
백서
컨볼루션 신경망의 FPGA 가속화
개요
컨볼루션 신경망(CNN)은 복잡한 이미지 인식 문제에 매우 효과적인 것으로 나타났습니다. 이 백서에서는 인텔 OpenCL 소프트웨어 개발 키트를 사용하여 프로그래밍된 BittWare의 FPGA 가속기 제품을 사용하여 이러한 네트워크를 가속화하는 방법에 대해 설명합니다. 그런 다음 계산 정밀도를 낮춰 이미지 분류 성능을 크게 향상시킬 수 있는 방법을 설명합니다. 정밀도가 감소할 때마다 FPGA 가속기는 초당 처리할 수 있는 이미지 수가 점점 더 많아집니다.
카페 통합
Caffe는 표현력, 속도, 모듈성을 염두에 두고 만들어진 딥 러닝 프레임워크입니다. 버클리 비전 및 학습 센터와 커뮤니티 기여자들에 의해 개발되었습니다.
Caffe 프레임워크는 XML 인터페이스를 사용해 특정 CNN에 필요한 다양한 처리 계층을 설명합니다. 사용자는 다양한 레이어 조합을 구현함으로써 주어진 요구 사항에 맞는 새로운 네트워크 토폴로지를 신속하게 생성할 수 있습니다.
이러한 레이어 중 가장 일반적으로 사용되는 레이어는 다음과 같습니다:
- 컨볼루션: 컨볼루션 레이어는 입력 이미지를 일련의 학습 가능한 필터로 컨볼루션하여 각각 출력 이미지에 하나의 특징 맵을 생성합니다.
- 풀링: 최대 풀링은 입력 이미지를 겹치지 않는 직사각형 집합으로 분할하고 각 하위 영역에 대해 최대값을 출력합니다.
- Rectified-Linear: Given an input value x, The ReLU layer computes the output as x if x > 0 and negative_slope * x if x <= 0.
- 내부 제품/완전히 연결됨: 이미지가 각 점이 새 출력 벡터의 각 점에 기여하는 단일 벡터로 처리됩니다.
이 4개의 레이어를 FPGA로 포팅하면 대부분의 포워드 프로세싱 네트워크를 Caffe 프레임워크를 사용하여 FPGA에서 구현할 수 있습니다.
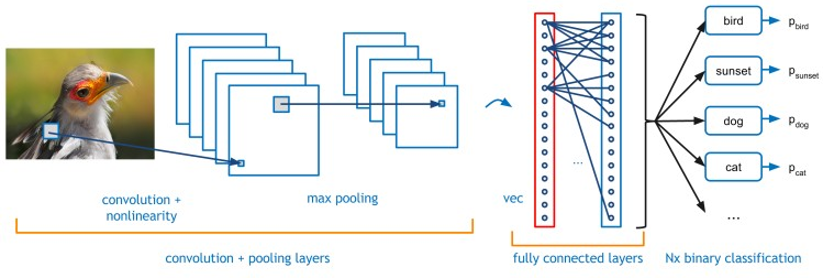
그림 1 : 일반적인 CNN - 컨볼루션 신경망의 예시 그림
AlexNet
AlexNet은 잘 알려져 있고 잘 사용되는 네트워크로, 무료로 제공되는 훈련된 데이터 세트와 벤치마크가 있습니다. 이 백서에서는 AlexNet CNN을 대상으로 한 FPGA 구현에 대해 설명하지만, 여기에 사용된 접근 방식은 다른 네트워크에도 동일하게 적용될 수 있습니다.
그림 2는 AlexNet CNN에 필요한 다양한 네트워크 계층을 보여줍니다. 5개의 컨볼루션과 3개의 완전히 연결된 레이어가 있습니다. 이 레이어는 이 네트워크의 처리 시간 중 99% 이상을 차지합니다. 서로 다른 컨볼루션 레이어에는 11×11, 5×5, 3×3의 3가지 필터 크기가 있습니다. 서로 다른 컨볼루션 레이어에 최적화된 다른 레이어를 생성하는 것은 비효율적입니다. 적용되는 필터의 수와 입력 이미지의 크기에 따라 각 레이어의 계산 시간이 달라지고 처리되는 입력 및 출력 특징의 수에 따라 계산 시간이 달라지기 때문입니다. 그러나 각 컨볼루션은 처리하는 레이어 수와 픽셀 수가 다릅니다. 연산 집약적인 레이어에 적용되는 리소스를 늘리면 각 레이어가 동일한 시간 내에 완료되도록 균형을 맞출 수 있습니다. 따라서 한 번에 여러 이미지를 처리할 수 있는 파이프라인 프로세스를 생성하여 사용되는 로직의 효율성을 극대화할 수 있습니다. 즉, 대부분의 처리 요소는 대부분의 시간 동안 바쁩니다.
