EdgeCortix Dynamic Neural Accelerator (DNA)は、高い計算能力、超低レイテンシー、スケーラブルな推論エンジンを備えた深層学習推論用の柔軟なIPコアで、Agilex FPGAを搭載したBittWareカードに搭載されています。
ストリーミングデータや高解像度データ(バッチサイズ1)での推論に特別に最適化されたDNAは、特許取得済みの再構成可能なIPコアで、エッジコーティックスのMERA™ソフトウェアフレームワークと組み合わせることにより、今日の複雑化し計算量の多いAIワークロードをシームレスにアクセラレーション 、90%以上の配列利用率を達成します。
 この専用IPコアは、統合コンパイルライブラリとランタイムを提供するMERAフレームワークによって補完され、ソフトウェアエンジニアは、PyTorchやTensorFlowなどの標準フレームワークの快適な領域を離れることなく、Bittware IA-840f および IA-420f FPGAカードを標準CPUやGPUのドロップイン置き換えとして使用できます。 DNA bitstreams forAgilex は、競合するFPGAと比較して2倍から6倍の性能差で、ストリーミングデータに対する推論レイテンシーを大幅に低減し、他の汎用プロセッサと比較して電力効率に優れています。
この専用IPコアは、統合コンパイルライブラリとランタイムを提供するMERAフレームワークによって補完され、ソフトウェアエンジニアは、PyTorchやTensorFlowなどの標準フレームワークの快適な領域を離れることなく、Bittware IA-840f および IA-420f FPGAカードを標準CPUやGPUのドロップイン置き換えとして使用できます。 DNA bitstreams forAgilex は、競合するFPGAと比較して2倍から6倍の性能差で、ストリーミングデータに対する推論レイテンシーを大幅に低減し、他の汎用プロセッサと比較して電力効率に優れています。
マーカス・ウェドルBittWare
BittWareのマーカスです。 EdgeCortixの機械学習フレームワークについて お話を伺いますが、その前に少し背景を説明します。 今、人工知能が話題になっていますが 話題になったのは10年程前からです。 AIを使うといった発想はもっと古いのにも関わらず、 一体、何がきっかけでしょうか。 GPUやFPGA等のハードウェアアクセラレーション、 最近では特化したASICにその答えはあります。 これらのデバイスが、新技術を開発する研究者や 需要を生み出す商業アプリケーションに対して AIの分野を開放しました。 さらにエキサイティングなことに、私たちはAIの技術、 ハードウェアの性能、ユースケースの拡大という 成長曲線の真っ只中にいます。 AIは大きなテーマですが、今日はエッジでの機械学習、 つまりクラウドやデータセンター環境以外の ユースケースに焦点を当てます。 エッジデバイスでは、効率性が非常に重要です。 EdgeCortix では、FPGA の独自の利点を活かして、 ワークロードに合わせ、再トレーニングを不要とする 適応性の高いソフトウェアを提供することに注力しています。 EdgeCortix の創業者兼CEOのサキャシンガ ダスグプタ氏を お迎えしてお話を伺います。ようこそ。
EdgeCortixの創立者 兼 CEO サキャシンガ ダスグプタ博士
お話できるのを楽しみにしていました。
マーカス
エッジを定義するところから始めましょう。 例えば、機械学習の推論を全てクラウドやデータセンタで 行うのはいかがでしょうか。 なぜ、わざわざエッジで行う必要があるのでしょうか。
サクヤ
機械学習の推論ソリューションの展開に クラウドやデータセンタを利用すると 5つの大きな課題により大きな制限が生じます。
まずは、クラウドでの情報処理に必要なコスト。2つ目は、消費電力、あるいは電力効率やエネルギー効率と呼ばれるもの。3つ目は、最大の課題としてモデルによるもの、すなわち、ニューラルネットワーク自体の複雑さにあります。
そして、4つ目の課題は、クラウド上で情報を処理し、保存しようとするデータのプライバシーに関するものです。最後に、レイテンシや帯域幅の制約が生じることです。
では、もう少し詳しく説明しましょう。
コスト
