Apache Kafka는 새롭게 떠오르는 범용 스트리밍 데이터 파이프라인의 핵심입니다. Kafka는 포춘 500대 기업 중 3분의 1 이상이 선택한 스트리밍 플랫폼으로 LinkedIn, Netflix, Uber, ING 등 많은 유명 기업에서 채택하고 있으며 그 수는 계속 증가하고 있습니다. LinkedIn에서는 하루에 약 2조 개의 메시지가 카프카를 통과합니다. 테크리퍼블릭닷컴에 따르면 상위 10대 여행사 중 6개, 상위 10대 글로벌 은행 중 7개, 상위 10대 보험사 중 8개, 상위 10대 통신사 중 9개가 스트리밍 데이터 관리를 위한 중심 플랫폼으로 카프카를 채택했습니다. 2017 뉴욕 카프카 서밋에서 Confluent는 포춘 500대 기업 중 1/3 이상이 카프카를 배포했다고 보고했습니다.
기본 카프카 시스템
카프카에는 생산자, 브로커, 소비자라는 세 가지 필수 구성 요소가 있습니다. 생산자는 브로커의 토픽에 데이터를 게시하고 소비자는 토픽을 구독합니다. 그림 1은 기본적인 Kafka 시스템을 보여줍니다.
카프카 아키텍처의 많은 장점 중 하나는 생산자와 소비자를 분리할 수 있다는 점입니다. 생산자와 소비자는 서로 다른 데이터 속도를 사용하면서도 서로에게 영향을 미치지 않을 수 있습니다. 카프카의 또 다른 주요 장점은 작은 크기입니다. 90,000줄이 조금 넘는 코드만으로 전체 Spark 노드가 필요한 Spark 스트리밍보다 훨씬 더 적은 하드웨어 요구 사항에서 Kafka 클러스터를 구현할 수 있습니다.
그림 1 - 기본 카프카 시스템
카프카 프로듀서 가속화
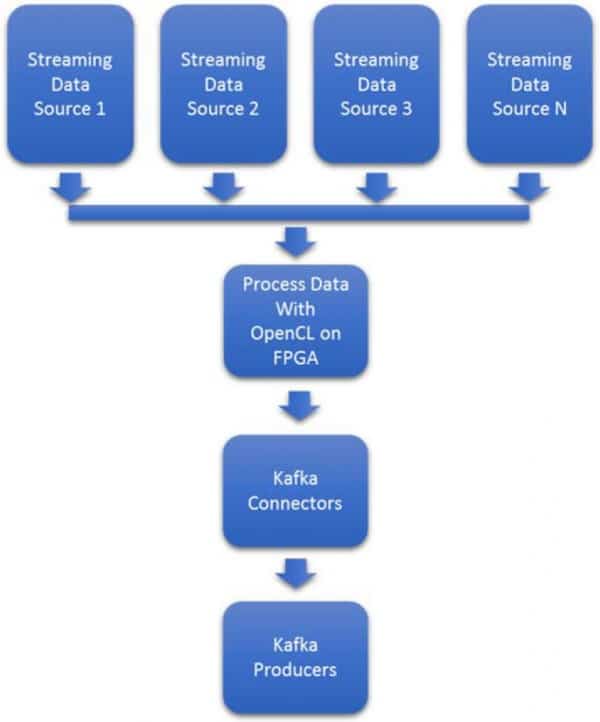
빅데이터 시스템으로 수집되는 데이터는 단순한 것부터 복잡한 것까지 다양합니다. 그림 2에서 데이터 소스 1은 네트워크 트래픽의 패킷 캡처일 수 있습니다. 그러나 데이터 소스 2는 여러 위성의 복잡한 지리 공간 이미지일 수 있고, 데이터 소스 3은 서부 텍사스에 있는 풍차 농장의 산업용 IoT 유지 관리 데이터일 수 있습니다.
