
백서
BittWare FPGA 솔루션으로 NVMe 오버 패브릭 구축하기
개요
비휘발성 메모리 익스프레스(NVMe) 프로토콜이 도입된 이후 데이터센터 고객들은 스토리지 애플리케이션에 더 높은 성능과 낮은 지연 시간을 제공하는 이 새로운 기술을 광범위하게 채택했습니다(Gupta, 2018). NVMe의 기능 덕분에 이 기술은 시장에서 가장 빠르게 성장하는 스토리지 솔루션이 되었습니다. International Data Corporation은 2021년까지 NVMe 기반 스토리지 솔루션이 주요 외장 스토리지 출하와 관련된 매출의 50% 이상을 창출할 것으로 예측하고 있습니다(Burgener, 2019).
비트웨어는 기본적인 하드웨어 오프로드(압축, 중복 제거 등)와 추론을 위해 FPGA를 사용하는 머신 러닝 애플리케이션과 같은 애플리케이션별 알고리즘을 구현하기 위한 FPGA 가속 솔루션을 제공합니다. NVMe에 부합하는 성능 수준의 기본 및 고급 가속 스토리지의 이러한 조합을 우리는 컴퓨팅 스토리지라고 부릅니다. 250S+, 250-SoC, 250-U2를 포함한 250 시리즈 제품은 이 시장에 초점을 맞추고 있습니다.
최근 NVMe 컨소시엄은 기존 네트워크 인프라에서 NVMe의 이점을 활용하기 위해 NVMe-oF(NVMe over Fabrics)라는 프로토콜의 변형을 도입했습니다. 데이터 센터에서 온프레미스 NVMe 스토리지가 계속 확장됨에 따라 원격 사용자는 NVMe-oF를 사용하여 오버헤드가 거의 없이 분리된 스토리지에 액세스할 수 있습니다(Gibb, 2018). 이를 위해서는 짧은 지연 시간과 높은 대역폭이라는 NVMe의 장점을 유지하기 위해 하드웨어에 특수 네트워크 스택을 구현해야 합니다.
저희 솔루션은 250-SoC 보드에 온칩 ARM 프로세서인 자일링스 징크 MPSoC가 탑재된 FPGA를 사용합니다. FPGA는 온칩 프로세서를 사용할 때 CPU에서 오프로딩하거나 CPU에서 분리하여 NVMe-oF 컨트롤러 역할을 합니다. 네트워크 프로토콜 스택을 포함한 FGPA 로직에서 NVMe 데이터 플레인을 완벽하게 구현하여 짧은 지연 시간과 높은 대역폭을 제공합니다. ARM 코어는 지연 시간과 대역폭이 문제가 되지 않는 소프트웨어를 사용하여 제어 플레인을 처리하도록 설계되어 있습니다. 이 애플리케이션 노트에서는 BittWare 250-SoC를 JBOF에서 NVMe-oF 컨트롤러로 구성하는 방법을 설명합니다.
NVMe 오버 패브릭이란?
NVMe-oF 프로토콜은 고속 SSD 기술을 사용하여 로컬 서버나 데이터 센터를 넘어 확장합니다.
애플리케이션 개발자는 NVMe-oF를 통해 파이버 채널, InfiniBand, RDMA(Remote Direct Memory Access over Converged Ethernet), iWARP, 최근에는 TCP/IP와 같은 네트워크 패브릭의 원격 스토리지 노드에 액세스하면서 지연 시간을 낮게 유지(일반적으로 100개의 NVMe 드라이브 클러스터의 경우 10us에서 대규모 클러스터의 경우 100마이크로초 추가)할 수 있습니다. 간단히 말해, NVMe-oF 트랜잭션에는 호스트와 타깃이 포함되며, 타깃은 호스트 서버가 액세스할 수 있도록 네트워크를 통해 NVMe 블록 스토리지 장치를 노출하는 서버입니다(Davis, 2018). RDMA를 사용하면 CPU가 트랜잭션을 처리하지 않고 호스트-대상 데이터 전송을 수행할 수 있으며, 대신 전용 RNIC가 네트워크 스택의 전송 계층을 관리하기 때문에 컴퓨팅 리소스에 미치는 영향이 적은 리소스 간에 데이터를 전달할 수 있습니다.
