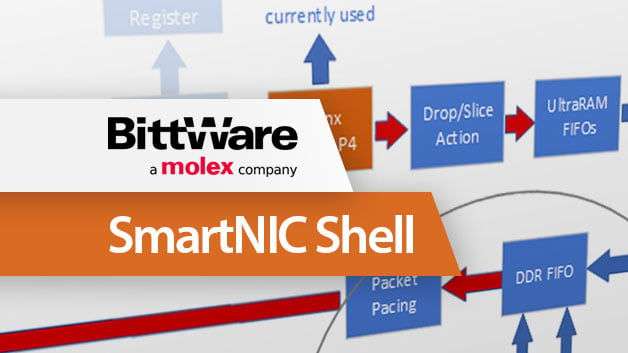
Introduction to BittWare’s SmartNIC Shell for Network Packet Processing
White Paper Introduction to BittWare’s SmartNIC Shell for Network Packet Processing Overview SmartNIC Shell is a complete working NIC that is implemented on a BittWare
Watch the recording for free below!
Technology-driven advances like 5G and autonomous vehicles are generating a data deluge that’s beyond current-generation solutions for moving, storing and processing that information. Thankfully, a range of new advances in those same challenging areas are emerging, including PCIe Gen5 for data movement, AI for automated analytics processing and more powerful processing at the edge.
Three experts in these areas will discuss these emerging solutions with specific examples of hardware and software/IP with a focus on FPGA-based solutions. The presentation will be in a panel discussion format, with an opportunity for live attendees to ask questions through chat. Register today and join us live!








Thank you for joining us today. I am Bryan DeLuca, along with Nicolette Emmino and we will be your host today for this live chat, “How today’s FPGAs Are Taming the Data Deluge Problem,” sponsored by Mouser Electronics, BittWare and Molex.
We have some great panelists, and this is a live chat, so make sure you ask your questions in the Q&A at the bottom of your screen. And now to Nicolette.
Hi, guys. Thanks again for joining us. We are here with our three panelists, Jeff Milrod, chief technical and strategy officer, over at BittWare. Steven Bates, chief technical officer at Eideticom. Shep Siegel, chief technical officer at Atomic Rules.
These three experts will be discussing those emerging solutions with specific examples of hardware and software IP with a focus on FPGA solutions.
So, let’s dove in and we’ll kick off with a little bit of background. What do you think, guys?
So why don’t you tell us—you know, Shep, Jeff, Stephen—why don’t you tell us these three organizations…you’ve partnered together in a new program? Why don’t we talk a little bit about how that serves the market and what you guys do?
Okay, well, I’ll start taking that because BittWare has been making hardware platforms for decades with FPGAs. And the nature of what we’ve done is a platform for these applications. And we are experts at the platform, but not so much at the applications and workloads. And historically, we have sold what we call “bare metal” to our customers who are experts at coding and developing applications on the FPGAs.
And what we’re finding is there’s less and less of a willingness on the part of the customers to do all that hard, heavy lifting of programing the FPGA. And we’ve partnered with IP and solution vendors, like Shep and Stephen, to provide value-added on top of our hardware platform that is stable and proven.
Yea Jeff that’s good, I’ll just jump in here. So, at Atomic Rules, we as a services and IP provider to the FPGA community that does not cut etch—it does not have hardware, we couldn’t have a better partner in BittWare for providing platforms that have cutting-edge FPGAs from all the important vendors out there, so that our IP can be shown in the best light.
Jeff and BittWare/Molex’s desire to have IPs meets directly up against our need to have a platform to deliver the value that we’d like to bring to our customers. Stephen?
Yeah, sure I’ll jump in. So, a great person once said, you know, for a computer…a computer systems to really shine you need two things: you need good hardware and you need good software. And for those gamers out there, a good example of that is you can go and build an awesome gaming PC, but then you need games developers to write the software to run on that hardware, right?
So, you get the best experience of the customer when you have good hardware and good software. And like Jeff alluded to when he was talking, we, you know, Molex/BittWare are fantastic at building great hardware. They can build the best FPGA cards in the market, but they and the customers are becoming less able to develop the great software that really makes that hardware shine.
And that’s where companies like Shep’s and mine step in. So, we work on developing the software, for want of a better word, that runs on the FPGA, but not just that. Also, the software that runs on the host systems and connects it into the application, whether it’s a storage application, the networking application or a compute application. And I think it’s delivering that complete solution that’s something that customers are really looking for: the ability to take something off the shelf from a company like Jeff’s (BittWare/Molex) and then a company like Shep’s and mine—and having something that plugs right in and just works and does something really, really well.
So, we’ve talked a lot…we’ve talked a lot about flexibility in FPGA is right? How flexible are FPGAs? I mean, are they really getting easier to program—if not, how do we use them? Jeff, can you talk to that a little bit?
Yeah. They are extremely flexible and increasing flexibility means increasing difficulty to use, actually, I think. And, you know, I was just thinking, you know, talking through this—the previous question that one of my old axioms, you know, a decade or two ago was “BittWare sold this bare-metal FPGA hardware to the lunatic fringe.” …who are the folks who could actually roll up their sleeves and code this flexible thing…and now instead of selling to them, were partnering with them (laughs).
I’ll call Stephen and Shep lunatic fringe (laughter)…and then we, together…put together something that the non-lunatics can actually consume and use in a reasonable fashion. The flexibility of FPGA is daunting. The fact that it can do anything means that natively it does nothing. So, you know, when, when it powers on it doesn’t even know how to use the memory or the host that’s attached to it.
And that’s where there’s a lot of work that has to be done to build the frameworks and have shells or (different people use different terms) that then the applications and workloads can get loaded into.
