CXL (Compute Express Link) is an industry-supported cache-coherent interconnect between processors, memory expansion, and accelerators. CXL technology maintains memory coherency between the CPU memory space and memory on attached devices, which allows resource sharing with lower latency, reduced software stack complexity, and lower overall system cost. This permits users to simply focus on target workloads as opposed to the redundant memory management hardware in their accelerators.
CXL is designed to be an industry open standard interface for high-speed communications, as accelerators are increasingly used to complement CPUs in support of emerging applications such as artificial intelligence and machine learning.
* CXL requires licensing that is sold separately from the card
IA-860m
The double-width IA-860m card features the ground-breaking M-series Intel® Agilex™ 7 FPGA which adds support for up to 32GB of in-package HBM2e memory. This is an incredible platform for High Performance Computing – especially for applications that are memory-bound.
IA-780i
Our IA-780i combines a large FPGA with the density of a single-width form factor. This card supports 400GbE and PCIe Gen5 x16. FPGA options include the Agilex 7 I-Series AGI019 and AGI023.
IA-440i
The IA-440i is a low-profile PCIe card offering support for the Intel I-Series of Agilex 7 FPGAs. We’ve taken advantage of the impressive F-Tiles to support 400GbE via the front panel. We are using the R-Tile to enable support for PCI Express Gen5, 16-lanes to the host.
BittWare can support CXL because both the Agilex™ I-series and M-series FPGA families feature hard IP allowing for full bandwidth Gen5 x16 configuration support, with minimal use of FPGA fabric resources.
Why is CXL Important?
CXL enables a new level of performance for heterogenous computing architectures featuring FPGAs.
Customers are demanding higher performance and energy-efficient compute capabilities and access to more memory for their applications.
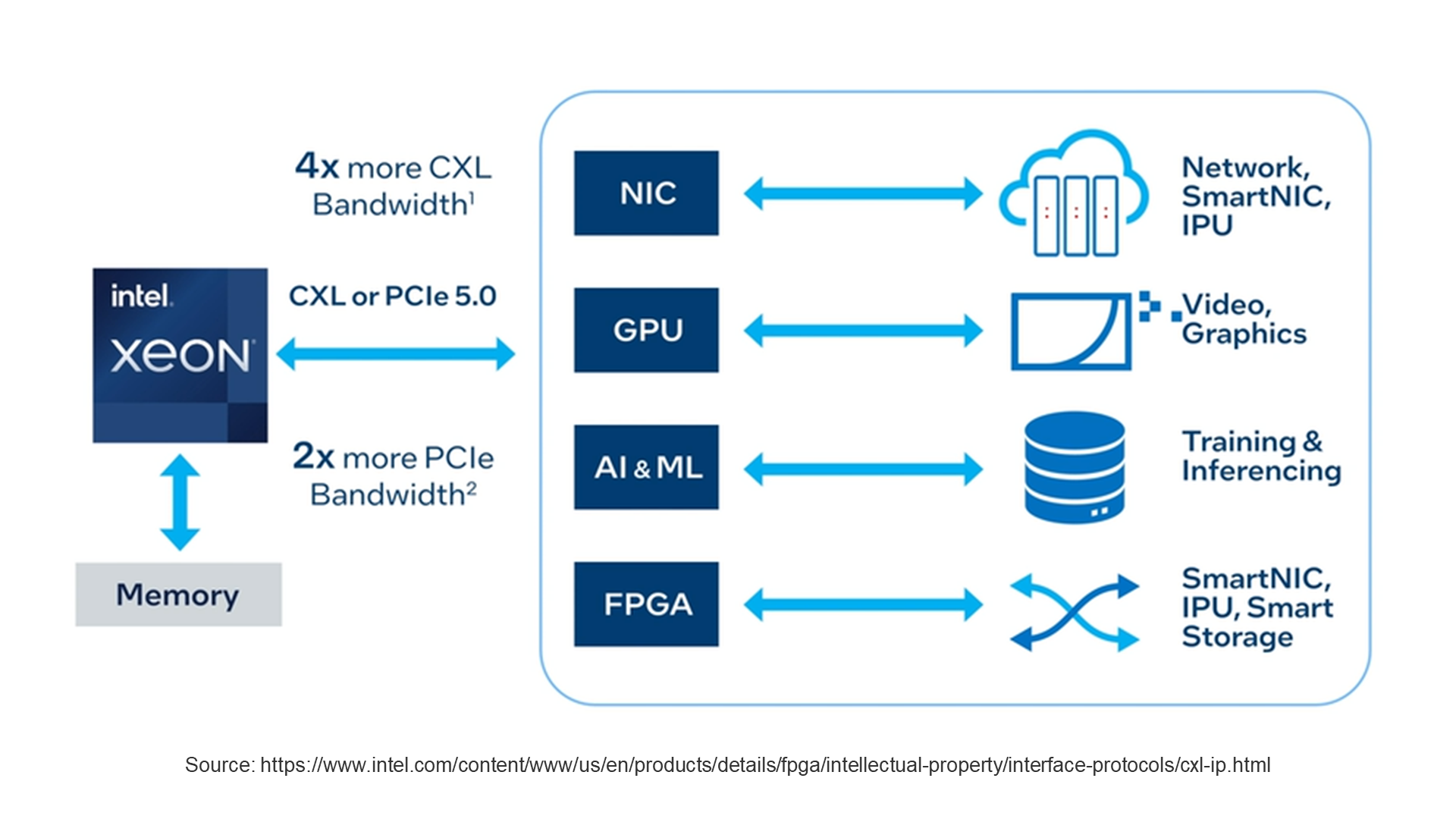
CXL runs on the same high-bandwidth interface as PCIe 5.0, which is twice the bandwidth of PCIe 4.0.
CXL for Compute, Network and Storage Applications
As cloud computing becomes more ubiquitous, customers need to evolve their architectures in order deliver faster, more efficient data processing. This means innovation in Compute, Network and Storage application areas:
The tight coupling of accelerator technologies such as FPGAs for compute-intensive workloads
