Apache Kafka 是新興通用流數據管道的核心。卡夫卡作為流媒體平臺被LinkedIn、Netflix、Uber、ING以及超過三分之一的財富500強企業使用,並且還在不斷增長。在LinkedIn,每天大約有兩萬億條消息通過Kafka。據 TechRepublic.com 稱,全球十大旅遊公司中有六家、全球十大銀行中有七家、十大保險公司中有八家和十大電信公司中有九家已採用Kafka作為管理流數據的中央平臺。在 2017 年紐約 Kafka 峰會上,Confluent 報告稱,超過三分之一的財富 500 強企業已經部署了 Kafka。
卡夫卡有三個基本組成部分——生產者、經紀人和消費者。生產者將數據發佈到代理上的主題,消費者訂閱主題。圖 1 顯示了一個基本的 Kafka 系統。
Kafka 架構的眾多優點之一是生產者和消費者的解耦。生產者和消費者的數據速率可能大不相同,但彼此之間沒有影響。Kafka的另一個關鍵優勢是體積小。Kafka 集群只有 90,000 多行代碼,可以在比需要完整 Spark 節點的 Spark Streaming 更適度的硬體要求上實現。
圖 1 – 基本卡夫卡系統
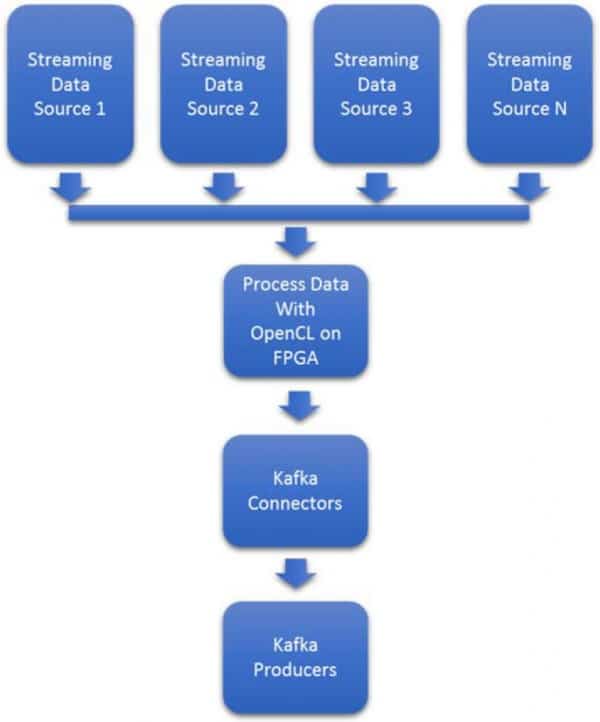
將數據攝取到大數據系統的範圍從簡單到複雜。在圖2中,數據源1可以是網路流量的數據包捕獲。然而,數據源二可能是來自衛星星座的複雜地理空間圖像,而數據源三是西德克薩斯州風車農場的工業物聯網維護數據。
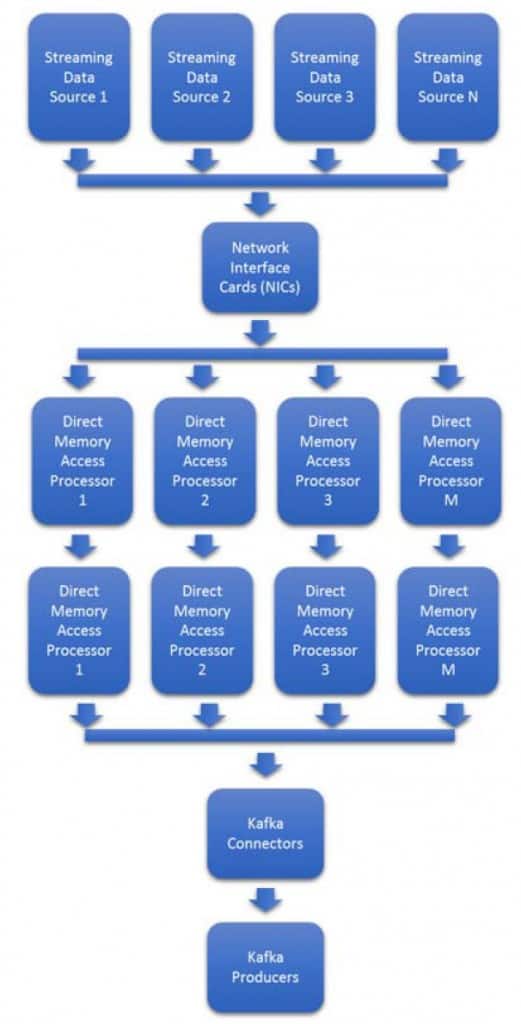
數據格式和數據速率的可變性使問題難以擴展。能夠實時適應流量和新格式的突發通常成本高昂,需要配置額外的 NIC 和處理器。圖 3 顯示了大多數 Kafka 集群中使用的基於處理器的典型架構。
圖 2:使用英特爾 FPGA 進行流數據攝取加速
數據速率可變性使得圖3中的系統難以規劃。在許多情況下,必須估計最大頻寬,然後進行預配。50% 或更多的多餘處理器和 NIC 將處於空閒狀態,等待數據速率的提高。
轉向基於英特爾 FPGA 的解決方案,估計的最大頻寬相同,但圖 4 中的簡化系統在空閒時功耗要低得多,並且總體上需要的佔用空間要小得多。圖 2 中的系統還將消除基於處理器的系統所需的流量控制和負載平衡管理,因為基於英特爾 FPGA 的方法無論數據速率或數據格式如何都是確定性的。