コスト面を考えると、クラウドネイティブのソリューションでは、 計算だけでなく大量のデータの保存に発生するコストが高く、限度があります。 多くの場合、データ量はペタバイトとなります。
エッジに注目すると、機械学習の中で意味のあるデータの75%は エッジデバイスやエッジサービスと呼ばれるものに近いところに存在しています。 そのため、全てのデータをクラウドに移動させ 処理・計算することはコスト面で大きな課題となります。
電力効率
クラウド上の多くのシステムは消費電力がキロワット以上となり 仮に消費電力自体が問題にならないケースであっても、機械学習やAI推論は計算リソースを大きく消費します。
モデルの複雑さ
これらのモデルは非常に複雑なため ほとんどのモデルはクラウド上でトレーニングされています。 そのため、複雑なモデルをエッジに持ち込もうとすると デバイスのリソースが限られているという点でボトルネックになります。 結果として、クラウドベースのデプロイにはあまり向いていません。
プライバシー
すべてのデータをエッジに近づけてからクラウドに戻すと、 データのプライバシーが失われる可能性があります。 ヘルスケア・アプリケーション等がその一例です。
レイテンシ
大量のデータを移動させ、クラウド上で処理するには 多くのレイテンシが発生します。 ほとんどのリアルタイム・アプリケーションでは 7ミリ秒から10ミリ秒以下の処理を必要とします。 そのため、リアルタイム性が求められるアプリケーションにおいて クラウドネイティブのソリューションを利用しようとすると この問題は解決されません。
このように、機械学習をクラウドベースのソリューションに限定することが 理想的なシナリオであるとは言えない理由があります。
マーカス
納得です。FPGA をデプロイのプラットフォームの 1 つとして 「協調探索」というプロセスを使用したそうですね。
また、FPGA がエッジ推論に適しているという具体的な利点についても教えてください。
サクヤ
はい。良い質問ですね。 機械学習の推論、特にディープニューラルネットワークに目を向けると、 FPGAはそれ自体が柔軟性を持つという大きな利点があります。 多層で構成されるニューラルネットワークを見た場合、それはニューラルネットワークの1層内でも異なるネットワーク間で比較を行う場合と同じように多くの異質性がありますが、FPGAではハードウェアプラットフォームの動作を変化させることで対応ができます。
第二に、ニューラルネットワークの計算の多くは CPUのように中央で制御されるものではありません。 フォン・ノイマン型のようなものではなく データフローグラフで表現できる複数の並列度を含みます。
その結果、協調設計または協調探索と呼ばれるこのアプローチでは、 典型的なニューラルネットワークやディープニューラルネットワークの精度要件と、レイテンシ、メモリ、電力などの注目すべきハードウェアメトリックとのバランスを取ろうとしており、 従来の並列性を利用するために、プロセッサのアーキテクチャを調整することができます。 そうすることで、多くの場合ハードウェアの利用率を効果的に大幅に向上させることができます。 特に、GPUやCPUのような汎用プロセッサと比較した場合、その効果は絶大です。
そこで当社では、Dynamic Neural AcceleratorのIPとMERAソフトウェアの設計を、 「協調設計」というアプローチで緊密に連携させることにしました。
また、基本的には、同じアプローチを使用すれば これらの異なるモデルの高い精度を維持するために必要な情報の処理精度や解像度と、 モデルのメモリフットプリントを削減し、FPGA にもともと備わっている限られた量のメモリに最適にフィットするように、トレードオフのバランスを取ることができます。 このように、INT8ビットは、推論を最適な精度で実行することと、 元々備えていた精度を大幅に維持することのトレードオフであり、 オンボードで直接必要となるメモリ量を最適化し、 FPGAからオフチップへ転送するデータ量に制限されずに 演算を行うことができると判断しました。
その結果、全体としてFPGAは、プロセッサ設計を調整する柔軟性と 協調設計や協調探索のプロセスによって駆動する計算効率を制御するバランスがとれています。
マーカス
ワークロードが変化したり、他のハードウェアの機能として、例えば専用のDSPブロックが搭載されたりすることで、将来的にINT8から揺らぐようなことはないでしょうか?