But even then, the applications and workloads, you know, there’s these, you know, sea of gates (that’s, you know, Field Programable Gate Array is what FPGA stands for)…and there’s, you know, millions of these logic elements and how do you connect them up to do your hardware algorithm and implementations is exceedingly challenging. And as they’re adding more options and hardened cores, it becomes even more challenging to do a specific workload in that space. And that’s where, you know, our lunatic fringe partners come in (laughs).
Look, doesn’t have to—Jeff I agree—but it doesn’t have to be lunatic fringe. And there are all of these…there are many excellent tools that have been maturing over the past years that make the daunting task of running headlong into a multimillion FPGA more manageable. Because the tools have gotten better but the complexity—to someone whose problem is up at the application level to hit an FPGA—is almost impossible. And that’s why there’s opportunities for companies like mine and like Stephen’s and others to be in this ecosystem to build up a platform on top of that raw brute power of the FPGA.
One of my heroes in FPGA CAD design, Alberto Santelli, and talked about platform-based design in the early ASIC days when ASICs were coming about. But what he preached and studied with regards ASICs has become true with FPGAs. Frequently we’ll use the term overlay to describe a capability—maybe Eideticom makes it, maybe Atomic Rules make it, maybe some of the people on the call are making these overlays—and the overlays serve as platforms layered on top of the hardware and software of the base FPGA to raise the abstraction closer to what the user’s trying to achieve.
Atomic Rules’ business is about delivering products that provide those platforms. Maybe someone wants to move data, maybe someone wants to do computational storage, maybe someone has this other problem. These IP cores are just ratcheting up the interaction level so the job of using FPGAs to do real compute isn’t immediately thrust into, you know, look up tables and timing verification…and just…all of these details which would stifle development…but instead, are amplified by the ability that we can talk about, “Oh, you need to move data from a network to a disk drive to the host? We understand how to do that and it’s this call…” Yes, there’s a lot going on underneath it, but that’s the value that companies like BittWare, Eideticom and Atomic Rules provide.
Yeah. So, I’m not quite sure how I feel about being called a lunatic. Part of me likes it, part of me…
(laughter) Jeff, you really hit a nerve there!
I know you did, didn’t you, Jeff? The way I like to say, the way I like to say it to my friends who are non-geeky is like, “You know what a geek is. Well, if you go talk to a geek and tell them what I do, they’ll say I’m a geek.” (laughter) So I am a geek squared or two geek or I don’t know.
I was about to say the same thing—it’s like geek squared.
So, I think Jeff and Shep touched on it very well. I mean, the tools have got better in terms of, “How do I learn how to work with FPGAs?” But the complexity of the silicon coming from the vendors has also increased—probably at a more dramatic rate than the tools.
And I think there’s been a lot of work over the years to make it easier for someone who has no FPGA experience to get them to do something. But it’s still a hard problem and I don’t think we’ve ever really solved that. We’ve tried to, you know, write C-type programing languages for FPGAs—like Shep said: raise the layer of abstraction. And the problem with that is you often sacrifice performance to get that ease.
So I think what companies like Shep and I are doing are trying to do more application-specific overlays. So, we’re making some…drawing some lines around flexibility. We’re saying you can’t do everything anymore. You do this and this and this. But, with that, comes high-performance programmability. And I think that’s interesting.
I know we’re going to touch on this later, but two things that I think can really help us— in terms of getting FPGA adoption going even faster than it already is—are things like open standards. So, can we have ecosystem-based standards for talking and programing of FPGAs? So, we don’t have vendor lock in anymore.
And then the other is open source. So, can we do the same thing for FPGAs that the Linux kernel and the Linux operating systems have done for software? Can we have a community that can look at the code, that can edit the code as a community, they can make it better, right? And I think those two things—we’ll touch on them later and that’s super important.
I’d like to take that thread for a second Stephen…so, that’s 100% correct. And at the hardware level that exists as well. So again, you know, the field programmable gate array does nothing in and of itself. There’s the logic elements and then there’s the host interface, the memory interfaces, the network interfaces and BittWare provides a lot of examples and shells.
One of the initiatives to abstract these frameworks and foundational platforms—and Intel’s been pushing an open framework stack—so BittWare codes to the open framework stack spec and we instantiate and implement in the FPGA the host interface logic on PCIe, the network interface, the memory interfaces and build out the hardware so that when you turn it on, the FPGA can move data around.
And now, you know, the other model people have used is then there’s a jelly donut and now you know, the application developer puts the jelly and Intel has special tools for that now they call oneAPI, (like Stephen they probably wouldn’t like my use of calling them jelly donut fillers) …and one API works on their CPUs, their GPUs and on their FPGAs if you have this OFS build underneath at the hardware layer. So that now you can code in Intel’s high-level language called oneAPI and get applications running on an FPGA hardware platform equipped with this open framework stack (Open FPGA Stack, actually, I think is what it stands for).
You know, you guys have touched on…a whole lot there in that one question. But really—what I was—what I really wanted to know, and I think we touched on some of these were, you know (and we’ve got some questions coming in from the audience) but I just want to address this first: you know, aside from what we’ve mentioned so far, are there any new developments in FPGAs that we should be talking about right now before we kind-of dive in because there are some questions that are related?
Yeah, I want to jump out right in front of that right away, because there’s…there are. I mean, FPGAs have been at the cutting edge of process technology for a long time. But now for years—three, four or five years—we’ve gotten along with Gen3 PCIe and it seems like over the last two years we’ve jumped to Gen4, Gen5—Gen6 is right around the corner—and CXL (which is interdependent with these technologies) is right in that.