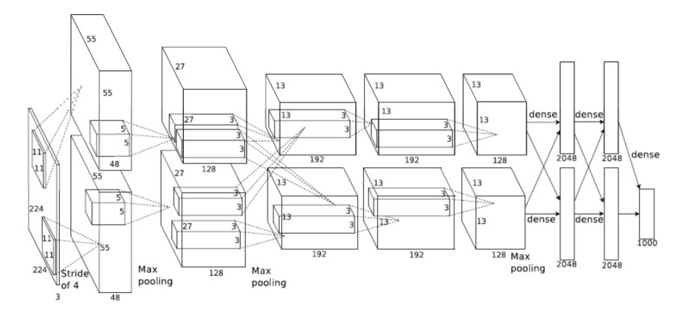
그림 2 : AlexNet CNN - 컨볼루션 신경망
표 1은 이미지넷 네트워크의 각 레이어에 필요한 계산을 보여줍니다. 이 표를 보면 5×5 컨볼루션 레이어가 다른 레이어보다 더 많은 연산이 필요하다는 것을 알 수 있습니다. 따라서 이 레이어가 다른 레이어와 균형을 맞추려면 FPGA에 더 많은 처리 로직이 필요합니다.
<p”>The inner product layers have a n to n mapping requiring a unique coefficient for each multiply add. Inner product layers usually require significantly less compute than convolutional layers and therefore require less parallelization of logic. In this scenario it makes sense to move the Inner Product layers onto the host CPU, leaving the FPGA to focus on convolutions.
FPGA 로직 영역
FPGA 디바이스에는 DSP와 ALU 로직이라는 두 개의 처리 영역이 있습니다. DSP 로직은 곱하기 또는 곱하기 더하기 연산자를 위한 전용 로직입니다. 부동 소수점 큰(18×18비트) 곱셈에 ALU 로직을 사용하는 것은 비용이 많이 들기 때문입니다. DSP 연산에서 곱셈의 공통성을 감안하여 FPGA 공급업체는 이를 위한 전용 로직을 제공했습니다. 인텔은 한 걸음 더 나아가 부동 포인터 연산을 수행하도록 DSP 로직을 재구성할 수 있도록 했습니다. CNN 처리를 위한 성능을 높이려면 FPGA에서 구현되는 곱셈의 수를 늘려야 합니다. 한 가지 방법은 비트 정확도를 낮추는 것입니다.
빈 제목
| 이미지넷 레이어 | 곱하기 더하기(M) |
| 컨볼루션(11×11) | 130 |
| 컨볼루션(5×5) | 322 |
| 컨볼루션(3×3) 1 | 149 |
| 컨볼루션(3×3) 2 | 112 |
| 컨볼루션(3×3) 3 | 75 |
| 내부 제품 0 | 37 |
| 내부 제품 1 | 17 |
| 내부 제품 2 | 4 |
표 1 : ImageNet 레이어 계산 요구 사항
비트 정확도
대부분의 CNN 구현은 다양한 레이어 계산에 부동 소수점 정밀도를 사용합니다. 부동 소수점 IP는 칩 아키텍처의 고정된 부분이기 때문에 CPU 또는 GPGPU 구현의 경우 이는 문제가 되지 않습니다. FPGA의 경우 논리 요소가 고정되어 있지 않습니다. 인텔의 Arria 10 및 Stratix 10 디바이스에는 고정 소수점 곱셈으로도 사용할 수 있는 부동 소수점 DSP 블록이 내장되어 있습니다. 각 DSP 구성 요소는 실제로 두 개의 분리된 18×19비트 곱셈으로 사용할 수 있습니다. 18비트 고정 로직을 사용하여 컨볼루션을 수행하면 단정밀도 부동 소수점에 비해 사용 가능한 연산자 수가 두 배로 늘어납니다.
레이어 | 크기 | 필터 크기 | 필터 없음 |
CONV x2 | 416×416 | 3×3 & 1×1 | 32,64 |
CONV x3 | 208×208 | 3×3 & 1×1 | 64,128 |
CONV x5 | 104×104 | 3×3 & 1×1 | 64,128 |
CONV x17 | 52×52 | 3×3 & 1×1 | 128,256 |
CONV x17 | 26×26 | 3×3 & 1×1 | 256,512 |
CONV x15 | 13×13 | 3×3 & 1×1 | 512×1024 |
업샘플링 및 라우팅 | 26×26 | 3×3 & 1×1 | 256 |
CONV x7 | 26×26 | 3×3 & 1×1 | 256,512 |
업샘플링 및 라우팅 | 52×52 | 3×3 & 1×1 | 128 |
CONV x7 | 52×52 | 3×3 & 1×1 | 128,256 |
그림 3 : Arria 10 부동 소수점 DSP 구성
정밀도가 낮은 부동 소수점 처리가 필요한 경우 반정도 부동 소수점 처리를 사용할 수 있습니다. 이렇게 하려면 FPGA 패브릭에 추가 로직이 필요하지만, 낮은 비트 정밀도가 여전히 적절하다고 가정하면 가능한 부동 소수점 계산의 수가 두 배로 늘어납니다.