サクヤ
ええ、その通りです。 このプロセスを開始したとき、現在サポートしている精度は INT8ビット表現だけではありませんでした。 私たちのアーキテクチャがサポートする精度は、 浮動小数点16ビット、INT8ビットとさまざまで、 ニューラルネットワークのウェイトやパラメータの表現と、 アクティベーションの保存に使用する精度で異なる場合があります。
この協調設計プロセスは、デプロイの段階を通して継続するプロセスです。
基本的に、協調設計において根本的なプロセッサのアーキテクチャはこれ以上変えられません。 しかし、例えば、ニューラルネットワークのモデルが変化したり、 アップデートが行われる場合でも、精度やレイテンシの要件に合うように、 プロセッサアーキテクチャの部分を再設計することができます。
先ほどの質問に戻りますが、FPGAの利点は、必要に応じてプロセッサのアーキテクチャを柔軟に変更できることです。 一方、ASICなどのハードウェアは、一度製造すると固定されてしまうため、FPGAのような柔軟性はありません。
マーカス
では、具体的なハードウェアの話をしましょう。 BittWareでは、EdgeCortixのIPとソフトウェアをフレームワークとして、弊社のIntel Agilexベースのカードで利用できるようにしています。 Agilexの性能および、PCIe Gen4の帯域幅を拡張することの利点について教えてください。
サクヤ
もちろんです。当社のAIアクセラレーションIPと新しいIntel Agilexカードを組み合わせることで、多くの利点が得られると考えています。 BittWareのダブルワイドFPGAカードとロープロファイルFPGAカードの2つのフォームファクタをサポートすることで、特にTeraBoxサーバーとバンドルする場合、ユーザーが計算、電力、コストにおいて理想的な選択をすることが可能になります。 これにより、エッジアプリケーションに要求される厳しい環境下でもFPGAによる高速化が可能になると考えています。
Intel Agilexは、Intelの最新世代のシリコンです。 これらのFPGAはそれぞれ、重要なFPGAリソースと電力を節約するために、 PCIeプロトコル・サポートを強化しています。 これは、AIと他のタイプのFPGAアクセラレーションが共存する多くのアプリケーションにとって実に重要なことです。
また、Intel Agilexは、第2世代のHYPERFLEXアーキテクチャをベースにしています。これにより、ハード化されたDSPブロックがもたらされ、当社の場合、何千ものINT8演算子と、IPを簡単に拡張できる統一された構造を実現することができました。
さらに、これらのFPGAカードでPCIe Gen 4をサポートすることで、 PCIe Gen 3のような前世代の帯域幅と比較して30%以上の向上が可能になります。 これは、機械学習の推論に非常に大きな影響を与えるもので、 高解像度のデータをホストからFPGAへ、そしてその間を頻繁に行き来することになります。 その結果として、より多くの帯域を利用できるようにすること、つまり速度を上げることは、全体の効率や性能に劇的な影響を与えます。
また、根本的にはDDR4対応ということで十分な量のメモリが利用可能であることが挙げられます。 ダブルワイドFPGAカードでは、最大128ギガバイトまでが利用可能です。 この比較的大容量のFPGAのオンチップ、BRAMと組み合わせれば、 多くのアプリケーションにおいて優れたスケーラビリティを実現できると信じています。
Intel Agilexと当社のIPを組み合わせることで、最大20TOPSの専用AIコンピュートを実現することができました。そして、現在市場で競合する他のFPGAアクセラレーション・ソリューションと比較すると、6倍の性能優位性をもたらすことができると考えています。