From AMD/Xilinx, from Intel and from others—from all the FPGA vendors—we see the SerDes technology certainly mature enough to handle gen4, right on the cusp of delivering Gen5 (their Gen5 devices, shipping from the major vendors as well). So, I would say that, an Atomic Rules perspective, in talking with our customers, one thing that’s really out front is the explosion over the past year or two of Gen4 and Gen5 right on the back of each other with CXL right on the back of that.
And, of course, it shouldn’t go without saying that that couldn’t happen without the underlying SerDes technology that enabled it. But my short answer (and I really apologize to my colleagues…I had to get out in front of it because it’s changed our business so much) is Gen4 and Gen5 are here today.
Yeah, and I guess the title of today’s webinar is Taming the Data Deluge. Higher speeds and feeds are a necessary…like a critical part of that. You can’t get massive volumes of data into and out of the FPGA, whether it’s on PCIe or CXL or Ethernet, then it doesn’t matter what the FPGA does, it just can’t keep up, right? So, speeds and feeds are like a necessary building block.
But I’ll take a slightly different slant. I think one of the things that really excites me about FPGAs and about the kind of SoC market in general: there’s two things. One of them is just the ability now to put down very capable application processors from companies like ARM and some of the FPGAs are doing that. So, you know, people…you can boot Linux on an FPGA, right? …and turn it essentially into a small server, almost like a little Raspberry Pi. But now you also have flexibility because the FPGA, as well as having the hardened ARM processor cores, also has this flexible logic. That allows you to do some pretty amazing things. Like imagine a Raspberry Pi where you can change the hardware that the Linux is talking to…you can write drivers…it’s a lot of fun and you can do some pretty amazing things. So that was one aspect—that ability to bring Linux onto the FPGA, and to allow software developers to talk to the hardware…that the hardware teams are putting together.
The other thing that really excites me is chiplet technology. So, you know, Intel FPGA teams are already working on a chiplet basis. AMD are very classically known for chiplets in their server processors, so we can expect to see that. The ability to mix and match different components inside the package to allow for, you know, a broader flavor of SKU, I think is really interesting. So if I have an application where I don’t need Ethernet—perhaps the Ethernet is on a chiplet—so I don’t need that chiplet and that’s just a packaging option. If I want ARM processors, they can be on the chiplet and those chiplets can exist at different process nodes which reduces cost.
We can even think about chiplets for things like high-bandwidth memory connection. So, it is almost like…I can almost see a day in the not-too-distant future where I can go to a website and click on “I want these chiplets packaged and delivered to my office,” and I can choose what I want and Shep can choose what he wants and Jeff can package—you know they’ll all be footprint compatible—so Jeff could put whatever one on the card and we basically get much more variability without increased costs and I think that’s very exciting.
Yeah, and Intel land, of course, they call the chiplets “tiles” using their EMIB interconnect—and they’ve been doing a lot of work with that. And as you say, the ethernets and the speeds have gone up dramatically like Shep was coming out with PCIe, you know, in conjunction with that, they’re increasing the speeds of the Ethernet network feeds, you know, up to the 100 gig and NRZ…100 gig excuse me, PAM4 speed—so, 400 gig max that can be bound. And that’s just not even a big problem now.
And then same on the memory side: external memory interfaces, the DDR5s and then, as Steven mentioned, the internal high-bandwidth memory tile. So, you can add, you know—on some of the new FPGA is coming out—and get 32 gigabytes of in-package memory that is attached at a very high-speed local bus to the FPGA.
The other challenge that’s happening (a notable new development with that) is—as these speeds and feeds, as we call them, continue to increase on the external chip—there becomes serious restrictions as to moving all that data around…and people parallelize their busses and the clock rates are going up—but the other nonlinear step that everybody seems to be taking in the vendor community semiconductor level is adding Networks-on-Chip to move data around at much higher bandwidths.
And that does two things: it allows you to move in between peripherals and also allows you to move them within your logic element. And as these logic arrays get bigger and bigger (with millions and soon tens of millions of logic elements) moving your data into there for processing is hard—but now moving that same bandwidth from the first packet processor to the post-processor…you got to move it all the way across that big array—and that’s another place where the NOCs can come in (Network-on-Chips: they call them NOCs…N-O-C).
If we’re veering into NOCs I want to just jump in a bit—maybe we’ll come back to it a little bit later…because NOCs are a big topic—not in the least because of the marketing around them, that the different FPGA manufacturers are using with regard to hardened NOCs. I just want…I don’t want to let it go by that here at Atomic Rules and certainly other places we were really inspired by the research done over the past 20 years on the Hoplite network that Jan Gray and Nachiket Kapre developed. You can Google it and look up Hoplite and all the work around it. What a terrific platform to investigate NOCs, their benefits (and their costs) in a soft fashion and we’ve been inspired by that work in our own soft NOCs that we use for data distribution in places where there is not the benefit of a of a hardened NOC that suits our needs.
And just like the of the platforms that I was talking about before, NOCs—hard and soft—can serve as layers of that platform to build up your abstraction. Jeff was saying, “How do I get the data from my Ethernet side over to my PCI side, over to my memory, over to my storage side?” Absolutely. And I view that as just another type of abstraction that can be wrapped up and bundled as a benefit to reduce the complexity and essentially hide some things that you just don’t want to know in order to get at the real valuable application-level details.
You know, we had a question from the audience about NOCs and a hardened NOC specifically. I just want to raise that question. You may have addressed it there, but maybe we can fill it in here. An audience member asked, “How can hardened NOCs between different hardened peripherals and internal logic gates affect the fastness of internal data paths which FPGA was lacking from the last two decades?”