SmartNICs within the Network area that can process data on the fly
Computational Storage that can process vast amounts of data at rest within the storage plane
Compute, Network and Storage technologies already connect over PCI Express. However, to achieve a step change in application performance they need to leverage the benefits of CXL.
CXL Usage Areas
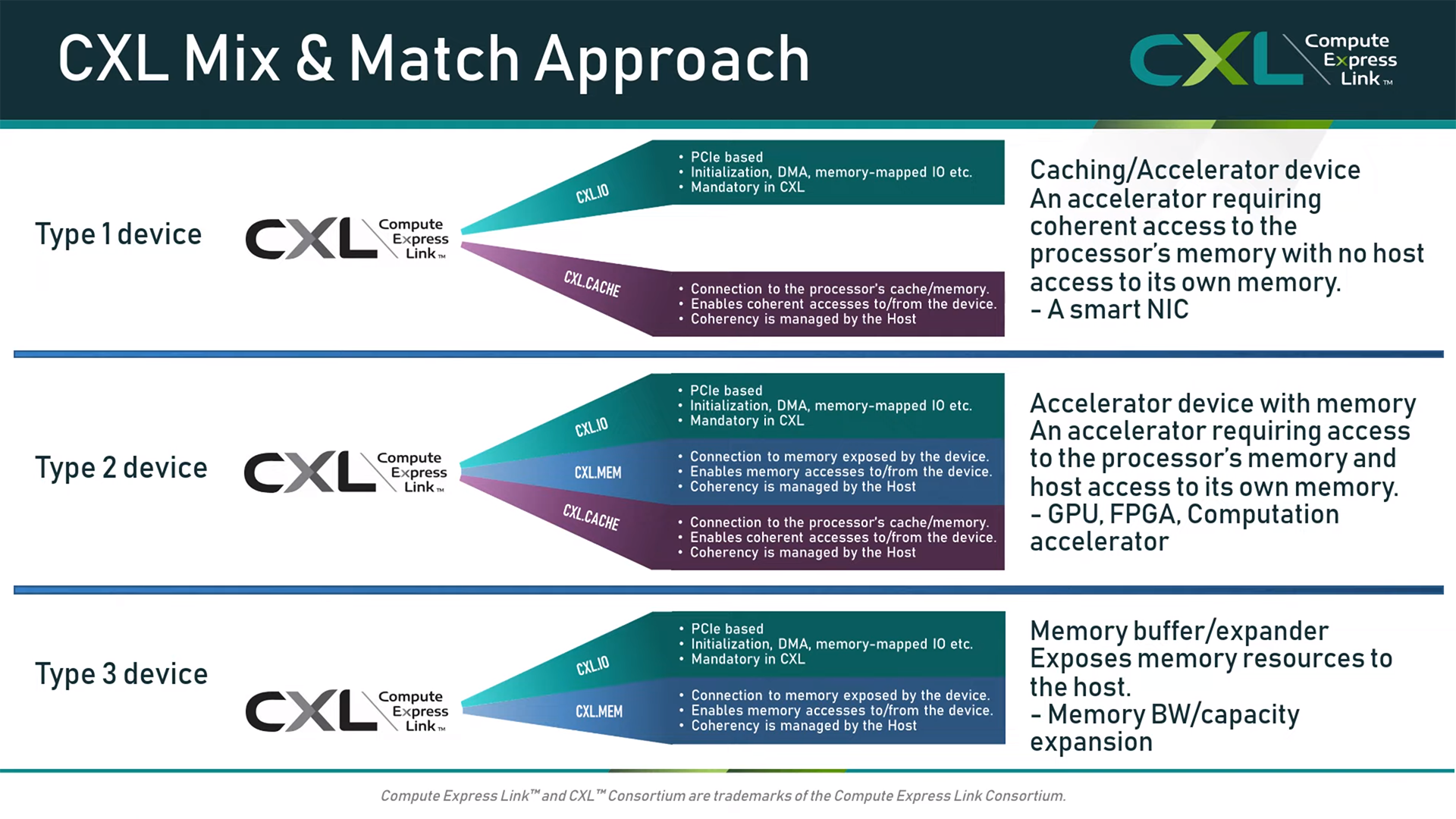
The CXL protocol describes three usage configurations for the CXL-attached device.
Type 1 Device
A Type 1 device can be used for streaming and low latency applications such as a SmartNIC where the accelerator requires coherent access to the processor’s memory with no host access to its own memory.
Type 2 Device
A Type 2 device is the most complex implementation since it handles all three CXL sub protocols: CXL.IO, CXL.Cache and CXL.Mem. This type is intended to be used for complex tasks such as AI inferencing, database analytics or smart storage.
Type 3 Device
A Type 3 device allows any memory attached to the CXL device to be coherently accessible by the host. In this instance, the FPGA can still provide valuable benefits by allowing implementation of special FPGA logic such as unique compression and encryption algorithms.