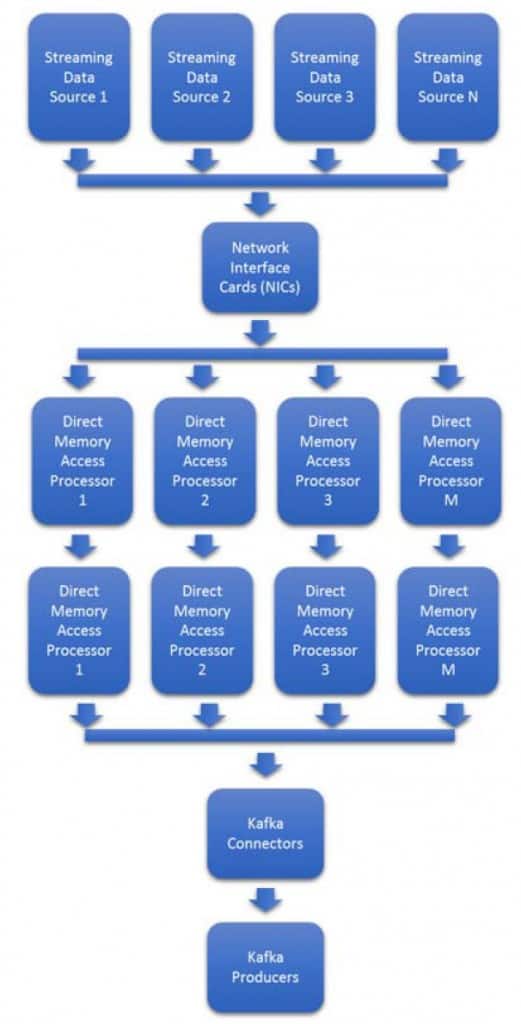
데이터 형식과 데이터 속도의 가변성으로 인해 확장하기가 어렵습니다. 트래픽 폭증과 새로운 형식에 실시간으로 적응하려면 추가 NIC와 프로세서를 프로비저닝해야 하는 등 비용이 많이 드는 경우가 많습니다. 그림 3은 대부분의 Kafka 클러스터에서 사용되는 일반적인 프로세서 기반 아키텍처를 보여줍니다.
그림 2 : 인텔 FPGA를 사용한 스트리밍 데이터 수집 가속화
데이터 속도 변동성은 그림 3의 시스템을 계획하기 어렵게 만듭니다. 대부분의 경우 최대 대역폭을 예측한 다음 프로비저닝해야 합니다. 50% 이상의 초과 프로세서와 NIC가 데이터 속도 증가를 기다리며 유휴 상태가 됩니다.
인텔 FPGA 기반 솔루션으로 전환하면 최대 대역폭은 동일하지만 그림 4의 단순화된 시스템은 유휴 상태에서 전력이 훨씬 낮고 전체적으로 훨씬 적은 설치 공간을 필요로 합니다. 또한 그림 2의 시스템은 데이터 속도나 데이터 형식에 관계없이 결정론적이기 때문에 프로세서 기반 시스템에 필요한 흐름 제어 및 부하 분산 관리가 필요하지 않습니다.
인텔 FPGA는 구리선, 광섬유 및 광선에 직접 부착되는 스트리밍 병렬 가속기입니다. 기존 GPU 및 CPU와 달리 인텔 FPGA는 네트워크 인터페이스 카드(NIC)가 없어도 모든 형식의 데이터를 나노초 단위로 와이어에서 메모리로 이동할 수 있습니다.
이러한 수집 가속화를 통해 Kafka 프로듀서에 대한 데이터 수집 지연 시간을 40배 단축할 수 있습니다. 머신 러닝, 이미지 인식, 패턴 매칭, 필터링, 압축, 암호화 등을 구현하여 유입되는 데이터를 실시간으로 동시에 처리할 수 있는 옵션도 제공합니다. 따라서 수집된 데이터를 가속화하고 보강하여 데이터 수집 및 데이터 분석 시간을 단축할 수 있습니다.
그림 3 : 일반적인 수집 경로
사용 사례 1: 인라인 추출 및 변환
그림 4는 카프카 프로듀서에 대한 FPGA 수집의 가장 기본적인 사용 사례입니다. 이 가장 기본적인 사용 사례에서도 FPGA는 매우 가변적인 속도에 대해서도 짧은 지연 시간과 결정성을 제공합니다. OpenCL로 데이터를 추출하고 변환하는 기능 덕분에 이 사용 사례에서는 10~100개의 데이터 유형을 처리할 수 있습니다.
그림 4 인라인, 짧은 지연 시간, 결정론적, 추출 및 변환
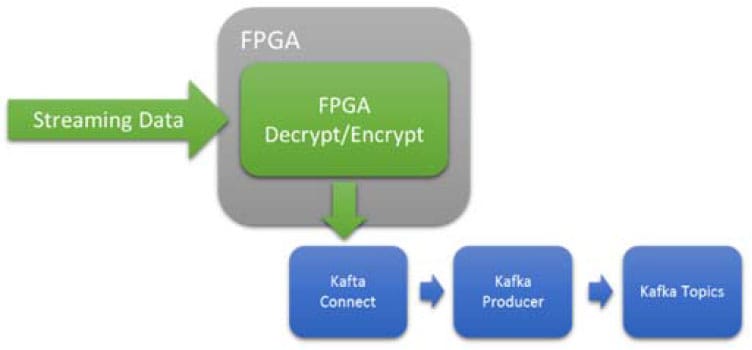
사용 사례 2: 인라인 암호화 및 복호화
암호화는 프로세서 사이클에서 매우 비싸지만, 인텔 FPGA에서는 잘 이해됩니다. FPGA는 데이터 전송률에 의존하지 않고 지연 시간이 짧고 결정적인 결과를 제공합니다. 프로세서의 경우 가변 데이터 전송률은 프로세서 리소스에 과부하를 일으켜 병목 현상을 일으키거나 패킷을 떨어뜨리기 시작할 수 있습니다.