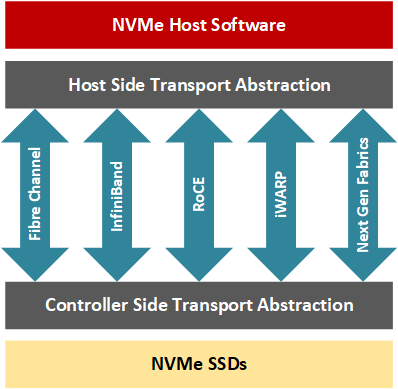
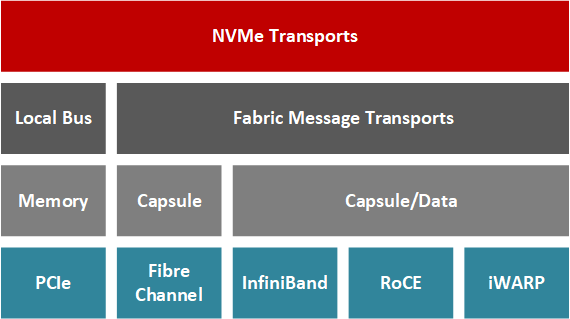
NVMe-oF에 FPGA를 사용하는 이유는 무엇인가요?
NVMe-OF를 PCIe 카드로 오프로드할 때는 기본적으로 세 가지 선택지가 있습니다:
첫째, 가장 비용이 저렴하고 지연 시간이 가장 짧은 ASIC 구현을 사용할 수 있습니다. 그러나 ASIC은 '컴퓨팅 스토리지' 알고리즘을 오프로드할 수 없습니다. 또한 ASIC은 일반적으로 가장 많이 사용되는 네트워크 대역폭에서만 사용할 수 있으며, 가장 높은 대역폭은 거의 없습니다.
둘째, 코어 수가 많은 시스템 온 칩을 사용하여 '계산 저장' 알고리즘을 추가할 수 있습니다. 하지만 이렇게 하려면 병렬 프로그래밍 기술이 필요합니다. 궁극적인 솔루션은 일반적으로 지연 시간이 가장 길기 때문에 NVMe의 짧은 지연 시간이라는 가치 제안에 정면으로 위배됩니다. ASIC과 마찬가지로 이러한 MPP SOC는 일반적으로 가장 많이 사용되는 네트워크 대역폭에서만 사용할 수 있으며, 가장 높은 대역폭은 거의 없습니다.
셋째, FPGA를 사용할 수 있습니다. 이 옵션을 사용하면 ASIC과 같은 지연 시간을 유지하면서 '계산 스토리지' 알고리즘을 추가할 수 있습니다. 이 옵션은 또한 100 또는 400Gb와 같은 고대역폭 네트워크도 지원합니다. 세 가지 옵션 중 가장 비쌀 수 있지만, 스토리지 시장의 규모를 고려하면 비용 차이는 약간 더 커질 뿐입니다.
적응형 스토리지
데이터센터 설계자는 FPGA 및 SoC와 같은 기술을 활용하여 데이터 집약적인 작업을 위해 CPU와의 데이터 이동을 더욱 줄일 수 있습니다. 하드웨어 기반 가속을 통해 사용자 애플리케이션은 더 높은 성능과 더 짧은 응답 시간을 보여줍니다. CPU 가용 사이클 수가 증가함에 따라 워크로드를 분산하는 프로세스는 전용 하드웨어와 CPU를 사용하는 하이브리드 시스템 아키텍처를 보다 효율적으로 활용할 수 있습니다. FPGA 패브릭 아키텍처, IO 처리량, 프로그래밍 유연성은 고대역폭 NVMe 스토리지와 긴밀하게 결합된 재구성 가능한 하드웨어의 설계를 용이하게 합니다. FPGA는 압축, 암호화, RAID 및 삭제 코드, 데이터 중복 제거, 키-값 오프로드, 데이터베이스 쿼리 오프로드, 비디오 처리 또는 NVMe 가상화 등에 특히 적합합니다. FPGA 하드웨어는 전용 솔루션의 성능을 제공하면서도 시간이 지남에 따라 데이터센터의 요구사항이 변화함에 따라 신속하게 용도를 전환할 수 있는 재구성이 가능하다는 장점도 있습니다.
