 성능 예측에 대한 신뢰도가 높아집니다.
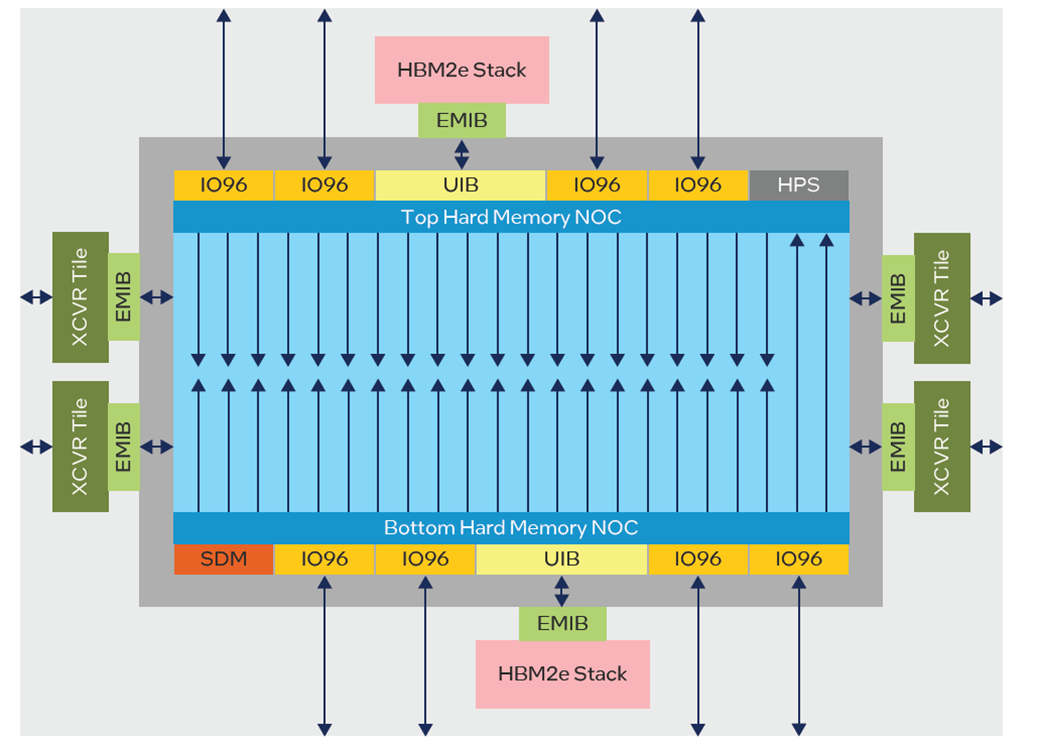
인텔 애자일렉스 7 FPGA의 M 시리즈가 도입되면서 메모리 성능 향상을 위해 NoC가 사용되었습니다. 이는 많은 HBM 및 DDR 메모리 인터페이스에 대한 액세스를 개선하는 데 중점을 두었습니다. 이전에는 Stratix-10 MX에서 HBM 간 공유 액세스가 필요한 경우 사용자 중재 로직이 필요했습니다. 이제 NoC는 각 NAP의 모든 HBM 메모리에 대한 액세스를 제공합니다. Agilex M 시리즈 디바이스에는 디바이스의 상단과 하단에 두 개의 수평 NoC가 있으며, FPGA 패브릭 깊숙한 곳까지 빠르게 액세스할 수 있는 여러 고속 수직 NoC 경로가 있습니다. 상단 NoC에는 20개의 NAP가 있고 하단 NoC에는 22개의 NAP가 있으며(그림 7), 수직 NoC 경로를 통해 서로 통신할 수도 있습니다. NAP의 개수는 연결된 각 인터페이스, HBM, DDR 및 일반 IO 그룹에 하나의 직접 연결을 제공하도록 설계되었습니다.
그림 7: Agilex M-시리즈NoC
Agilex 7 M-시리즈 FPGA는 BittWare의 IA-860m PCIe 카드에 탑재되어 있습니다.
성능 극대화
NoC를 사용하여 고대역폭 외부 메모리에 대한 연결을 최적화하는 몇 가지 방법을 공유합니다.
Achronix Speedster7t는 NoC를 사용하여 연결된 GDDR6 메모리에 대한 액세스를 제공합니다. 전체 대역폭(GDDR6당 초당 56GBytes 또는 전체 448GB/s)을 달성하려면 각 GDDR6에 최소 875MHz로 실행되는 2개의 AFU가 필요하며, 이는 256b 폭의 NAP에는 공격적인 수준입니다. GDDR6 메모리 컨트롤러가 8개라고 가정할 때, 덜 공격적인 애플리케이션은 네트워크 충돌 없이 438MHz로 실행되는 최소 32개의 엔드포인트가 있어야 GDDR6 대역폭을 포화시킬 수 있습니다. 그림 8은 32개 엔드포인트 설계를 구현하여 NoC 충돌을 피하기 위해 AFU를 분산하는 방법을 보여줍니다.
그림 8: GDDR6 메모리에서 최고 성능을 달성하기 위한 최소 구성
AFU에 상호 통신이 필요한 경우, Speedster7t는 수평으로 발생하는 통신과 독립적으로 실행할 수 있는 수직 NoC 라우팅을 제공합니다. 위의 예에서 이 기능을 사용하면 AFU가 NoC를 통해 메모리 성능 저하 없이 정보를 교환할 수 있습니다.
그림 9: 수직형 NoC 네트워크를 사용하여 AFU 간 통신하기
Agilex M 시리즈에서 HBM 메모리는 32개의 독립적인 메모리 인터페이스(디바이스 상단에 16개, 하단에 16개)로 제공됩니다. 균형 잡힌 성능을 위해 M 시리즈 NoC에는 각 메모리 컨트롤러, HBM 및 DDR에 대한 고유한 네트워크 경로가 있으므로 지연 시간이 짧고(홉 수가 적음) NoC에서 충돌이 적어야 합니다(그림 10). 또한 NoC는 패브릭 속도로만 실행하면 되므로 전력을 크게 절감할 수 있습니다.
그림 10: 여러 엔드포인트를 사용하여 Agilex M 시리즈 HBM 대역폭 최대화.
그림 10은 32개의 엔드포인트가 병렬로 HBM 메모리에 액세스하는 설계의 가능한 구성을 보여주며, NoC 충돌이 없습니다. 수평 AFU 간 통신에는 표준 FPGA 라우팅 리소스를 사용해야 합니다.
고급 도구 사용 시 리소스 절약하기
FPGA는 점점 더 많은 인터페이스가 지원되면서 점점 더 복잡해지고 있습니다. 이러한 모든 장치와 통신하는 데 필요한 로직은 상당한 양의 FPGA 리소스를 소모할 수 있습니다. 이는 특히 하이레벨 언어 보드 지원 패키지(BSP)를 만들 때 문제가 됩니다. NoC는 BSP가 가능한 한 많은 외부 인터페이스에 쉽게 액세스할 수 있도록 함으로써 이 문제를 해결할 수 있습니다. 이를 통해 더 작고, 더 유연하며, 더 쉽게 BSP를 개발할 수 있습니다.
결론
NoC는 성능과 생산성을 크게 향상시킵니다. 칩 공급업체마다 NoC 개념 사용에 대한 목표가 다른 고유한 접근 방식을 가지고 있습니다. 모두 전용 온칩 네트워크를 사용하지 않을 때보다 성능이 크게 향상되어 프로그래머블 로직 게이트를 사용하지 않고도 리소스를 절약하고 설계 유연성을 높일 수 있습니다.