Apache Kafka 是新兴通用流数据管道的核心。作为流媒体平台的首选,Kafka 在 LinkedIn、Netflix、Uber、ING 以及超过三分之一的财富 500 强企业中都得到了广泛应用,而且还在不断增加。在 LinkedIn,每天约有两万亿条信息通过 Kafka 传输。根据TechRepublic.com的数据,十大旅游公司中有六家、十大全球银行中有七家、十大保险公司中有八家、十大电信公司中有九家已采用Kafka作为管理流数据的核心平台。在2017年纽约Kafka峰会上,Confluent公司报告说,超过三分之一的财富500强企业已经部署了Kafka。
Kafka有三个基本组成部分--生产者、经纪人和消费者。生产者将数据发布到经纪商的主题上,消费者则订阅主题。图1显示了一个基本的Kafka系统。
Kafka架构的众多优势之一是生产者和消费者的解耦。生产者和消费者的数据速率可以大相径庭,但对彼此没有影响。Kafka的另一个关键优势是它的体积小。Kafka的代码只有9万多行,与需要完整Spark节点的Spark Streaming相比,Kafka集群可以在更小的硬件要求下实现。
图1 - 基本的Kafka系统
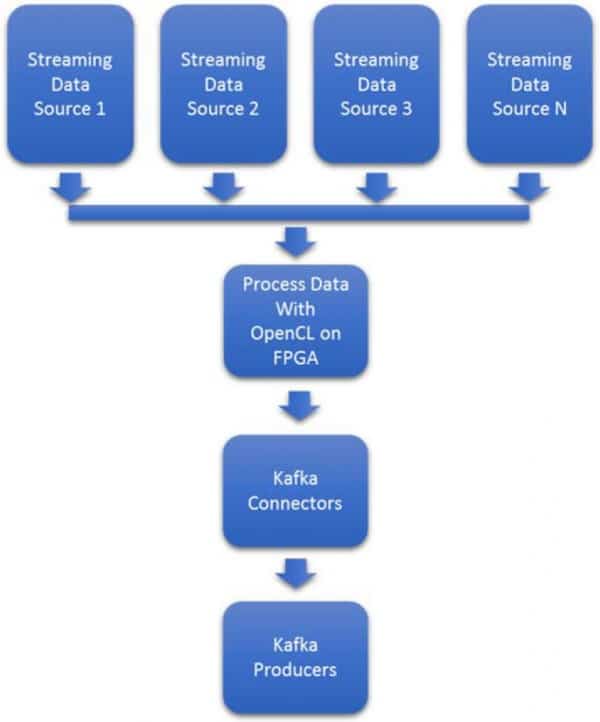
大数据系统中的数据摄取范围从简单到复杂。在图2中,数据源1可能是网络流量的数据包捕获。然而,数据源二可能是来自卫星星座的复杂地理空间图像,而数据源三是德克萨斯州西部风车农场的工业物联网维护数据。
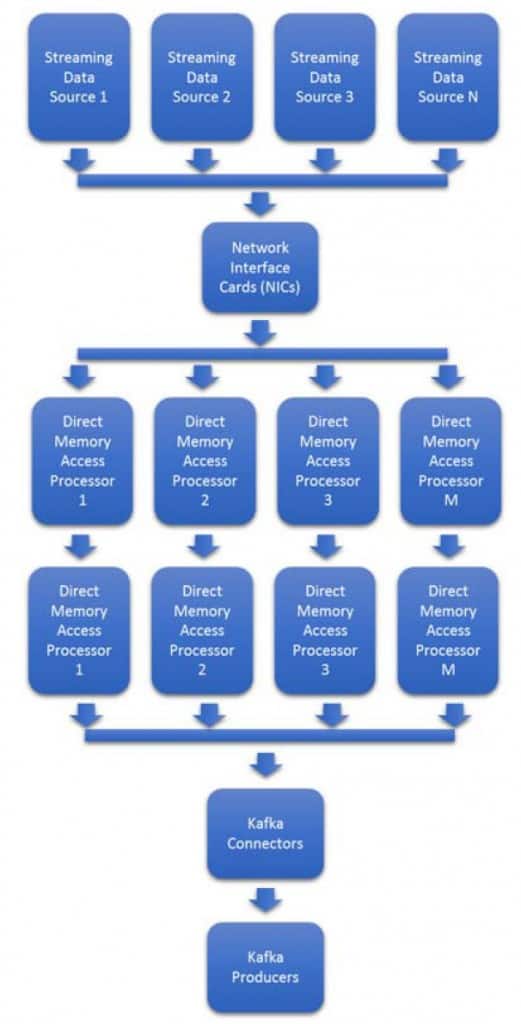
数据格式和数据速率的可变性使问题难以扩展。能够实时适应流量和新格式的突发,往往成本很高,需要配置额外的网卡和处理器。图3显示了大多数Kafka集群中使用的基于处理器的典型架构。
图2:使用英特尔FPGA的流媒体数据采集加速器
数据速率的变化使图3中的系统难以规划。在许多情况下,必须对最大带宽进行估计,然后进行配置。50%或更多的多余处理器和网卡将被闲置,等待数据速率的增加。
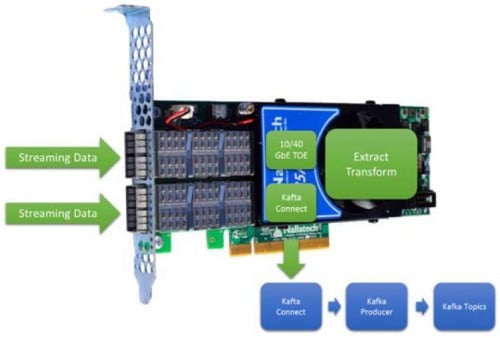