NVMe-oF 타겟을 위한 자일링스 MPSoC 사용
비트웨어 250-SoC는 자일링스 울트라스케일+ 징크 ZU19EG MPSoC를 탑재하고 있으며, 2개의 QSFP28 포트를 통해 네트워크 패브릭과 16레인 호스트 인터페이스 또는 4개의 8레인 OCuLink 커넥터를 통해 PCIe 패브릭에 모두 연결할 수 있습니다. 이 MPSoC 어댑터는 FPGA 패브릭(PL 또는 프로그래머블 로직이라고도 함)의 데이터 스트림 컴퓨팅, 네트워크 IO, PCIe 연결, 온보드 ARM 프로세서를 결합한 NVMe-oF 대상 노드를 구동하는 데 완벽한 플랫폼입니다. ARM은 데이터 플레인이 아니라 제어 플레인 작업을 처리한다는 점에 유의하세요. CPU와 스토리지 엔드포인트 사이에 전용 하드웨어 가속기를 배치하면 데이터에 더 가깝게 계산하도록 최적화된 시스템이 만들어집니다.
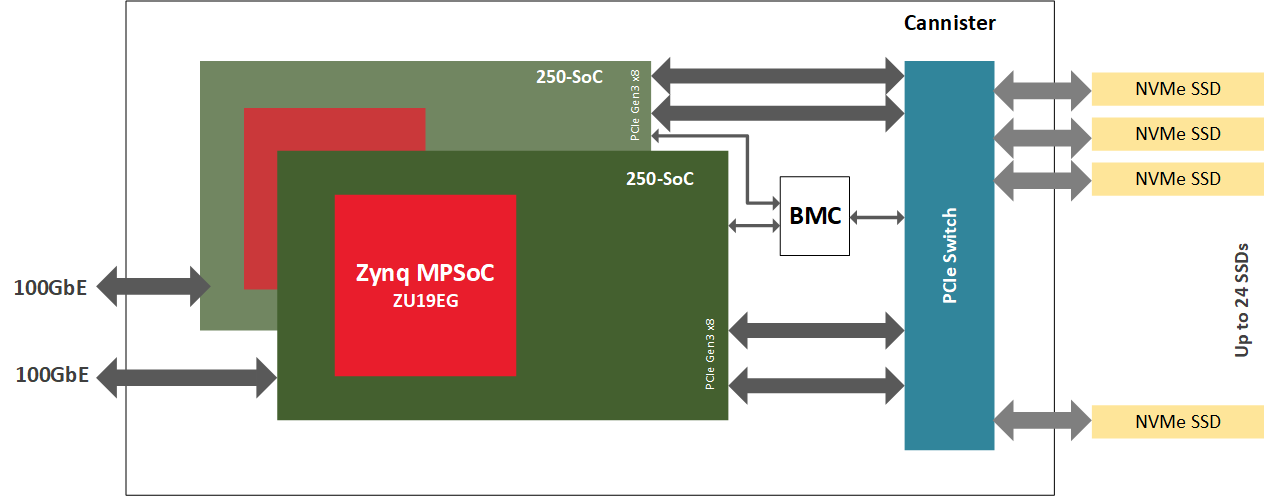
하드웨어
NVMe-oF를 시연하기 위해 BittWare는 여러 개의 NVMe U.2 드라이브로 채워진 JBOF(Just-A-Bunch-Of-Flash) 섀시 안에 250-SoC를 배치하고 250-SoC 보드의 QSFP28 포트를 네트워크에 노출시켰습니다. 셀레스티카 유클리드 JBOF는 PCIe 스위치와 PCIe 슬롯이 있는 2개의 플러그인 블레이드를 갖추고 있으며, 각 서랍은 네트워크 패브릭과 NVMe 스토리지 사이의 통로 역할을 합니다. NVMe 패킷은 QSFP28 포트에서 FPGA 패브릭으로 전송된 다음, PCIe 호스트 인터페이스인 JBOF의 PCIe 스위치를 거쳐 최종적으로 NVMe 드라이브에 도달합니다. 이 구현에서는 250-SoC OCuLink 커넥터가 사용되지 않았지만, 다른 하드웨어 플랫폼에서는 PCIe 트랜잭션이 케이블을 통해 실행되는 이 설계의 케이블 버전을 수용할 수 있습니다.
