
Homomorphic Encryption Acceleration
Article Homomorphic Encryption Acceleration FPGA acceleration enables this unique solution that allows compute on encrypted data without decrypting or sharing keys Traditional Encryption Limits Encrypting


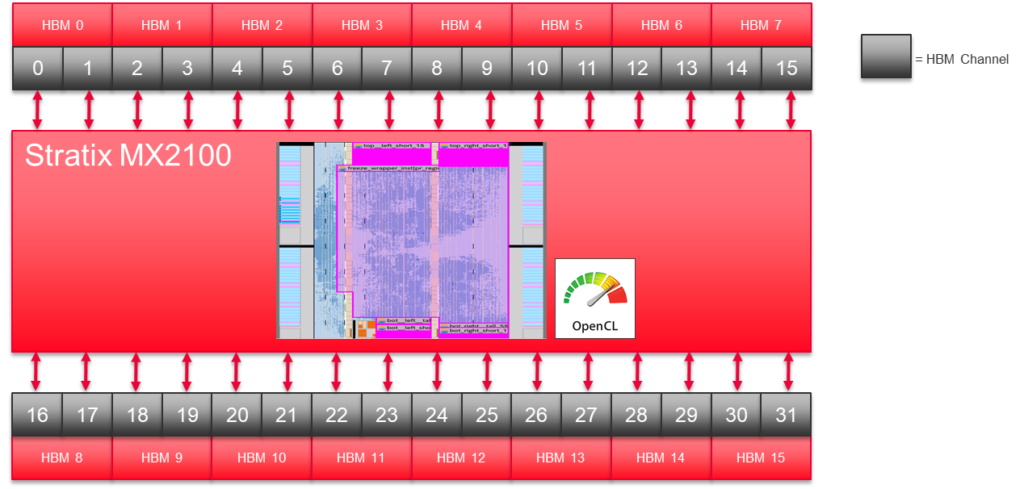 The Stratix 10 MX has 32 pseudo HBM2 memory channels. Our 2D FFT implementation uses half those channels.
The Stratix 10 MX has 32 pseudo HBM2 memory channels. Our 2D FFT implementation uses half those channels.
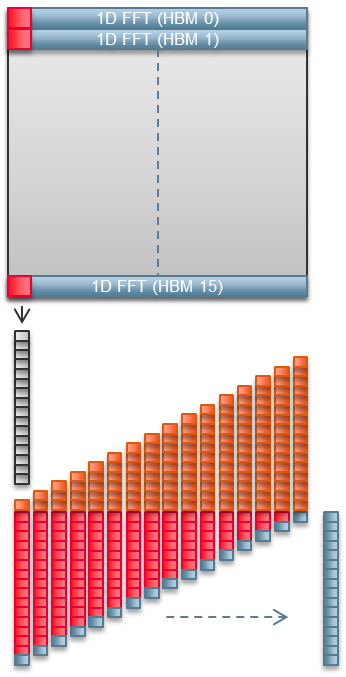
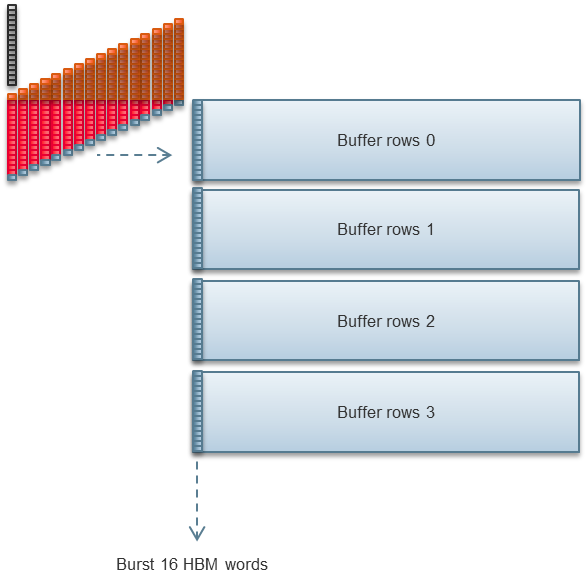
Article Homomorphic Encryption Acceleration FPGA acceleration enables this unique solution that allows compute on encrypted data without decrypting or sharing keys Traditional Encryption Limits Encrypting

BittWare On-Demand Webinar Enterprise-class FPGA Servers: The TeraBox Approach FPGA-based cards are maturing into critical devices for data centers and edge computing. However, there’s a
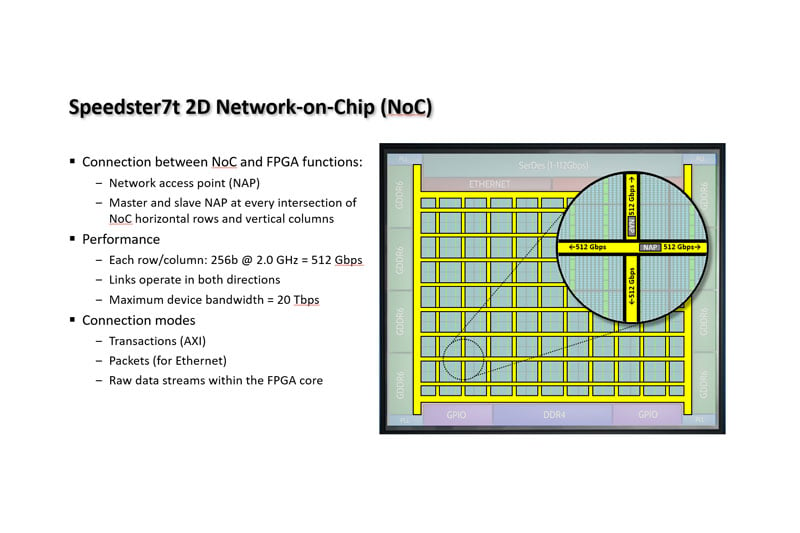
BittWare Webinar Introducing VectorPath S7t-VG6 Accelerator Card Now available on demand: In this webinar, Achronix® and Bittware will discuss the growing trends of using PCIe

High-speed networking can make timestamping a challenge. Learn about possible solutions including card timing kits and the Atomic Rules IP TimeServo.