マーカス
分かりました。 では、次にBittWareのカードと他のソリューションを比較したグラフを見てみましょう。 ロープロファイルのIA-420Fが6〜7倍、IA-840Fがそれ以上です。とても印象的ですね。 このチャートでGPUを見てみましょう。 現在、Agilexで20TOPSを実現したとのことでしたが、過去にはGPUのTOPSの活用の仕方に違いがあるとおっしゃっていましたね。 その違いは具体的に何なのか、またTOPSという単位で表記する以外に、パフォーマンスをどのように比較するのが良いのでしょうか。
サクヤ
はい、その通りですね。TOPSを一般的に比較した場合、FPGAや他の演算プロセッサの全体的な性能を完全に表したものではありません。
例えば、20TOPSのFPGAにおいて2つのデバイスを想定した場合、当社のDNA IP対応20TOPSのBittWare FPGAと、20TOPSのGPUを比較します。
基本的に、GPU は、利用可能な計算総量に対して、あまり良い使い方をしません。 このことを「利用率」といいます。
最近のGPUは、CPUであっても、利用可能なコンピュータ全体の最大で20%から30%程度を使用しています。
そのため、20TOPSといっても、ある時点でそのうちの20%が利用されているという点では、利用率が高いとは言えません。
そして、当社のランタイムで再構成可能なDNA IPを搭載したFPGAと比較すると、この場合、20TOPSの90%が任意のAIワークロードやアプリケーションに利用されていることになり、ほぼ90%のコンピュータの利用が可能になります。
その結果、GPUやFPGAのソリューションと比較して効率、つまり1ワットあたりの秒間フレーム数が大幅に向上します。
マーカス
 なるほど、TOPSについての説明をありがとうございました。
次に「MERA」というソフトウェアについてお伺いしたいと思います。
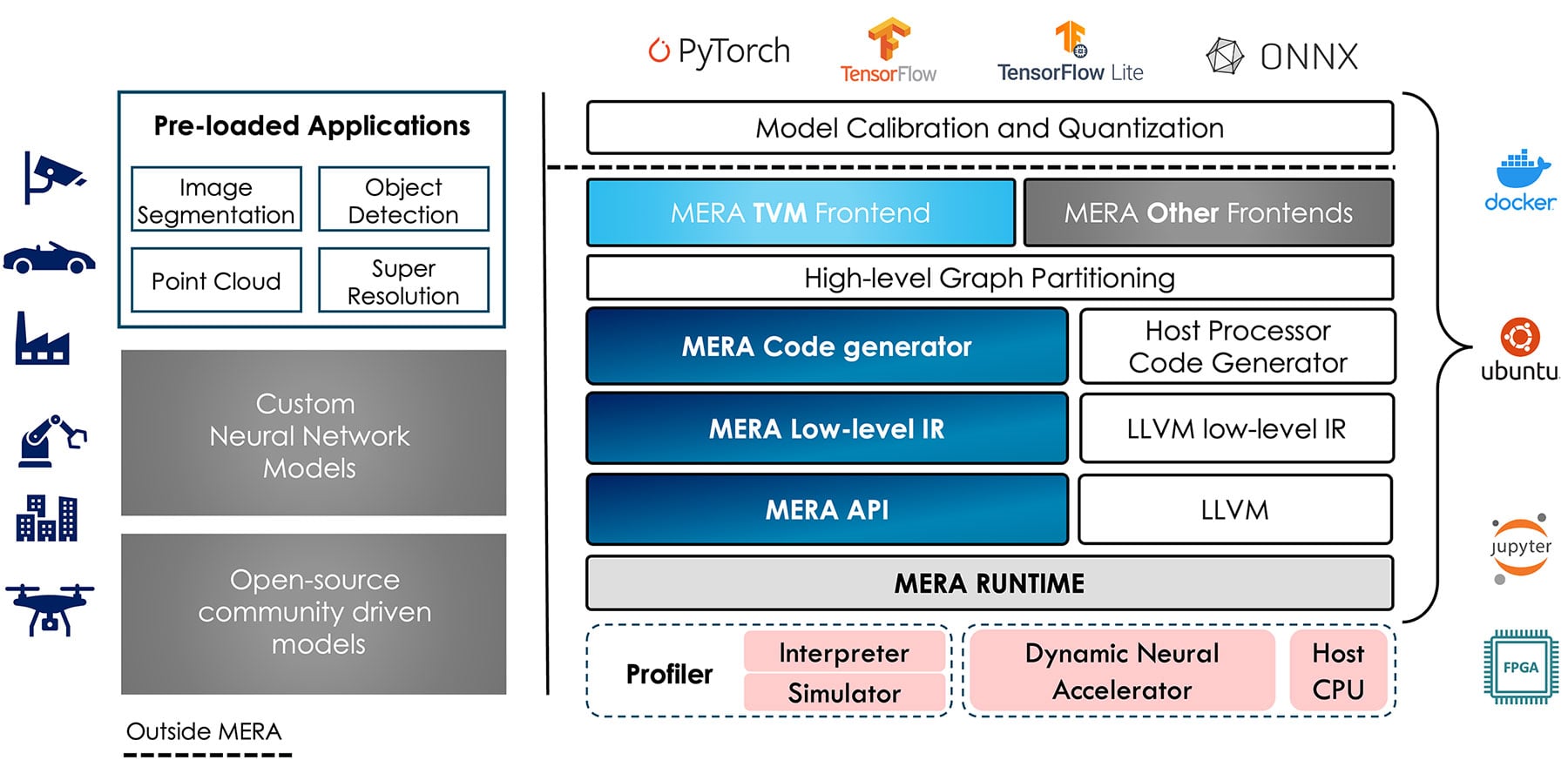
FPGA上で動作するIPはDNAと呼ばれるもので、非常に高い効率性を実現しますが、MERAソフトウェア自体は、例えば、標準的なフレームワークを使用したり、GPUから再トレーニングを必要としないなど、時間の短縮に大きなメリットがあります。
MERAにおけるソフトウェアの利点について、詳しく教えてください。
なるほど、TOPSについての説明をありがとうございました。
次に「MERA」というソフトウェアについてお伺いしたいと思います。
FPGA上で動作するIPはDNAと呼ばれるもので、非常に高い効率性を実現しますが、MERAソフトウェア自体は、例えば、標準的なフレームワークを使用したり、GPUから再トレーニングを必要としないなど、時間の短縮に大きなメリットがあります。
MERAにおけるソフトウェアの利点について、詳しく教えてください。
サクヤ
はい、その通りです。 私たちは、機械学習エンジニアの柔軟性を考慮し、FPGA固有のスキルを必要としないMERAフレームワークを設計しました。 FPGA固有のスキルを身につけることは、AIアクセラレーションでFPGAを使用する際の問題点でした。
つまり、MERAの根本的な利点の1つは、プラグアンドプレイに近い環境が整っているということです。
第一に、例えばGPUで学習済みの既存のディープニューラルネットワークアプリケーションを、再トレーニングやアーキテクチャの変更をすることなく、DNA IPを搭載したこのFPGAにシームレスに移植することが可能です。
第二に、MERAはPyPiの公開リポジトリを使用してインストールすることができます。 つまり、pipにアクセスできる人なら誰でも、FPGAが動作しているそのデバイスで直接MERAをダウンロードすることができます。 そして、PythonやC++をビルトインでサポートし、Pytorch、TensorFlow、TensorFlow Lite等の主要な機械学習フレームワークをすべてネイティブでサポートすることになります。