Yeah, and that that’s a detailed hardware question and it is a problem. You know, we’ve always…I’ve used the term informally that, you know, all this crazy stuff—moving all this data around—is kind of like plumbing. And you’ve got to plumb it up…if you want to have, you know, your water coming into the house: that’s one thing. If you want it at the kitchen sink and in your bathroom, you know, you got to plumb it up. And the…that analogy really works for FPGAs. And then if you want to have, you know, a little bit of water coming out of your kitchen, that’s one thing. But if you if you need a fire hose in your kitchen, you need a different kind of plumbing structure, right?
And that’s where the hardware NOCs come in and where all the vendors are now wrestling with this. And they have them in various degrees between peripherals, as Shep was saying, just, you know, moving from Ethernet to PCIe and then different ways they can get it into the fabric. And as I was mentioning, so if you got a 400 gig Ethernet coming in to a hardened MAC FEC…now the output of that, you need to do some packet processing in your logic…okay that’s attached. Now the output of that logic, how do you move that somewhere?
So now you need a NOC that can access in the fabric and they have these network access ports. Some vendors are incorporating those aggressively, some are planning them in the next gen. Everybody’s moving that way. And of course, like any of these technologies, even though on marketing slides, they kind of look like fairy dust, there’s always devils in the details. And they don’t solve all the problems and they have some other issues, one of which is you start toggling things at, you know, gigahertz rates at massive bandwidth and bus-widths…things get hot.
NOCs tend to increase thermal dissipation because the more bit you flip in, the hotter things get. And the farther they go, the more capacitive load they have. But they are a great tool that is now being leveraged by the community and will be on all hardware subsequently, I think.
And, kind-of just adding to that, you know the phrase I love is “drinking from a fire hose.” So, you know, we think about these incredible data deluge speeds and feeds. If you if you want to look at every single packet or every single bit that’s coming in off the wire from the host, you’d better be able to consume that, right? Otherwise, you are literally drinking from a fire hose and that’s not going to end well.
So, we have to make sure we can move this data around, you know, within the devices. I think Jeff’s point on thermal—like things heating up—that’s a really good one. So, one of the great things that I love about the partnership we have with Jeff’s company is, you know, his company are very good at thinking about things like thermal.
And the fact Jeff brought it up kind of reminded me it’s important. You know, in my past I’ve programmed an FPGA and it wasn’t getting cool—like there was no fan blowing over it…and I blew the damn thing up! I’m going to admit that…maybe I shouldn’t (laughter)! But, if these things get so hot when they’re working hard, so it was sitting there idle—doing nothing—then it was happy. Then I made it do…a lot and suddenly it got very, very hot very, very quickly. And Jeff, you know, Jeff’s company thinks about that.
Have you gotten one hot enough, though, where it reflows the solder joints and actually falls off the board?
I haven’t done that yet.
That’s when you know you’ve got something going!
That’s pretty hot, guys, that’s pretty hot.
So, it’s great that BittWare and Molex take care of thing. That’s what they bring to the table is that experience around, “How do we keep these things cool, so they don’t know they don’t die?” Yeah, that’s really important.
Okay, so we’ve been talking a lot about data, right? And let’s dive into that. We talked about in the digital domain a lot…let’s also talk about the data deluge within sensors, right? How are FPGAs helping the analog world also. Jeff, that’s probably a hardware question.
Yeah, and one that is also super deep. So, there’s two quick answers to that.
One is that most…BittWare used to do a lot of analog interface boards, and moved them into signal processing resources…largely FPGAs.
Now there’s standardization for that so we don’t do that anymore. Generally, when people are converting analog signals, or, from digital to analog in a transmitter—they do it somewhere at a radio head or a sensor head. And they then digitize it and packetize it and move it over.
And so most of our applications now that are doing sensor interfacing and processing implement—whether it’s JESD or VITA49 or the new emerging DIFI standard for RF—we interface to some standard packet protocol like Ethernet that just is moving data around.
The other way is (you know, we were talking—Stephen was talking—about the chiplets and tiles) various vendors are now adding analog to digital converters and digital to analog converters as those check-box options that Stephen can just…order you know, in this color with that feature on it. And you can get it with ADCs or without ADCs, and you can do actually direct analog interfacing.
And we have—BittWare has—hardware that takes direct RF at 5 GHz in, and digitizes it…has hardened down-converters, up-converters and then moves it into an FPGA fabric for post-processing. So that’s one of the ways that’s happening.
You know, we have a lot of questions coming in from the audience. I’m going to hit one of them right now. Let’s see…can you talk about the viability of FPGA in the domain of edge computing from a cost perspective. Are FPGAs going to be a better fit for device edge or on-premise edge?
Well, cost is one of those things like bandwidth and performance…you know, it’s all relative, you know? And I cringed a little bit when Stephen was talking about Raspberry Pi, because that’s a slightly different price point. And FPGAs, in general, are not cheap.
You know, our sales guys, I’m sure are—if they’re listening to this—are shooting me darts now. But the nature…another thing I heard somebody call it the other day is—FPGA is a field programmable gate array but another term for it is a flexible, pretty good ASIC right? And I like that approach and that term. ASICs are super-expensive to develop and very cheap to deploy once you develop them, right?
FPGAs do it a different way. The development is still hard, but it’s nowhere near as expensive as an ASIC development. But the recurring cost for the devices themselves is much higher. And when you want to start having then PCBs and power supplies and thermal constraints, they can be fairly expensive solutions. And they…when you get a big enough thing where price is dominating, people drive at the ASICs, and that’s just a cheaper way to deploy and the market’s proven that.