转向基于英特尔FPGA的解决方案,将估计相同的最大带宽,但图4中的简化系统在空闲时的功率要低得多,总体上需要的空间也相当小。图2中的系统还将消除基于处理器的系统所需的流量控制和负载平衡管理,因为无论数据速率或数据格式如何,基于英特尔FPGA的方法都是确定性的。
英特尔FPGA是流式并行加速器,可直接连接到铜线、光纤和光缆上。与传统的GPU和CPU不同,英特尔FPGA可以在几纳秒内将任何格式的数据从电线转移到存储器,而不需要网络接口卡(NIC)。
这种加速摄取的方式可以使数据摄取到Kafka生产者的延迟降低40倍。它提供了对流入的数据同时进行实时处理的选择,如通过实施机器学习、图像识别、模式匹配、过滤、压缩、加密等。因此,输入的数据可以被加速和充实,以加快数据采集和数据分析的时间。
图3:典型的摄取路径
图4显示了FPGA摄取到Kafka生产者的最基本用例。即使是这个最基本的用例,FPGA也能为极不稳定的速率提供低延时和确定性。利用OpenCL提取和转换数据的能力使这个用例可以处理10到100种数据类型。
图4 内联的、低延迟的、确定的、提取和转换
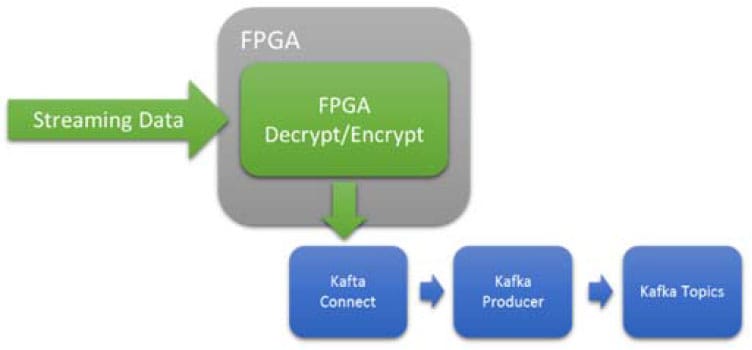
加密在处理器周期中极其昂贵,但在英特尔FPGA上却很好理解。FPGA提供了一个低延迟和确定性的结果,而不依赖于数据速率。对于处理器来说,可变的数据速率可能会淹没处理器资源,导致瓶颈和/或开始丢包。
图5 在线、低延迟、确定的、加密或解密
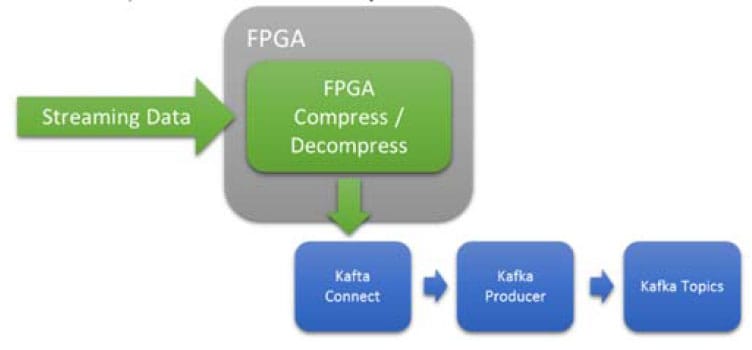
图6 内联、低延迟、确定的压缩或解压缩
FPGA在压缩和解压方面非常高效。在这个用例中,FPGA被用来在数据传递给Kafka系统之前对其进行压缩/解压。
香农定律正被应用于更多的流媒体使用案例,以确定一个流媒体是否被加密。香农定律计算数据包的熵,寻找随机性与结构化的字节。许多加密字节看起来与结构化数据相似,但不是全部。图7显示了一个可能的流程,计算熵,尝试解密,然后在发布到Kafka主题前解压。即使解密和/或解压不能成功完成,对加密与解密的数据流进行排序在行业中也有很多应用,比如金融和医疗等个人身份信息。
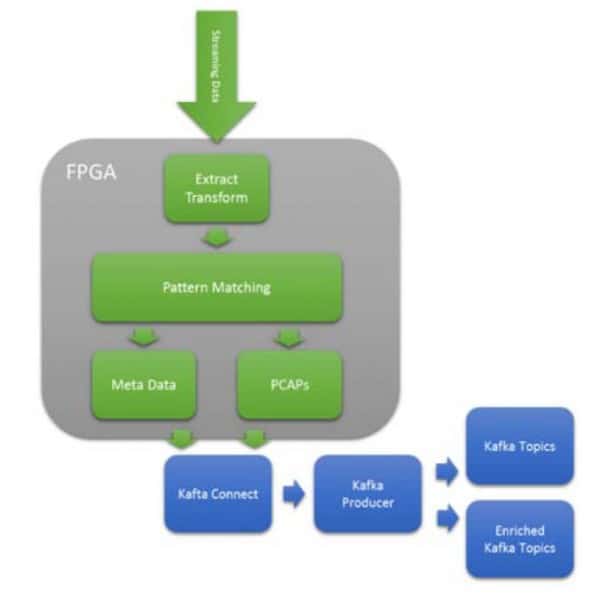
图8 用于网络分析的PCAPs丰富的主题路由