第三に、オープンソースのApache TVMのサポートも組み込まれていることです。 Apache TVMは、非常に人気のあるディープラーニングコンパイラです。これにより、ユーザーは、機械学習のフレームワーク内で、簡単なキャリブレーションと量子化のステップを経た後、事前学習済みディープニューラルネットワークモデルをデプロイすることができます。
基本的には、IP固有のモデル、量子化、プルーニングの必要はありません。
これは、競合するソリューションやFPGAやアプリケーション固有のハードウェアを使用した他のインフラストラクチャと比較すると、非常に大きな利点です。
このような処理には、多くの場合、ハードウェア固有の一定レベルの微調整が必要です。 この点を完全に排除することで、機械学習エンジニアはより自主的に、既に知識のあるGPUの動作に必要なコードをシームレスに転送することができます。
第四に、ディープニューラルネットワークの演算子を多様にサポートしていることです。 そのため、最新のDNNやディープニューラルネットワークのほとんどは、箱から出してすぐにデプロイすることができます。 また、ユーザーが使えるように、様々なアプリケーションにまたがるテスト済みの50以上のモデルを提供しています。
最後に、内蔵のシミュレータ・インタプリタ等、プロファイリングツールと呼ばれるものがあり、ユーザーは実際にFPGAにソリューションをデプロイしなくても、迅速に性能テストをすることが可能です。これにより、ユーザーはモデルの精度確認と性能の推定を比較的短時間で行うことができます。
以上が、フレームワークとしてのMERAの利点です。
マーカス
さて、これでハードウェアとソフトウェアの話は一通り終わりました。 それでは、いくつかのユースケースを紹介しましょう。 私が興味深いと感じたものも含めてお話したいをお伺いしたいと思います。 一つ目は、超解像です。 EdgeCortixのフレームワークは、一体何なのか、またどのようなパフォーマンスを発揮するのでしょうか。
サクヤ
超解像といえば、画像や映像の解像度を大幅に上げたり、時には下げたりする技術です。
例えば、360pという非常に小さなピクセル密度の解像度から、4Kのような非常に高い解像度になるということですね。 この場合、解像度は大幅に上がり、逆に4Kから360pに解像度を下げることも同じことが言えます。
解像度間を移動する能力が必要なアプリケーションや、帯域幅を確保したいアプリケーション。 例えば、ビデオで特定のストリーミング・アプリケーションを実行する場合、解像度を下げてデータを送信し、ユーザー側で解像度を再取得することで帯域幅を維持することができます。
従来、超解像を行うには、不可逆な古い方法を用いていました。 その結果、画像の情報量の多くが失われ、非常に小さな解像度から高解像度へ移行する際にピクシレーションが発生してしまいました。
しかし、これらの画像や映像で学習済みのニューラルネットワークを用いて情報量を外挿することで、情報の大部分を可逆式で保存することができます。
その結果、機械学習を使わない従来の方法で見られるようなピクシレーションを起こさずに、 多くの情報を保存することができるようになりました。
EdgeCortixのフレームワークの場合、こうした比較的複雑な超解像モデルをFPGA上で直接、非常に高い解像度で実行することが可能です。
結果として、360pや480pの小さな解像度から、数ミリ秒で4Kに直接移行でき、 ビデオストリーミング用途で大容量のデータを伝送することが可能になりました。
マーカス