英特爾 ® FPGA 是直接連接到銅線、光纖和光纖的流式並行加速器。與傳統的 GPU 和 CPU 不同,英特爾 ® FPGA 可以在納秒內將任何格式的任何數據從電線移動到記憶體,而無需網路介面卡 (NIC)。
這種攝取加速可以使 Kafka 生產者的數據攝取延遲降低 40 倍。它提供了同時即時處理流入數據的選項,例如通過實施機器學習、圖像識別、模式匹配、過濾、壓縮、加密等。因此,可以加速和豐富攝取的數據,以加快數據採集和數據分析的時間。
圖 3:典型攝取路徑
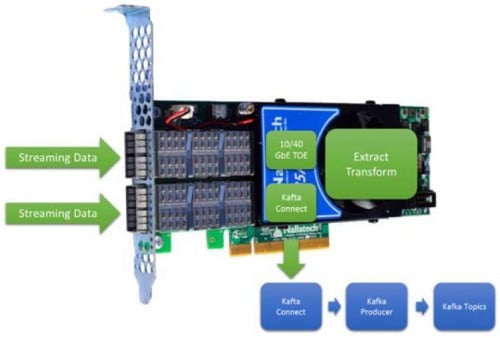
FPGA 攝取到 Kafka 生產者的最基本用例如圖 4 所示。即使對於這個最基本的用例,FPGA也能提供低延遲和確定性,即使是極其可變的速率。使用 OpenCL 提取和轉換數據的能力允許此用例處理 10 到 100 種數據類型。
圖 4 內聯、低延遲、確定性、提取和轉換
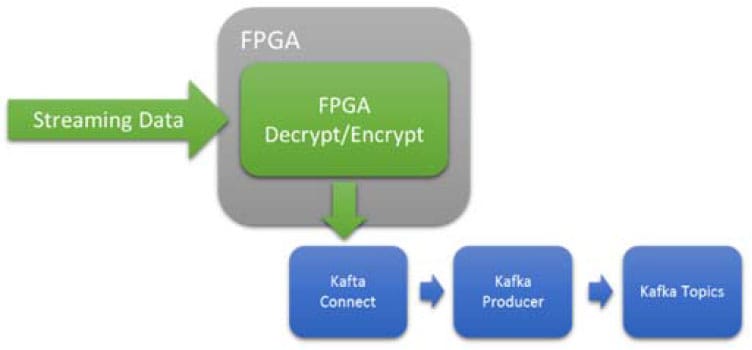
加密在處理器週期中非常昂貴,但在英特爾 FPGA 上卻廣為人知。FPGA 提供低延遲和確定性結果,而不依賴於數據速率。對於處理器,可變數據速率可能會淹沒處理器資源並導致瓶頸和/或開始丟棄數據包。
圖 5 內聯、低延遲、確定性、加密或解密
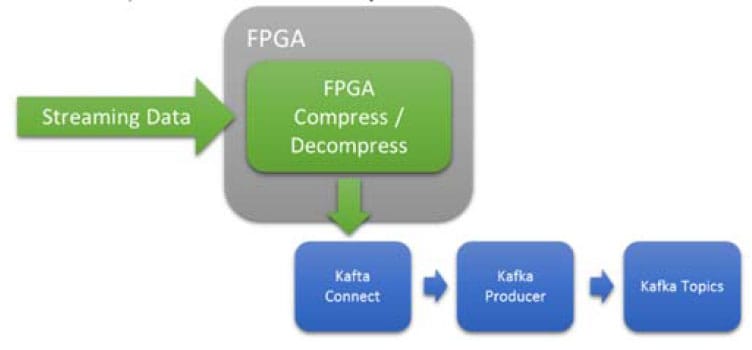
圖 6 內聯、低延遲、確定性壓縮或解壓縮
FPGA 在壓縮和解壓縮方面非常高效。在此用例中,FPGA用於在將數據傳遞到Kafka系統之前對其進行壓縮/解壓縮。
香農定律正在應用於更多的流媒體用例,以確定流是否加密。香農定律計算尋找隨機性與結構化位元組的數據包的熵。許多加密位元組看起來(但不是全部)類似的結構化數據。圖 7 顯示了計算熵、嘗試解密然後解壓縮的可能流程,然後再發佈到 Kafka 主題。即使解密和/或解壓縮無法成功完成,對加密流與解密流進行排序在行業中也有許多應用,例如金融和醫療保健等個人身份資訊。
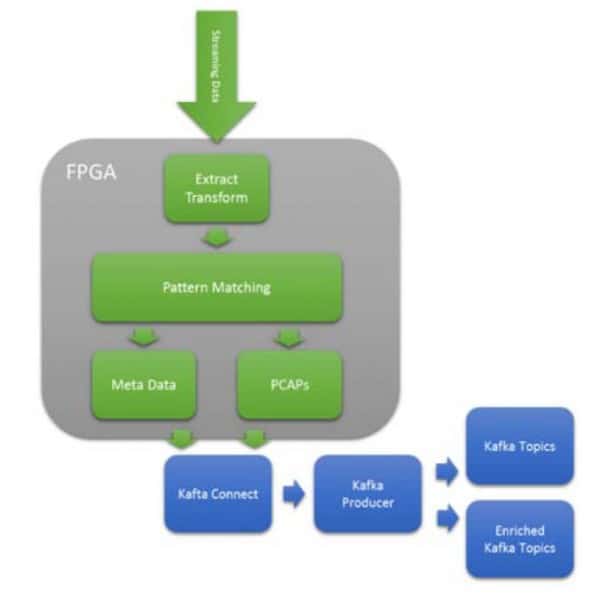
圖 8 用於網路分析的 PCAP 的豐富主題路由