So, FPGAs are quite good at doing things that you can’t do more cost effectively. In that sense, FPGAs can be super-cheap because, regardless of how expensive that hardware is (and the IP from our partners), if you can’t solve it any other way and you’re adding tremendous value to your market and growing your serviceable available market—it’s a very efficient spend of money. But the cost is not usually where we win in and of itself.
But Jeff there are other ways that FPGAs can bring value. I agree with what you just said but I have to jump in and point out that frequently, despite their added cost—despite their added complexity and challenge to integrate—FPGAs are used to offload operations that might require expensive heavy cores from AMD and Intel to otherwise the same work.
And the net gain…although many applications don’t go into this going “My job is to reduce the number of cores used.” It’s usually: the job is to solve a particular computational problem. But along the way they end up realizing that an FPGA-enabled solution (perhaps because of some cleverness in how the data moves from the network to memory to storage, for example) has to travel less and requires less expensive heavy iron, as it were, particularly in a datacenter or an on-premises situation, as opposed to out in a more power-sensitive fielded situation…and that cost savings in terms of, “Well, I need that much less strong a host processor to get it done” …is recurring savings that can be used to fund the expensive FPGA development and the pricey boards…
It’s a total cost of ownership thing and I think Stephen’s applications in computational storage is particularly relevant to this that, you know, the computational storage solutions, I don’t think anybody would argue are cheap, but the cheaper than the alternatives.
I mean…let’s talk a little bit about computational storage…and I also want to talk a little bit about moving data, right? You know, from your guy’s perspective—both Shep and Stephen.
So, I don’t know if you guys want to talk about computational storage first and then we could go back or moving data first?
Yeah I’ll jump in on computational storage. So, the computational storage—what’s happening is, you know, the amount of data the world is producing, it’s just increasing exponentially, right. And I think the other thing that businesses have realized is that that data is kind of useless unless you can analyze it and develop business intelligence and clever business decisions from the data, right.
Storing data like, you know, there’s not that much point to it. Getting insights from that data is now key. And companies want to do this quickly and they want to do it efficiently. And so what they’ve noticed is that, rather than putting a whole bunch of data like Shep alluded to back to Intel or AMD CPU cores and running software, it’s better to push your queries to the storage layer and actually have the storage layer run these kinds of tasks. Whether it’s a database query, whether it’s AI inference over a bunch of sensor data, whether it’s like, you know, analyzing a database for some kind of business metric.
So, standardization is occurring in an area we call computational storage. So rather than just having boxes or devices that store data, how do we also have the ability to push compute queries to these boxes, whether it’s a drive, whether it’s an SSD or whether it’s a box full of them—something like a NAS, right? And so, standards are developing around that, and FPGAs have a great role to play because like Shep alluded to, there are certain tasks that are much more efficient, much more cost-efficiently done with something like an FPGA.
But also you want that time variability. If the query changes you, perhaps, want the functionality to change, and that’s where FPGAs really shine: where there’s an ability to have a certain characteristic at time “A” but maybe a different time of day your workload changes and you actually want the processing power to change its characteristics. That’s really hard to do with an ASIC, but it’s super-easy to do with an FPGA.
You know, computational storage…also involves standards. And like I alluded to earlier, standards (in my opinion) drive market adoption, which pushes prices down. And that’s always the way, right? So, buying one FPGA can cost you a lot. If you come in and ask for half a million of them, you’re probably going to get a better price per unit.
Yeah, and another point on…like everything else with FPGAs: there’s a wide range of capabilities and you can buy FPGAs in the Raspberry Pi domain, pricing wise, but some of them are, you know, over $10,000 for a single chip (in the extreme cases) and BittWare similarly has a wide dynamic range of options.
So in Stephen’s applications with computational storage, when people are deploying a large number of computational storage accelerators, we can sell stuff, you know, a thousand bucks or less for limited applications where we know what the use case is. And we have other things for 400 gig—and those things are approaching several thousand dollars for a solution.
And we have stuff coming out soon that will be even more with these HBMs and all that. So, there is a wide range of cost. But, when we’re looking at it for Edge and IOT deployments, it just depends on what you think “a lot” means.
So Shep, do you want to talk a little bit about moving data?
Sure. (laughs)
We could be here for a while if we’re talking about moving data, right? (laughter) Everybody buckle in!
We’ve got 25 minutes; we’re good, we’re good.
So, thank you for that question. One of…I’d say Atomic Rules marquee IP product is a product that goes by the name of Arkville. And Arkville is Atomic Rules brand for a DPDK-based data mover. It’s an IP core that makes it relatively easy to move large volumes of data from an FPGA to host memory or the other the other way around without diving in to much of the lower levels I was talking about with that platform-based design that are essential in order to pull that off at simultaneously high throughputs and relatively low latency.
The…from a systems architecture viewpoint, the whole notion of data motion is really quite simple, right? I’ve got data part “A” in the FPGA want to get data to place “B” inside the host memory, for example. The software engineer might want to call memcpy or, you know, move data and have that happen.
Our goal, to our customers, is to bring that experience as close as possible to what they’re looking for. Data from the FPGA hardware into user land host memory—no questions/problems asked.
Yes, it’s a lot more complicated than that, but that’s what our customers are buying. They recognize that, in order to do that task that’s so simple to describe, that underneath it, there’s hardware design, software design, API design, driver design, FPGA timing closure—all of these pieces, and in large part, Atomic Rules delivers a complete solution to that which has terrific value if, in fact, data motion from an FPGA to something that looks like host memory is important to you.