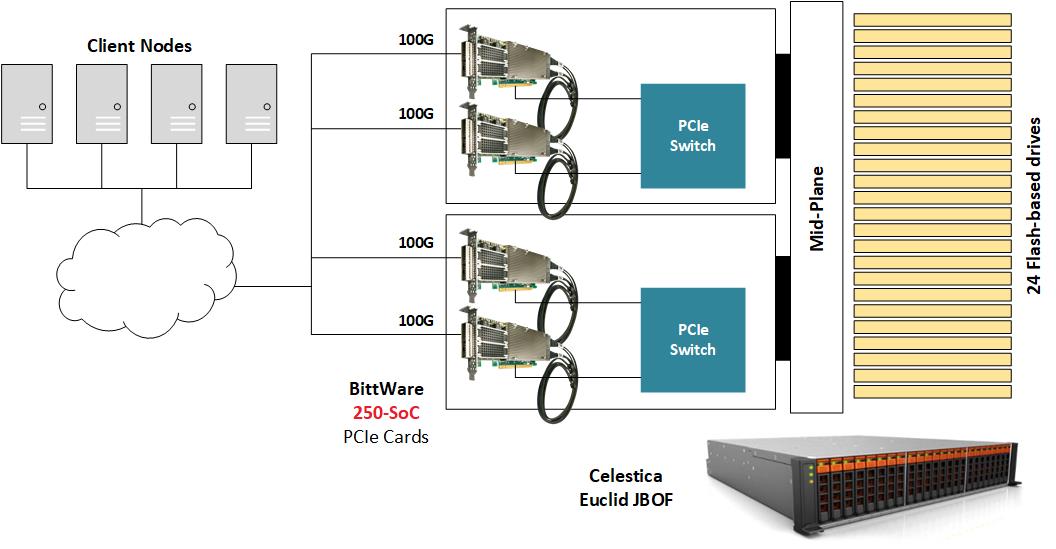
게이트웨어
이 설계는 명시적인 혼잡 관리를 지원하는 RoCE v2(NVMe 1.2 및 NVMe-oF 1.0 사양 준수)를 위한 NVMe-oF 타겟을 구현합니다. MPSoC를 대상으로 하는 IP는 데이터 플레인을 위해 200MHz로 실행되는 512비트 AXI 버스를 통해 상호 연결된 여러 개의 Xilinx IP 라이브러리 블록을 사용합니다. 자일링스 임베디드 RDMA NIC는 100Gb/s 네트워크 트래픽을 처리하고, PCIe 루트 복합 IP 코어는 최대 24개의 드라이브를 구동하는 JBOF 회로에 대한 16레인 PCIe 3.0 인터페이스 연결을 관리하며, DMA 코어는 AXI 버스를 통한 고속 데이터 전송을 제어합니다. 또한 NVMe-oF 타겟 코어는 100Gb/s 데이터 경로를 통해 최대 256개의 큐를 관리하며, 쿼드 코어 A53 ARM 프로세서에서 실행되는 펌웨어는 스토리지 노드의 높은 수준의 관리를 처리합니다.
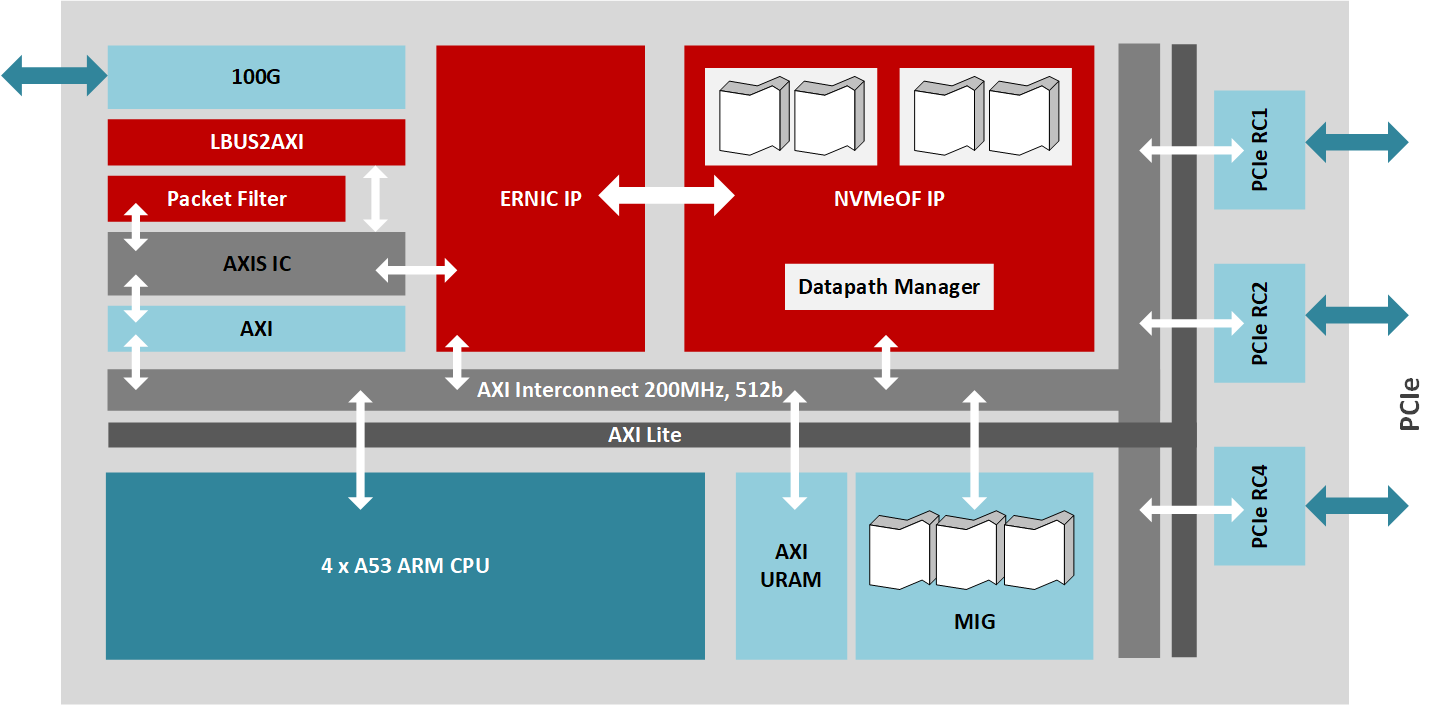
성능 극대화
MPSoC PL은 데이터 경로의 최대 대역폭을 수용할 수 있습니다. 따라서 전체 시스템의 최대 성능을 입증하려면 호스트가 가능한 한 100Gb/s에 가까운 네트워크 트래픽을 생성해야 합니다. 벤치마킹을 위해 두 개의 NVMe-oF 호스트를 네트워크 스위치에 연결하여 JBOF에서 NVMe-oF 타겟을 실행하는 250-SoC MPSoC 카드에 최대 데이터 처리량을 공급할 수 있습니다. 이 레퍼런스 디자인은 약 2.5 MIOPS의 랜덤 읽기 성능과 110만 이상의 랜덤 쓰기 성능을 보여주며 애플리케이션 지연 시간은 105US입니다.
