SmartNIC Shell은 사용자가 FPGA 값을 추가하는 시작점으로 BittWare FPGA 보드에서 구현되는 완전한 작동 NIC입니다. SmartNIC Shell을 사용하여 네트워크 기능(NFV), 네트워크 모니터링, 특수 패킷 브로커 또는 패킷을 조작하는 기타 모든 것을 신속하게 배포할 수 있습니다. 셸은 호스트 애플리케이션과 상호 작용하기 위한 DPDK 오프로드를 제공하며, FPGA 프로젝트 소스 및 완전한 기능의 비트스트림으로 제공됩니다.
SmartNIC 셸 정보
SmartNIC Shell에는 무엇이 포함되어 있나요?
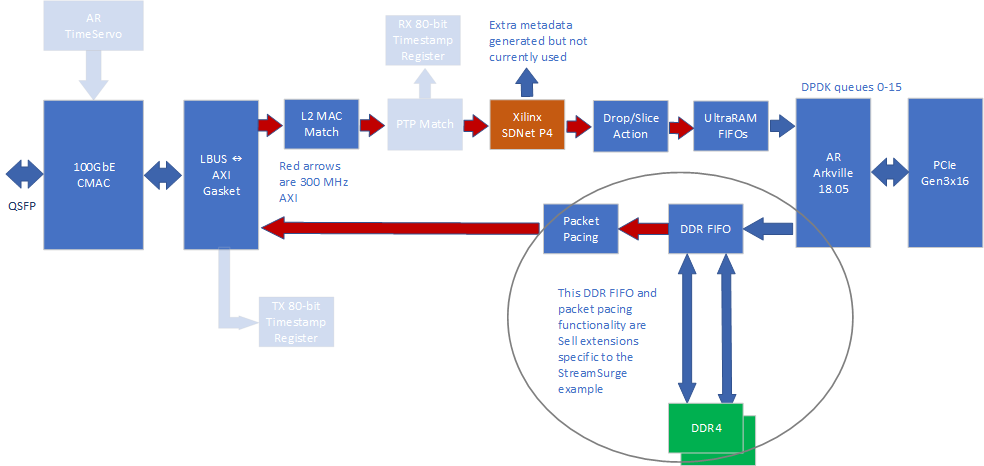
Arkville™ DPDK/AXI 인식 데이터 무버(원자 규칙)
PCIe 하드 IP(자일링스)
AN/LT가 포함된 100G 이더넷 서브시스템(자일링스)
패킷 페이싱(프레임 간 간격) 블록(BittWare)
울트라램 FIFO 블록(BittWare)
드롭/슬라이스 블록(비트웨어)
Lbus-to-AXI 코어(BittWare)
DDR4 FIFO(비트웨어)
L2 매치/액션 필터(BittWare)
HLS 기반 파서(BittWare)
HLS 기반 RSS(BittWare)
지원 제품
SmartNIC Shell은 다음 BittWare 제품을 지원합니다:
XUPP3R: 3/4 길이 PCIe, VU9P FPGA, 속도 등급 2, 4개의 QSFP 중 하나가 활성화되어 있습니다.
라이선스
루프백의 FPGA 비트스트림에는 여러 구성 요소가 포함되어 있습니다. 각 컴포넌트에는 입력과 출력 모두에 AXI4-Stream 인터페이스가 있으며 데이터 플레인으로 집합적으로 사용됩니다. 비트스트림의 컨트롤 플레인은 물리적 PCIe 인터페이스에 연결된 AXI4-Lite 인터페이스를 사용합니다.
디자인 흐름
비트웨어는 아토믹 룰즈에서 아크빌™ DPDK 및 타임서보™ 코어를 라이선스하여 재배포합니다. 비트웨어는 비트웨어의 스마트NIC 셸의 일부로 아크빌 위에 가치를 더합니다.
FPGA 프로젝트를 빌드하려면 "AN/LT가 포함된 자일링스 100G 이더넷 서브시스템"에 대한 라이선스를 사용할 수 있어야 합니다.
FPGA 프로젝트에는 Vivado 2018.3이 필요합니다.
빈 제목
빈 제목
DPDK
SmartNIC 셸이 DPDK를 구현하는 방법
DPDK는 비트웨어 카드의 FPGA에서 구현됩니다. 비트웨어와 아토믹 룰즈의 공동 작업은 FPGA 내부에 DPDK를 구현한 최초의 사례입니다.
비트웨어 보드는 패치된 버전의 원자 규칙 PMD를 사용합니다. 기본 PMD는 DPDK 배포에 포함되어 있습니다. BittWare는 소스 배포의 일부로 필요한 패치를 제공합니다. DPDK를 사용한 BittWare의 모든 테스트는 BittWorks II 드라이버를 대체하는 uio_pci_generic 드라이버를 사용합니다. 그러나 일부 BittWorks II 도구는 여전히 작동합니다.
사용자는 다음을 받게 됩니다:
FPGA 내부에 설치하는 "데이터 무버"로, 한쪽은 AXI 버스에, 다른 한쪽은 PCIe 인터페이스에 연결됩니다. 이 제품은 자일링스 또는 인텔의 암호화된 라이선스 체계를 사용하여 제공됩니다. 여기에는 각 회사의 옵션을 활용하여 시간 제한 평가를 제공하는 것도 포함됩니다.