이 백서에서 설명하는 파이프라인 접근 방식의 주요 장점 중 하나는 파이프라인의 여러 단계에서 정확도를 변경할 수 있다는 점입니다. 따라서 리소스가 필요한 곳에만 사용되므로 설계의 효율성이 높아집니다.
CNN의 애플리케이션 허용 오차에 따라 비트 정밀도를 더 낮출 수 있습니다. 곱셈의 비트 폭을 10비트 이하로 줄일 수 있다면(20비트 출력) FPGA ALU 로직만 사용하여 곱셈을 효율적으로 수행할 수 있습니다. 이는 FPGA DSP 로직만 사용할 때보다 가능한 곱셈의 수를 두 배로 늘립니다. 일부 네트워크는 더 낮은 비트 정밀도에도 내성이 있을 수 있습니다. FPGA는 필요한 경우 모든 정밀도를 단일 비트까지 처리할 수 있습니다.
AlexNet에서 사용하는 CNN 레이어의 경우, 10비트 계수 데이터는 단정밀도 부동 소수점 연산에 비해 1% 미만의 오류를 유지하면서 간단한 고정 소수점 구현을 위해 얻을 수 있는 최소한의 감소인 것으로 확인되었습니다.
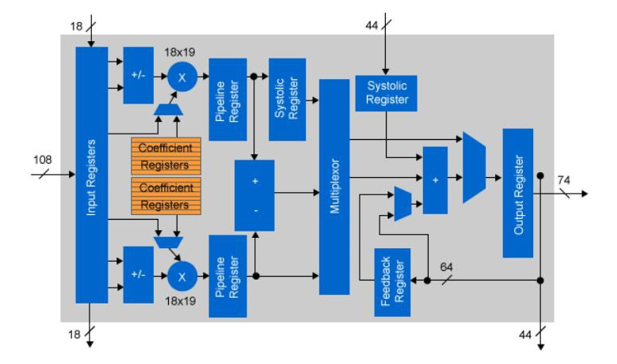
그림 4 : Arria 10 고정점 DSP 구성
CNN 컨볼루션 레이어
슬라이딩 윈도우 기법을 사용하면 메모리 대역폭을 매우 적게 사용하는 컨볼루션 커널을 생성할 수 있습니다.
그림 5는 각 픽셀을 여러 번 재사용할 수 있도록 FPGA 메모리에 데이터를 캐시하는 방법을 보여줍니다. 데이터 재사용량은 컨볼루션 커널의 크기에 비례합니다.
각 입력 레이어가 CNN 컨볼루션 레이어의 모든 출력 레이어에 영향을 미치기 때문에 여러 입력 레이어를 동시에 처리할 수 있습니다. 이렇게 하면 레이어를 로드하는 데 필요한 외부 메모리 대역폭이 증가합니다. 이러한 증가를 완화하기 위해 계수를 제외한 모든 데이터는 FPGA 장치의 로컬 M20K 메모리에 저장됩니다. 디바이스의 온칩 메모리 용량에 따라 구현할 수 있는 CNN 레이어의 수가 제한됩니다.
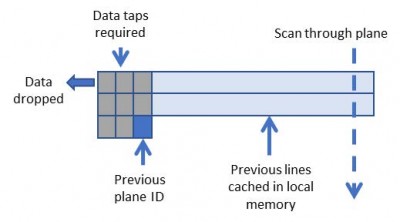
그림 5 : 3×3 컨볼루션을 위한 슬라이딩 창
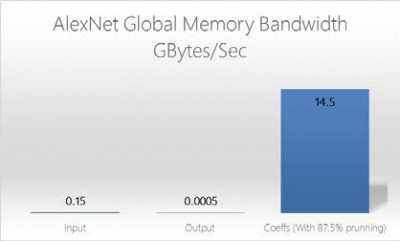
그림 6 : OpenCL 글로벌 메모리 대역폭(AlexNet)
사용 가능한 M20K 리소스의 양에 따라 단일 FPGA에 전체 네트워크를 장착하는 것이 항상 가능한 것은 아닙니다. 이 경우 고속 직렬 인터커넥트를 사용하여 여러 FPGA를 직렬로 연결할 수 있습니다. 이렇게 하면 충분한 리소스를 사용할 수 있을 때까지 네트워크 파이프라인을 확장할 수 있습니다. 이 접근 방식의 주요 장점은 성능을 극대화하기 위해 배치에 의존하지 않으므로 지연 시간이 매우 짧아 지연 시간이 중요한 애플리케이션에 중요하다는 것입니다.
