XUP-PL4 PCIe Card with Xilinx Virtex UltraScale+ VU3P FPGA
PCIe FPGA Card XUP-PL4 UltraScale+ FPGA Low-Profile PCIe Card Dual QSFP28s and DDR4 Need a Price Quote? Jump to Pricing Form Ready to Buy? Check


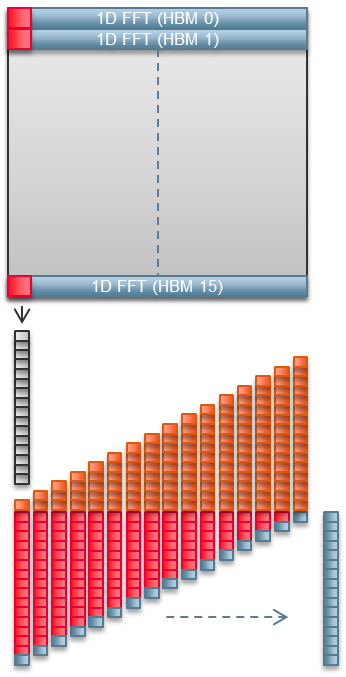
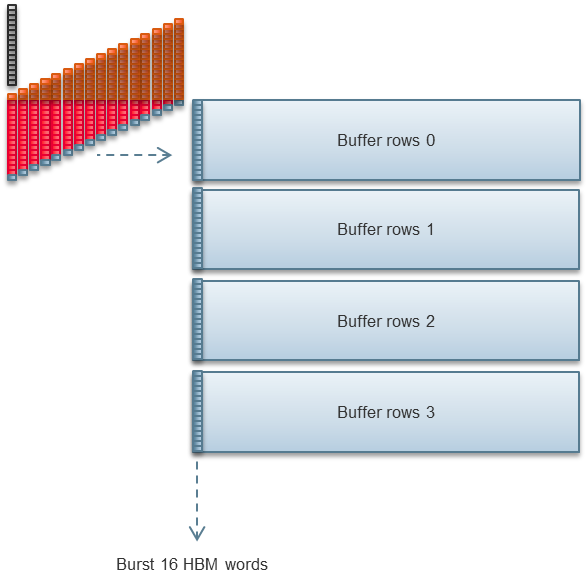
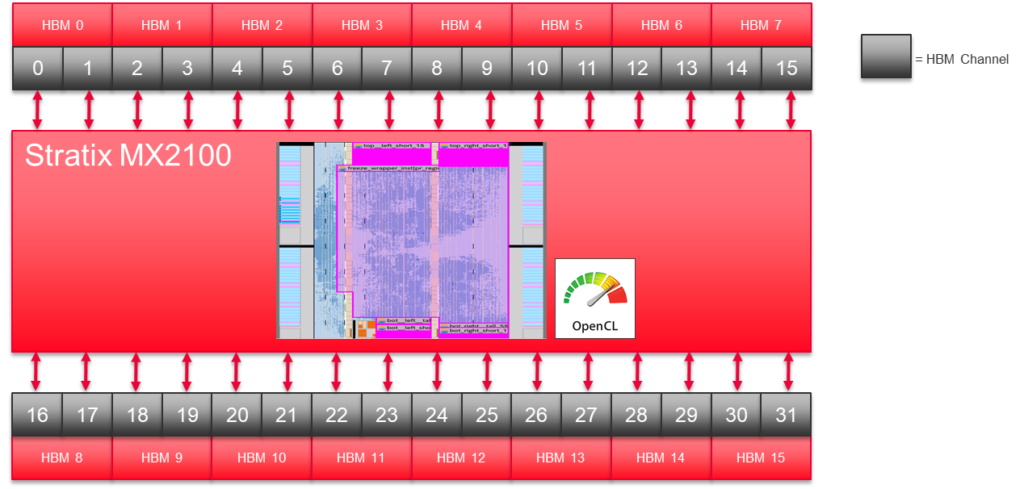 The Stratix 10 MX has 32 pseudo HBM2 memory channels. Our 2D FFT implementation uses half those channels.
The Stratix 10 MX has 32 pseudo HBM2 memory channels. Our 2D FFT implementation uses half those channels.
PCIe FPGA Card XUP-PL4 UltraScale+ FPGA Low-Profile PCIe Card Dual QSFP28s and DDR4 Need a Price Quote? Jump to Pricing Form Ready to Buy? Check

Intel® oneAPI™ High-level FPGA Development Menu Evaluating oneAPI Accelerator Cards ASPs More Info Contact/Where to Buy Is oneAPI Right for You? You may already know
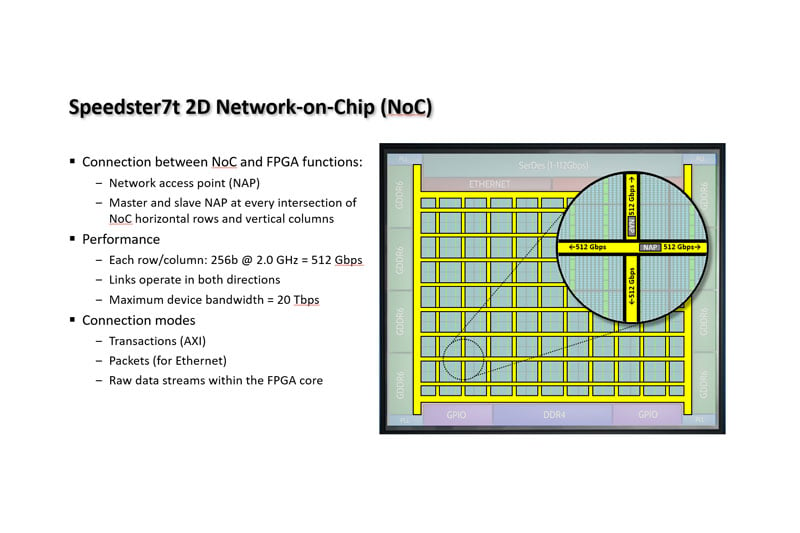
BittWare Webinar Introducing VectorPath S7t-VG6 Accelerator Card Now available on demand: In this webinar, Achronix® and Bittware will discuss the growing trends of using PCIe

Article FPGA Neural Networks The inference of neural networks on FPGA devices Introduction The ever-increasing connectivity in the world is generating ever-increasing levels of data.