위의 데이터 무버에 DPDK를 인터페이스하기 위한 오픈 소스 DPDK 폴링 모드 드라이버(PMD)입니다. 이 PMD는 "Arkville"이라는 이름으로 DPDK 17.05부터 공식 DPDK 릴리스의 일부가 되었습니다.
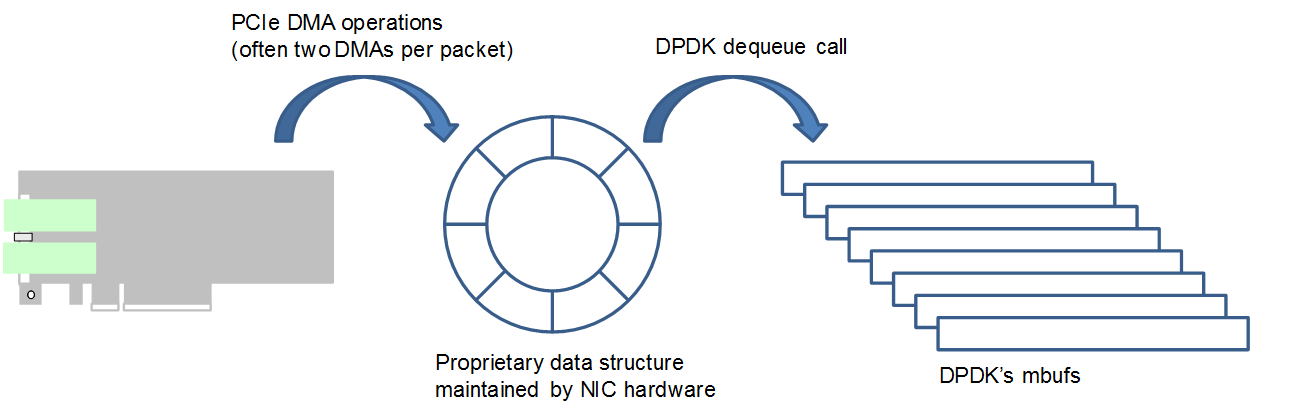
대부분의 ASIC 및 FPGA DPDK 구현은 하나의 복사본을 수행합니다:
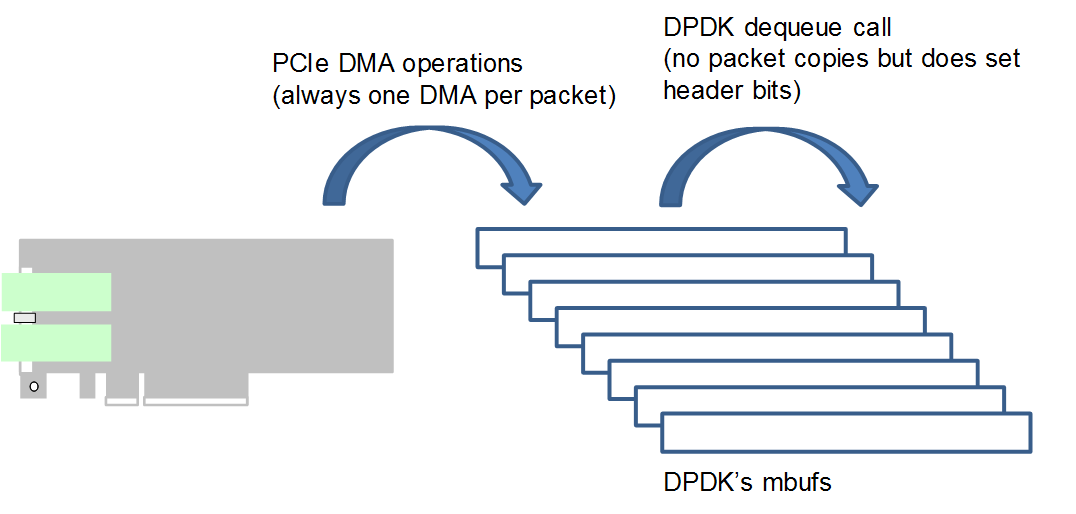
이와는 대조적으로 SmartNIC Shell의 DPDK IP 코어는 항상 DPDK mbuf에 직접 DMA를 수행하므로 CPU가 패킷 데이터를 복사할 필요가 없습니다. 메타데이터에 두 번째 DMA가 필요하지 않으므로 CPU 오버헤드, 지연 시간, 호스트 메모리 요구 사항이 줄어듭니다. 하지만 작은 패킷을 더 적은 수의 DMA로 병합하거나 PCAP 레코드로 미리 포맷된 데이터를 쓰는 등 일부 PCIe 최적화의 기회는 사라집니다. 필요한 경우 애플리케이션 코드는 DPDK 코어 위의 FPGA에서 이러한 작업을 수행할 수 있습니다.
읽을 내용이 더 있습니다: SmartNIC 셸 앱 노트 받기
PDF 다운로드 요청
이 페이지에 표시된 내용은 BittWare의 SmartNIC 셸에 대한 소개입니다. 더 자세한 내용은 앱 노트 전문에서 확인할 수 있습니다! 양식을 작성하여 전체 앱 노트의 PDF 버전에 대한 액세스를 요청하세요.