Yeah, maybe just to jump in and add to that. So Shep mentioned DPDK, which is a host software stack in the networking field, which is designed to move traffic from host memory onto the network or from memory to memory. I work more in the storage domain and, ironically, storage is also all about data movement. There’s data on a disk and you want to get it into memory because you want to process it or you have data in memory and you want to get on the disk and you want to keep it safe because it’s like your picture of your cat that you love and you love your cat…
So, there’s quite a few storage standards that are also relative to data movement. And so, we kind of do exactly the same thing as Shep. We create these data movers in hardware on the FPGA, but then we have to present an API to the host and to the customer. And we use storage-centric ones where Shep uses network-centric ones.
So for us it’s things like NVMe (NVM Express) and a lot of your SSDs in your laptops or in your gaming PCs today have NVMe drives. And another one is SDXI, which is a new standard that’s emerging specifically for data movement. And so these allow us (as what I call software vendors) on the FPGA to integrate with well-understood stacks on the host side (in Shep’s case DPDK, in my case more like…things like NVM Express or SDXI).
All right guys, so I want to talk about CXL for a second. So, when we were chatting yesterday, you know, Jeff, you mentioned that this is quite the buzzword these days. And I thought it would be important for us to just mention this…talk about what’s on the agenda for a board with CXL, and then after maybe Steven and Shep, you could share a little bit about what your imagination will do with such a thing.
Okay, Jeff?
Well CXL is…has certainly caught everyone’s attention. And again, I think promises at the high level, and if you read all the press, you know, there’s magic fairy dust that makes everybody’s problems go away. But that’s certainly not the case but it does abstract (it’s Compute Express Link) and it allows the abstraction and interconnection of IO/cache/memory into a single coherent domain that anybody can see anybody’s information and data.
And there’s various ways this is being implemented. One of the things that—while I do think it will certainly change our industry and dramatically impact how people architect and deploy solutions—it’s not, in my opinion, completely clear how yet. And I don’t think many people have said, “Ah! I got it—I know how to do everything now.” It’s opening up whole new dimensions and capabilities that people haven’t had the ability to think through before. And I think there’s going to be fits and starts and people will try, “Oh, let’s connect it this way. Oh, wait, that that doesn’t work great. You know, maybe there’s a better way to do it.”
The other thing is that it is earl y days technically. So, the FPGA that we’re bringing to market at the end of this year, we’ll support CXL 1.1. There’ll be…2 will be coming out later, I think, in 2023. And then 3.0 is already documented and planned and released and that’s more 2024 kind of timeframe. So, at the hardware level, there will be an evolution as well as an evolution of, you know, people getting smarter on how to build systems using CXL.
Yeah, if I just jump in there, I mean…so CXL, for those who don’t know, is a protocol that runs over the same kind of wiring as PCIe. So, if you look at your laptop or your gaming console or your gaming PC—anywhere you can plug in a PCIe device—in theory, in a few years from now, you can plug in a CXL device.
Now the next question is “Why would I do that?” Well, PCIe has some limitations around data movement. The biggest one is it’s not what we call cache coherent. So, you have to be a little careful when you move data to a graphics card and some of those…or to a network card over PCIe. And our operating systems take care of that for us.
With CXL, it’s actually a coherent protocol. So, it allows us to do some things that we can’t do with PCIe. Now, we’ll still be able to do a lot with PCIe and we do a lot with PCIe. But, like Jeff alluded to, CXL opens some new kind of paradigms.
And, like he said, we’re not quite sure what we’re going to do. But, based on what I’ve seen in the industry, the first thing a lot of the big cloud companies are going to do is memory disaggregation. They’re actually going to move some of the memory off the DDR channel on the processor onto a CXL card, or even a shelf of CXL for people like hyperscalers (like Google).
Now the way I look at it is, if you’re going to do that, then maybe you can start putting some compute services that can operate on that memory the same way we do computational storage. So, can we push compute to the memory? And, in order to do that, we probably need some flexible algorithms—so FPGAs start to resonate with me. So, I think that’s an area where FPGAs have a lot of potential.
I think the other point to note is: we don’t really know how it’s going to play out—so we will need flexibility. So, I think there is an opportunity for FPGAs particularly early on because we’re not 100% sure what we want to do. So, we’re not going to spend $50 million to tape-out an ASIC. We’re going to experiment with FPGA. We might deploy them in reasonably large numbers. I…unfortunately, you know, if the application is big enough, somebody is going to say, well, I’m going to spin an ASIC on this.
But I think there is an opportunity for flexibility because workloads do shift and I’m very excited by that potential.
So, Stephen, so I have…I think many of us who’ve been following CXL have heard that memory disaggregation is going to be, sort of, the “Aha!” moment for CXL. But I’m having a hard time coming to terms with what disaggregated memory means to the latency of those memory loads and stores to the client that’s actually using it.
I guess that’s a challenge that CXL will have to rise to because, you know, you’re talking tens of nanoseconds today on a contemporary host processor, going up to hundreds of nanoseconds over the kind of SerDes that CXL are looking to go over now. So, I’m personally…I don’t want to bet against that, but I don’t see that happening right away.
For our part, at Atomic Rules, what we’re doing to get after CXL right away…Intel has moved aggressively out of the gate with their I-series Agilex devices…we were talking about chiplets and tiles earlier…the corresponding R-tile (which we use as part of our Gen5 Arkville today…is shipping in Arkville 22.07)—we don’t have CXL I want to be clear—but that R-tile that’s enabling PCI Express Gen five…we’ve taken Intel’s capability of using CXL and PCI side-by-side and we’ve taken…very few of our customers need the full firehose of Gen5 x16 today. Some of them certainly want that, and we’re going to serve them for sure. But let’s just say, you know, 100 gigabit Ethernet or multiple hundred-gigabit Ethernet or 100 gigabit pipes is more popular today than 400 gigabit is.