레이어 간에 걸리는 시간을 동일하게 맞추려면 구현된 병렬 입력 레이어의 수와 병렬로 처리되는 픽셀 수를 조정해야 합니다.
리소스 | AlexNet 5×5 컨볼루션 레이어(플로트) | AlexNet 5×5 컨볼루션 레이터(16비트) |
등록하기 | 346,574 | 129,524 |
DSP 블록 | 1,203 | 603 |
RAM 블록 | 1,047 | 349 |
그림 9: Alexnet의 5×5 컨볼루션 레이어에 대한 리소스
대부분의 CNN 기능은 단일 M20K 메모리에 적합하며, FPGA 패브릭에 수천 개의 M20K가 내장되어 있어 병렬로 컨볼루션 기능을 사용할 수 있는 총 메모리 대역폭은 10테라바이트/초 정도입니다.
리소스 | GX1150 | GX2800 |
논리 요소(K) | 1,150 | 2,753 |
ALM | 427,200 | 933,120 |
등록하기 | 1,708,800 | 3,732,480 |
가변 정밀도 DSP 블록 | 181,5 | 5,760 |
18×19 배율기 | 3,036 | 11,520 |
그림 7 : Arria 10 GX1150 / Stratix 10 GX2800 리소스
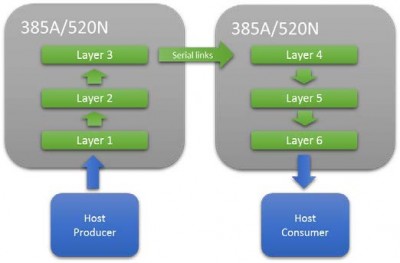
그림 8 : 여러 FPGA를 통한 CNN 네트워크 확장
그림 9는 Intel Arria10 FPGA에서 단정밀도 및 16비트 고정 소수점 버전 모두에 대해 48개의 병렬 커널을 사용하는 Alexnet의 5×5 컨볼루션 레이어에 필요한 리소스를 나열합니다. 이 수치에는 OpenCL 보드 로직이 포함되어 있지만, 낮은 정밀도가 리소스에 미치는 이점을 보여줍니다.
완전히 연결된 레이어
완전히 연결된 레이어를 처리하려면 각 요소에 고유한 계수가 필요하므로 병렬 처리가 증가함에 따라 메모리가 빠르게 제한됩니다. 컨볼루션 레이어와 보조를 맞추는 데 필요한 병렬 처리의 양은 FPGA의 오프 칩 메모리를 빠르게 포화시킬 수 있으므로 입력 레이어의 단계를 일괄 처리하거나 정리할 것을 제안합니다.
내부 제품 레이어의 요소 수가 적기 때문에 일괄 처리에 필요한 스토리지 양이 컨볼루션 레이어에 필요한 스토리지 양에 비해 적습니다. 레이어를 배치하면 배치된 각 레이어에 동일한 계수를 사용할 수 있으므로 외부 메모리 대역폭이 줄어듭니다.
가지 치기는 입력 데이터를 연구하고 임계값 이하의 값을 무시하는 방식으로 작동합니다. 완전히 연결된 레이어는 CNN 네트워크의 후반 단계에 배치되므로 가능한 많은 기능이 이미 제거된 상태입니다. 따라서 가지치기를 통해 필요한 작업량을 크게 줄일 수 있습니다.
리소스
네트워크의 핵심 리소스 드라이버는 각 계층의 출력을 저장하는 데 사용할 수 있는 온칩 M20K 메모리의 양입니다. 이는 일정하며 달성한 병렬 처리의 양과 무관합니다. 여러 FPGA를 통해 네트워크를 확장하면 사용 가능한 총 M20K 메모리 양이 증가하므로 처리할 수 있는 CNN의 깊이도 증가합니다.
빈 제목
결론
FPGA 패브릭의 고유한 유연성 덕분에 로직 정밀도를 특정 네트워크 설계에 필요한 최소값으로 조정할 수 있습니다. CNN 계산의 비트 정밀도를 제한하면 초당 처리할 수 있는 이미지 수를 크게 늘려 성능을 개선하고 전력을 절감할 수 있습니다.
FPGA 구현의 비배칭 방식은 물체 인식에 단일 프레임 지연 시간을 허용하므로 짧은 지연 시간이 중요한 상황에 이상적입니다. 예: 물체 회피.
AlexNet에 이 접근 방식(레이어 1에 단일 정밀도, 나머지 레이어에 16비트 고정 사용)을 사용하면 각 이미지를 단일 Arria 10 FPGA로 약 1.2밀리초, 두 개의 FPGA를 직렬로 사용하면 0.58밀리초 만에 처리할 수 있습니다.