Kafka 靈活的主題架構,允許將攝取的數據放入許多主題中。這種靈活性意味著可以使用機器學習和模式匹配來路由/切換傳入的數據。如圖 9 所示,其中顯示了正在捕獲的原始網路數據包 (PCAPS)。捕獲數據包時,使用PCRE表達式的複雜模式匹配可以路由到相應的主題。這允許 Kafka 消費者訂閱豐富的主題並繞過清理階段。對於許多網路分析應用程式,根據DOE Sandia&Lewis Rhodes Labs發表的研究,該處理實現了每瓦網路操作的1000倍改進。
BittWare 385A提供兩個網路埠,每個埠支持高達40Gbe /秒。這種 NIC 大小的卡可以取代現有的 NIC/CPU 組合,以顯著加速現有的 Kafka 網路並降低功耗。
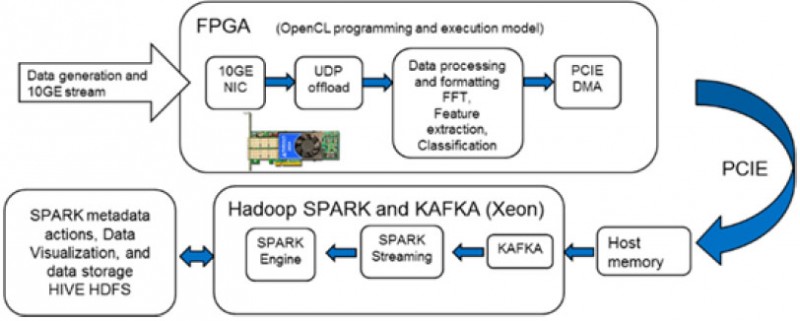
Cloudera 和英特爾已經驗證了這一點,可以加速 Kafka 到 Spark 的流傳輸,同時在 FPGA 上執行數據擴充(圖 9)。
圖9 使用385A擴充數據
在上面的演示中,我們選擇了發動機雜訊特徵作為輸入數據流。它們通過 UDP 卸載引擎進行攝取和卸載,並放入卡的 OpenCL 環境中。卡上運行的 OpenCL 代碼對傳入數據流執行即時格式化。然後,它執行FFT,特徵提取,並根據與已知引擎特徵的比較將信號分類為“正常”或“異常”。這些額外的數據位以及發動機信號的FFT被DMA發送到Kafka進行進一步處理。
此示例還強調了 OpenCL 生成的庫的靈活性,這些庫可應用於傳入的流數據。這為最終使用者提供了巨大的自由度,可以包括非常特定於應用程式的數據擴充或數據過濾形式。
BittWare 520N 四個網路埠支援運行頻率高達 10/25/40/100Gz 的串行 I/O 協定陣列。520N 的總輸送量高達 400 Gbe/秒,可在卸載到 Kafka 框架之前豐富大量數據。
520N 配備了功能強大的 Stratix 10 FPGA,可提供無與倫比的性能。通過使用 OpenCL 將高輸送量、大量計算和可程式設計性相結合,可以在單個設備上對流數據執行複雜的數據豐富。
圖10 使用520N擴充數據
BittWare和Intel PSG是Kafka加速方面的專家。BittWare目前和計劃使用Arria 10和Stratix 10 FPGA加速Apache Kafka的產品。請聯繫我們討論您的需求並開發加速解決方案。
FPGA 存儲加速概述
詳細了解我們使用的卡
Back to Resources