그림 5 인라인, 짧은 지연 시간, 결정론적, 암호화 또는 복호화
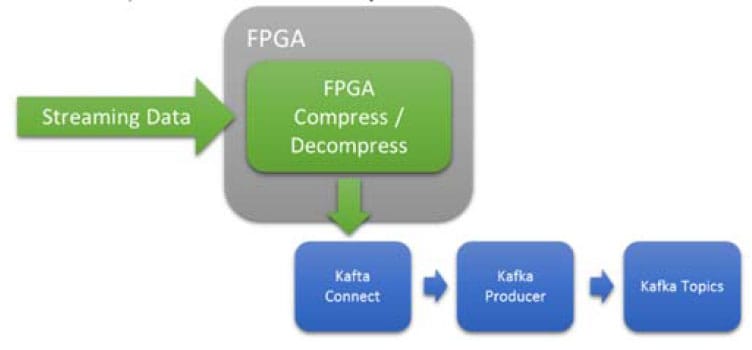
그림 6 인라인, 짧은 지연 시간, 결정론적 압축 또는 압축 해제
사용 사례 3: 인라인 압축 및 압축 해제
FPGA는 압축과 압축 해제에 매우 효율적입니다. 이 사용 사례에서 FPGA는 데이터를 압축/압축 해제하여 Kafka 시스템으로 전달하기 전에 데이터를 압축/압축 해제하는 데 사용됩니다.
사용 사례 4: 암호화/복호화 및 압축/해제 스트림을 사용한 정보 이론
섀넌의 법칙은 더 많은 스트리밍 사용 사례에 적용되어 스트림이 암호화되었는지 여부를 판단하고 있습니다. 섀넌의 법칙은 무작위성을 찾는 패킷의 엔트로피와 구조화된 바이트의 엔트로피를 계산합니다. 많은 암호화된 바이트가 유사한 구조화된 데이터처럼 보이지만, 전부는 아닙니다. 그림 7은 엔트로피를 계산하고 암호 해독을 시도한 다음 압축을 풀고 Kafka 토픽에 게시하기 전에 가능한 흐름을 보여줍니다. 복호화 및/또는 압축 해제가 성공적으로 이루어지지 않더라도 암호화된 스트림과 암호화된 스트림을 분류하는 것은 금융 및 의료와 같은 개인 식별 정보와 같은 산업에서 많은 응용 분야를 가지고 있습니다.
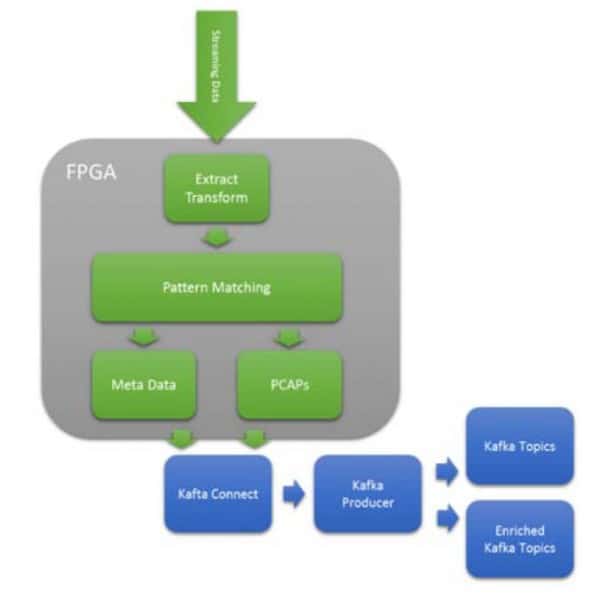
그림 8 사이버 분석을 위한 PCAP의 강화된 토픽 라우팅
사용 사례 5: 강화된 토픽 라우팅
수집된 데이터를 여러 토픽에 배치할 수 있는 Kafka의 유연한 토픽 아키텍처. 이러한 유연성은 머신 러닝과 패턴 매칭을 사용해 수신 데이터를 라우팅/전환할 수 있음을 의미합니다. 위의 그림 9는 캡처되는 원시 네트워크 패킷(PCAPS)을 보여줍니다. 패킷이 캡처되면 PCRE 표현식을 사용한 복잡한 패턴 매칭을 통해 적절한 토픽으로 라우팅할 수 있습니다. 이를 통해 Kafka 소비자는 강화된 토픽을 구독하고 정리 단계를 우회할 수 있습니다. 많은 사이버 분석 애플리케이션에서 이 프로세싱은 DOE Sandia & Lewis Rhodes 연구소에서 발표한 연구에 따르면 와트당 사이버 작업에서 1000배의 개선을 실현합니다.