재구성 가능한 하드웨어 솔루션의 장점
MPSoC 기반 NVMe-oF 솔루션은 소프트웨어(CPU + 외부 NIC + SPDK) 또는 RNIC 솔루션(CPU + 통합 NIC)에 비해 몇 가지 이점을 제공합니다. MPSoC 기반 솔루션은 다른 제품에 비해 비용과 전력 소비가 상대적으로 높지만 대역폭, 구성 가능성, 지연 시간 측면에서 경쟁사보다 우수한 성능을 발휘합니다. 마찬가지로 RNIC 솔루션과 마찬가지로 MPSoC NVMe-oF는 네트워크 인터페이스 처리량을 포화 상태로 만들 수 있습니다. 그러나 MPSoC 하드웨어 구현은 다른 솔루션에는 없는 수준의 유연성과 적응성을 제공합니다. 따라서 이 적응형 하드웨어는 도메인별 애플리케이션을 대상으로 할 수 있으므로 시스템 설계자는 고객 정의 기능(RAID 또는 사양이 발전함에 따라 새로운 NVMe 기능)을 기본 IP와 결합하고 전체 시스템 기능 세트를 향상시킬 수 있습니다. 또 다른 옵션은 암호화 또는 압축과 같은 맞춤형 가속기를 추가하여 두 가지 기능을 하나의 상자에 결합하는 것입니다. 마지막으로 솔루션 제공업체는 비디오 처리(예: 비디오 코덱) 또는 인공 지능 워크로드와 같은 특정 목적에 최적화된 애플리케이션별 하드웨어 제품을 만들 수 있습니다. 스토리지 관리와 같은 IT 기능을 일반적으로 고가의 컴퓨팅 노드에서 수행하는 작업과 결합함으로써 CPU는 고대역폭 IO 전송을 수행해야 하는 부담을 덜고 더 중요한 컴퓨팅 작업에 집중할 수 있게 됩니다. 지연 시간 측면에서 보면, MPSoC 기반 솔루션은 CPU 기반 대안에 비해 예측 가능한 낮은 지연 시간을 제공합니다.