Kafka灵活的主题架构,允许摄入的数据被放置在许多主题中。这种灵活性意味着传入的数据可以通过机器学习和模式匹配来进行路由/切换。以上面的图9为例,它显示了正在捕获的原始网络数据包(PCAPS)。当数据包被捕获时,使用PCRE表达式的复杂模式匹配可以路由到适当的主题。这使得Kafka消费者可以订阅丰富的主题,并绕过一个清洗阶段。对于许多网络分析应用,根据DOE Sandia & Lewis Rhodes实验室发表的研究,该处理实现了每瓦特1000倍的网络操作改进。
BittWare 385A提供两个网络端口,每个端口支持高达40Gbe/sec。这个网卡大小的卡可以取代现有的网卡/CPU组合,大大加速现有的Kafka网络,并降低功率。
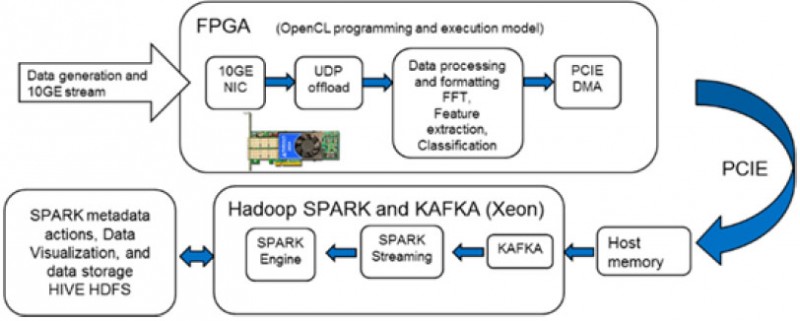
这已经被Cloudera和英特尔验证,以加速Kafka到Spark流,同时在FPGA上执行数据丰富化(图9)。
图9 使用385A的丰富的数据
在上面的演示中,我们选择了发动机噪声特征作为我们的输入数据流。它们通过UDP卸载引擎被摄取和卸载,并被放入卡的OpenCL环境中。卡上运行的OpenCL代码对输入的数据流进行实时格式化。然后,它执行FFT、特征提取,并根据与已知引擎签名的比较,将信号分为 "正常 "或 "异常"。这个额外的数据和引擎信号的FFT一起被DMA到Kafka中进行进一步处理。
这个例子还强调了OpenCL生成的库的灵活性,它可以应用于传入的流媒体数据。这为终端用户提供了巨大的自由度,包括非常具体的数据丰富或数据过滤的应用形式。
BittWare 520N的四个网络端口能够支持一系列的串行I/O协议,运行速度高达10/25/40/100Gz。520N的总吞吐量高达400Gbe/sec,可以在卸载到Kafka框架之前丰富大量数据。
520N配备了强大的Stratix 10 FPGA,提供无与伦比的性能。结合高吞吐量、大量计算和使用OpenCL的可编程性,有可能在单个设备上对流式数据进行复杂的数据丰富化。
图10 使用520N的富集数据
BittWare和英特尔PSG是Kafka加速方面的专家。BittWare拥有当前和计划中的产品,使用Arria 10和Stratix 10 FPGA加速Apache Kafka。请与我们联系,讨论您的需求并开发加速解决方案。
FPGA存储加速概述
了解更多关于我们使用的卡片
返回到资源