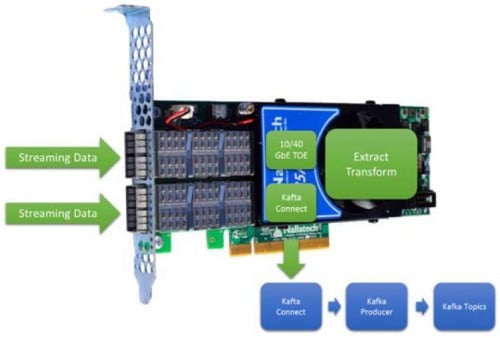
BittWare 385A 클라우데라/인텔 예제
BittWare 385A는 각각 최대 초당 40Gbe를 지원하는 두 개의 네트워크 포트를 제공합니다. 이 NIC 크기의 카드는 기존 NIC/CPU 조합을 대체하여 기존 카프카 네트워크를 크게 가속화하고 전력을 절감할 수 있습니다.
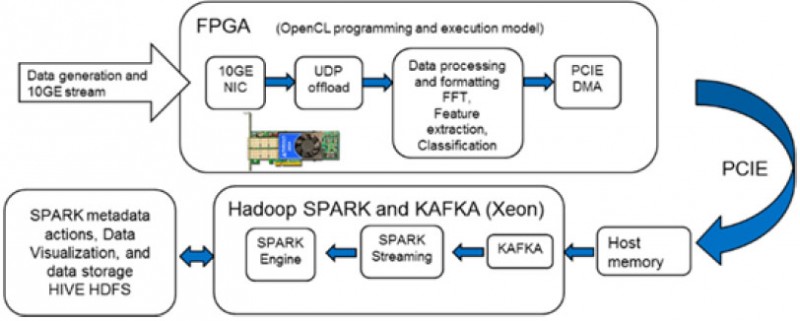
이는 클라우데라와 인텔이 FPGA에서 데이터 보강을 수행하면서 Kafka를 Spark 스트리밍으로 가속화하는 것으로 검증되었습니다(그림 9).
그림 9 385A를 사용한 강화된 데이터
위의 데모에서는 엔진 노이즈 시그니처를 입력 데이터 스트림으로 선택했습니다. 엔진 노이즈 시그니처는 UDP 오프로드 엔진을 통해 수집 및 오프로드되어 카드의 OpenCL 환경에 배치됩니다. 카드에서 실행되는 OpenCL 코드는 들어오는 데이터 스트림에 대해 실시간 포맷을 수행합니다. 그런 다음 FFT, 특징 추출을 수행하고 알려진 엔진 시그니처와의 비교를 기반으로 신호를 "정상" 또는 "비정상"으로 분류합니다. 엔진 신호의 FFT와 함께 이 추가 데이터 비트는 추가 처리를 위해 Kafka로 DMA됩니다.
이 예는 또한 수신 스트리밍 데이터에 적용할 수 있는 OpenCL 생성 라이브러리의 유연성을 강조합니다. 이를 통해 최종 사용자는 매우 구체적인 형태의 데이터 강화 또는 데이터 필터링을 포함할 수 있는 엄청난 자유도를 누릴 수 있습니다.
520N: Stratix10 사용 시 100Gbe
BittWare 520N은 4개의 네트워크 포트를 통해 최대 10/25/40/100Gz에서 작동하는 다양한 직렬 I/O 프로토콜을 지원합니다. 총 처리량이 초당 최대 400Gbe에 달하는 520N은 Kafka 프레임워크로 오프로드하기 전에 대량의 데이터를 보강할 수 있는 케이블입니다.
520N은 강력한 Stratix 10 FPGA를 탑재하여 탁월한 성능을 제공합니다. 높은 처리량, 대용량 컴퓨팅, OpenCL을 사용한 프로그래밍 기능의 조합으로 단일 디바이스에서 스트리밍 데이터에 대한 복잡한 데이터 보강 작업을 수행할 수 있습니다.
그림 10 520N을 사용한 강화된 데이터
자세한 정보 및 평가 방법
비트웨어는 인텔 PSG와 함께 카프카 가속 분야의 전문가입니다. BittWare는 Arria 10 및 Stratix 10 FPGA를 사용하여 Apache Kafka를 가속화하는 현재 및 계획 중인 제품을 보유하고 있습니다. 귀사의 요구 사항을 논의하고 가속 솔루션을 개발하려면 당사에 문의하시기 바랍니다.