We’ve taken those 100 gigabit and 400 gigabit streams, split them apart such that today on Intel’s I-series R-tile we can have Arkville working with a gen5 x8 endpoint (half the available bandwidth) and leave the other half of the R- tile channel available for CXL. To be clear, Atomic Rules has zero…zero offering today supporting that CXL capability.
We’re looking at it as others are quite closely and we think it’ll take some learning. But…our small move in that direction is not taking any moves that would inhibit CXL adoption by, for example, going, “Well you know, if you want to use Atomic Rules, then you’re going down the PCI path and you can’t have CXL with it.” We’re the opposite of that. If you want CXL mixed with your PCI, you can have them both at the same time.
So here’s another audience question: “Do you foresee higher optical I/O like co-packaged optics with FPGAs requirements for SmartNICs growing to grow beyond what programable pluggable receivers do?” I think is what they’re asking. Transceivers sorry.
The answer is yeah, I wish they would be there now. And one little anecdote I tell is when I started my career in the eighties, I worked with some people who were talking about, you know, all this copper stuff in these back planes are old news. We’re moving to optical back planes and optical interconnects in the next few years (and this was in the eighties, mind you). And none of that has come to pass, of course.
Now Molex is working a lot on that—and that’s not my area of expertise and I’m not familiar with what we’re doing there—but there is certainly a desire and a move, as we’re getting to faster and faster signaling, to get these things off of the chip into the package, from the package to a PCB to connector more effectively.
And the ultimate way to do that is going to have to be photonics at some point. And there’s two levels of that. One is connecting the chip via copper somehow to an optical engine in the package, and you plug in optics into the package. The other way that people are talking and working on is integrating optical engines into the silicon. And you just have a laser…on your die that shoots out and that’s further out. And I don’t know much about that, but I wish it were true…but I’m not counting on that anytime soon.
Yeah and I think this is another opportunity for chiplet technology. This is again why things like UCIe excite me because, you know, silicon photonics and things like that often require a completely different fabrication process than the one the FPGA flexible logic wants…which is also again different to what the ARM cores want…which is different again to what the analog transceivers want.
And so, the chiplet technology: we actually get to pick different processes and potentially even non-silicon based semiconductors (if it makes sense) which it often does in silicon photonics. But I agree with Jeff. I am sure Jeff has customers who want the fastest speeds and feeds today—and that requires optics, particularly optics off the chip—and we’re not quite there yet, but we need to get there because the data deluge just continues to grow.
Yeah, but…photonics has its place and it’s certainly where you have to go if we’re going to look towards the future in that way. I personally feel that we we’re in an era where the enormous, truly enormous gains in SerDes technology over the past few decades that have been made can be harvested before we throw our hands up and say we’re done with analog. We’re just getting into PAM4 signaling at this point. And, you know…we know that we see the end of the road.
But there are so many opportunities to reduce power, to reduce complexity—to make these subsystems which are essential for things like gen5 PCIe and CXL to work…work more easily, be affordable—not require a $10,000 FPGA to carry that substrate. And I think that the market may find opportunity for the boring old…32 gig SerDes of today to find a way for it to be cost-reduced and placed into a less expensive FPGA, yielding solutions that look more like today’s solutions, but at a lower power and a lower cost point.
All right, let’s take this question. “What sort of skills are needed to turn a bare FPGA into something that solves a particular problem? How can I leverage what you do to make my FPGA deployments more successful? So I…Stephen, maybe you could take this one? I think we could talk a little bit about the partnership here, it might be a good opportunity.
Yeah. I mean, I think, you know, there’s a couple of different things. You know, first off, for anyone out there who’s listening to this webinar going, “I kind of want to play, I want to get down and dirty with an FPGA.” I will say there have been, you know, amazing developments on tools and, you know, academic-based platforms for learning how to work with FPGAs.
And there’s a big drive right now to make more of the FPGA flow open source—vendor neutral. And there’s some great programs, if you Google them, that can do that. And there’s some amazing online learning. So, if you want to learn—like if you want to become a geek squared, you know—there is really good stuff out there and it’s worth digging that up and starting to play around. You can buy a cheap board…you can connect it to your laptop or your desktop. You can go online—there’s YouTube videos, there’s free courses and you can start playing with these things straight away, and that’s a really good place to start.
Now, if you’re more interested in getting FPGAs deployed that solve a particular problem for your business, if you don’t want to do it yourself, that’s where you come to people like Shep and I for the software to raise that level of abstraction so that your engineers don’t have to talk FPGA languages. And the low-level FPGA languages are things like Verilog and VHDL and SystemVerilog—and they’re, you know, they’re computer programing code, but it’s not C, it’s not Python. It’s much lower level.
And, you know, we have teams inside our companies that are very experienced at working with these languages, but it’s more than working with those languages. It’s understanding, from the architect point of view, how are these things going to get built?
I always think of the FPGA as like, when it’s just turned on, it’s almost like a building site. You kind-of have all these resources like lumber and, you know, cement and whatever. And Jeff’s…
Don’t forget my plumbing pipes!
…Jeff’s company provides all that. So you turn up…my company turns up to the building site and goes “Well, we’ve got a crap (excuse the language) a crap-load of materials. What are we going to build today?” Right? I consider myself the kind of architect of our company. So, I come in and I look at the resources, I look at what the customer wants, and I’m like, okay, they want a…they want a skyscraper. All right. So, it’s going to start looking like this.
And I would do things at the high levels that we need this block. We need this block. And then the team come in and they’re more like the…you know—the construction team. We have experts within that team. So, we have the equivalent of electricians and plumbers and scaffolding people.