素晴らしいですね。AIの新しい用途に適応している好例だと思います。 もう一つのユースケースは、画像ベースではないセンサーデータの利用ですね。 これは、実際に無線周波数データをフィンガープリントし、 AIを使って位置やデバイスの特定などを予測するものです。 この仕組みについて詳しく教えてください。
サクヤ
良い質問ですね。 一般的に、データがどこで生成され、どこから情報が送信されているかを特定する必要があるアプリケーションは、防衛通信だけでなく、消費者向けアプリケーションにも複数見られます。 それには、通常、無線周波数というものを使います。 そして、人間に指紋があるように、現在は、電波をとらえて、データが生成される場所から本質的にユニークなフィンガープリントを作れるようになりました。 その場所はルーターかもしれないし、電波塔かもしれないし、携帯電話ということもあります。 その結果、これらのデータをすべて画像に変換し、ディープニューラルネットワーク(この場合は畳み込みニューラルネットワーク)を学習させることで、独自の特徴を識別し、そのデバイスが実際のデバイスかどうかを分類することができるようになりました。 例えば、既知のデバイスであれば、その情報がどこから発信されているのかを分類・特定することも可能です。
FPGAでニューラル・ネットワークを処理できるようになると、インフラ・エッジや防衛、通信など、信号の発生場所を特定・識別・認証する必要があるさまざまなアプリケーションに対応できるようになり、活用できる分野が広がります。
そういうわけで、この分野は成長分野であり、防衛と消費者の両分野にまたがる多くのアプリケーションで目にすることができます。
マーカス
こうした新たなユースケースが出てきたことは喜ばしいですね。 では、最後にエッジAIの次の展開を教えてください。 ハードウェアやユースケースの変化や出現に伴い、協調探索を繰り返し続けることになるのでしょうか? エッジにおける柔軟性と効率性のトレードオフのバランスをどのようにとりますか?
サクヤ
ええ、とてもいい質問ですね。 もちろん、この分野は完全に開かれていると考えています。 ニューラルネットワークを協調設計し、その上で動作するハードウェアプラットフォームを設計するという点においては、まだ始まったばかりです。 最初の質問に戻りますが、特にFPGAは、プロセッサ・アーキテクチャの特定の側面を微調整するのに適切な柔軟性を実現するものです。
同時に、新しいタイプのモデルが次々と生み出されています。 以前は、畳み込みニューラルネットワークは、動画や画像に対して非常に人気がありました。 現在では、そのような畳み込みモデルとは少し異なる変形型のモデルも存在します。 その結果、ある特定の時点でより良く機能するということが分かっている異なる世代のニューラルネットワークと、実行するハードウェアをより緊密に統合し、適合させたいと思うようになるでしょう。
ワンサイズであらゆる種類のシナリオに対応する必要はありません。 ニューラルネットワークの特徴や並列度に対して、実行する基板の柔軟性を高めたいのです。
全体として、柔軟性と効率性のトレードオフは、非常に長い間、存在し続けるということはお分かりでしょう。 特にエッジについて考えると、リソースや電力には常に限られており、多くの場合、モビリティにも制約があるため、パフォーマンスを上げるために実際に開ける扉は、効率性やリソースの管理です。
結果として、この「協調探索」の領域は、これからさらに広がっていくものだと考えています。
マーカス
さて、今回もたくさんのお話を聞かせていただき、ありがとうございました。
サクヤ
こちらこそありがとうございました。
マーカス
EdgeCortixのCEO兼創業者であるSakya Dasgupta氏との対談をご覧いただきありがとうございました。