Getting Started with CXL
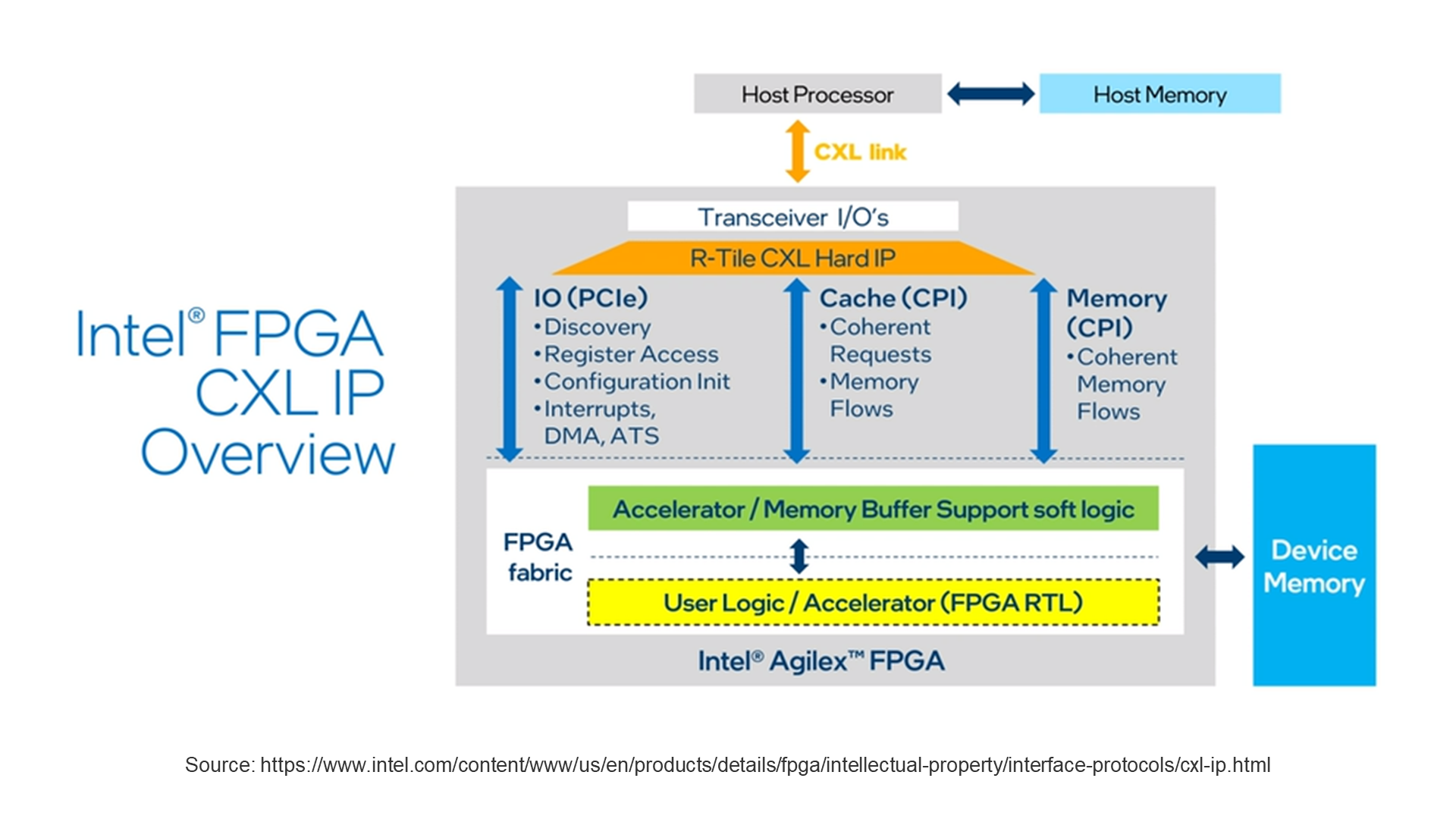
Intel FPGA IP Overview
The Intel FPGA CXL IP is a combination of hard IP and soft IP.
To design applications using Intel’s CXL IP, customers need to purchase a separate IP tools license.
Once you have activated the Intel CXL tools license, you will be able to find the Intel IP inside the Quartus Prime tools.
Once the CXL hard IP for the Agilex R-Tile is activated, then the appropriate soft IP is added to the design.
Compatible FPGA Cards
CXL is compatible with BittWare’s Intel Agilex 7 I-Series and M-Series FPGA cards.