And so, they start building this together. And by the end of it, we actually have a building on the site of the FPGA and I’m sorry that analogy works really badly, but (laughter) that’s kind of the way I think of it. So, you need multiple skills, right? You need an architect…you need construction workers and program managers and electricians and plumbers.
And often these people are, you know, graduate level with years of experience. And we have a whole bunch of tools that we use to make it easier. And then, ultimately, the way it makes a deployment easier is we raise that level of abstraction, and we present an API—whether it’s Shep’s API or our API or a standards-based API like Intel’s oneAPI—to the customer, because it makes their life easier.
Now, I know when we were talking the other day, we were talking about Arkville as a data mover. Can you explain the difference between a data mover and a DMA engine?
Sure. We get we get that question a lot. The DMA engine has its roots in the actual hardware that performs data copying on a computer, going back to early computer architecture: a handful of counters, the source address, the target address…software kicks it off with a count and data is moved from one place to another. That pretty much sums up what most hardware, software and system engineers think of as DMA engine.
But Arkville as a solution to data motion—from FPGA to the host memory or the other way around—includes not just the low-level movement of memory buffers, and obviously, since the memory’s on the FPGA or the memory’s in the host, they’re abstract, maybe they’re streams, maybe they’re messages. We want to present as simple an interface as DMA has: “Oh, source here, destination here, count it and go!” ..but, at this higher level.
To the hardware engineer, that means standard industry APIs for getting the data in and out of the module. On the software side, it means a standard virtual pointer to memory, so you can produce it, or you can consume it.
What goes on between those two actions of, say, producing data in the FPGA and consuming it in the host or the other way around? We wouldn’t say our customers don’t care about what goes on there, but they want that done for them. They want the business of how the motion is choreographed and how it goes on. It needs to be performant, in the sense that it has such and such a throughput, it has to have such a latency and the value that that provides is that it’s another platform. The data motion platform is provided for them and they can get on with their application.
Of course, if your needs are specialized and the pattern that we offer isn’t the right thing, as Stephen just said, “It’s an FPGA, go do whatever you need; you have that capability.”
We capitalized on the set of standards that we saw out there in AXI interfaces for example on the hardware side or DPDK as a standard Linux Foundation software API and have been successful because there’s a large enough group of people who found, “Hey, I don’t want to have to do that myself. I can buy that from Atomic Rules or I can get that board from BittWare/Molex and that’s worked for us.”
So, we have about 4 minutes left, and I was wondering if we could just touch on one last thing before we wrap it up. And if we have not gotten to your questions yet, don’t worry BittWare and team will have your questions so they can address them after the event.
But I wanted to talk about open source really quickly, and the importance of it and the open standards to the adoption of your FPGA-based solutions. So maybe any standards that are super-important, Stephen, maybe you could you could take this on?
For sure, yeah. I mean, in the computational storage space, we are standardizing what we call a command set in NVMe (NVM Express)—which hopefully most of you have heard of and is probably in most of your laptop computers right now—to talk computation as well as storage. So, if we want an API where we can push computational tasks down to an FPGA, we’ll be able to leverage this very open standard.
The advantage of that is: I no longer have to get my team to write the driver in Linux or Windows; an NVMe drive already exists. I know that every server that ships today, every desktop that ships today, supports NVMe because that’s what powers the solid-state drives that we boot our operating systems and load our games and other things from.
And so that makes my life a lot easier and it also creates an ecosystem because it’s no longer just about Eideticom. It’s about anybody who’s playing in this NVMe computational storage space. So that creates competition, which is, you know, not necessarily a great thing, but I actually think it is a great thing. More important for me, it creates an ecosystem and ecosystems drive adoption. Adoption pushes down prices which increases adoption, and you get that virtuous circle.
So, I’m a great believer in open source and open standards. We do a lot of work in things like the Linux kernel and in things like SPDK, which is the storage equivalent of what Shep said earlier (DPDK).
And again, I think that’s really important to have that collaboration within a community, to have many different companies looking at the code going, “How do we make this better? How do we make it more secure? How do we make it more efficient?”
And again, I think that just leads to better adoption. And I like that.
Everything Stephen just said—that was awesome—but I also want to add: giving back to the community in such a way that the code is vetted and becomes trusted. Sure, no one wants a proprietary solution, so putting something up on GitHub that’s available somewhere is interesting.
But you know what’s a lot more valuable? Having your code reviewed by the Linux Foundation and their various groups such that the pieces that you’re open-sourcing are trusted and vetted by the community at large. That process, which I know Eideticom does and Atomic Rules does as well, is vital to all of this because the value of these open source codes is magnified when the trust circle includes the giants in the industry.
Well, guys, we’re coming to the end of our time. I wish we had…we had so many great questions in here. Everyone, thank you for joining us on today’s live chat. Thank you to our sponsors, Mouser Electronics, BittWare and Molex. And thank you to our amazing panelists for joining us.
Yes, thank you so much.
Have a great day, everybody.
White Paper Introduction to BittWare’s SmartNIC Shell for Network Packet Processing Overview SmartNIC Shell is a complete working NIC that is implemented on a BittWare

White Paper Synthetic Traffic Generator Reference Design Overview Synthetic traffic generators enable lab testing of FPGA designs with network ports. There are other applications, but
PCIe FPGA Card XUP-VVH UltraScale+ FPGA PCIe Board with Integrated HBM2 Memory 4x 100GbE Network Ports and VU37P FPGA Need a Price Quote? Jump to

BittWare SDK Software Development Kit for BittWare FPGA Hardware Overview BittWare’s SDK is a cross-platform collection of drivers, libraries, modules, and utilities that aid in