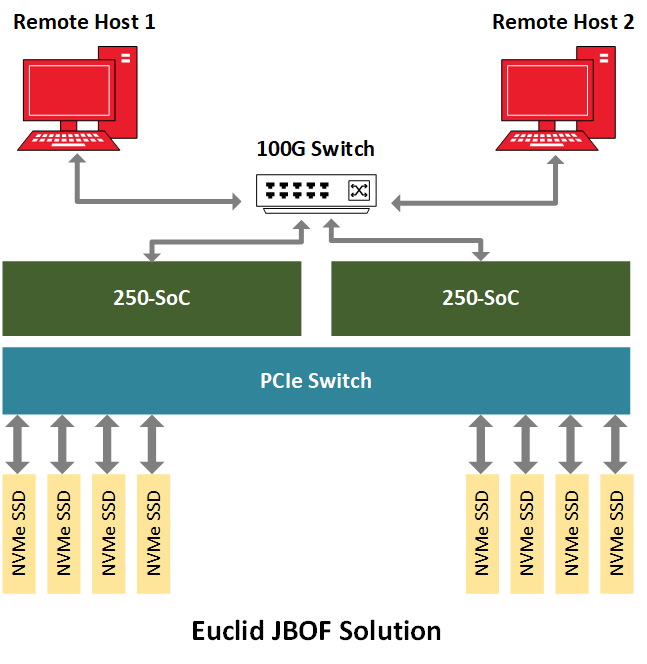
결론
지난 몇 년 동안 NVMe가 발전함에 따라, 이제 분산된 스토리지 환경에서도 NVMe와 유사한 이점을 제공하는 NVMe-oF를 위한 길을 열었습니다(Weaver, 2019). 이 기술은 컴퓨팅 및 스토리지 노드 활용도를 개선하는 동시에 데이터센터의 민첩성과 성능을 향상시켰습니다(Waever, 2019). 예를 들어, 개발자는 NVMe-oF를 통해 새로운 방식으로 애플리케이션을 타겟팅할 수 있으며, 방대한 데이터세트(수백 PB)에 대한 무작위 읽기가 필요한 AI 워크로드는 이 기술을 통해 상당한 이점을 얻을 수 있습니다(Hemsoth, 2019). 이러한 디바이스의 프로그래밍 가능한 로직을 통해 고대역폭 데이터 전송과 짧은 지연 시간을 처리할 수 있는 시스템 아키텍처를 설계하는 동시에 최적화 또는 애플리케이션별 맞춤화를 위해 구성할 수 있는 FPGA와 MPSoC는 NVMe-oF 프로토콜 위에 또 다른 혁신의 계층을 제공합니다. BittWare는 NVMe-oF를 포함한 다양한 NVMe 가속 옵션을 제공합니다. 자세한 내용은 당사에 문의하세요.
참조
- Burgener E. (2019). 고성능 스토리지 제공 업체 3 곳, TCP를 통해 NVMe를 상호 연결 IDC 혁신 기업으로 선정. AP News. 검색된 날짜: 2019년 5월 6일, APNews.com.
- Gibb S. (2018). NVMe-over-Fabric을 사용한 FPGA 가속기 분리. SNIA. 검색 됨 7 월 1, 2019, SNIA.org에서.
- 굽타 R. (2018). NVMe™란 무엇이며 왜 중요한가요? 기술 가이드. Western Digital 블로그. 검색된 날짜: 2019년 6월 24일, Blog.WesternDigital.com.
- Hemsoth N. (2019). 기존 스토리지 인프라는 AI의 병목 현상입니다. Next Platform. 검색된 날짜: 2019년 5월 6일, NextPlatform.com.
- Robinson D. (2019). VAST 데이터는 다운타임과 데이터 손실을 보장합니다. 블록 및 파일. 검색된 날짜: 2019년 5월 6일, BlocksAndFiles.com
- Rouse M. (2019). 전산 스토리지. 기술 대상. 검색된 날짜: 2019년 6월 24일, SearchStorage.TechTarget.com.
- 위버 E. (2019). M & E가 지금 NVMe가 필요한 5 가지 이유. 미디어 및 엔터테인먼트 서비스 얼라이언스. 검색 됨 5 월 6, 2019에서 가져온 것 mesalliance.org