Apache Kafkaは、新たなユニバーサル・ストリーミング・データ・パイプラインの中核です。Kafkaは、LinkedIn、Netflix、Uber、ING、そしてフォーチュン500の3分の1以上で使用され、さらに増え続けているストリーミング・プラットフォームとして、多くの有名企業が採用しています。LinkedInでは、1日あたり約2兆のメッセージがKafkaを通過している。TechRepublic.comによると、旅行会社上位10社のうち6社、グローバル銀行上位10社のうち7社、保険会社上位10社のうち8社、通信会社上位10社のうち9社が、ストリーミングデータ管理の中心的プラットフォームとしてKafkaを採用している。2017年のニューヨークKafkaサミットで、Confluentはフォーチュン500社の3分の1以上がKafkaを導入していると報告した。
Kafkaには、プロデューサー、ブローカー、コンシューマーという3つの必須コンポーネントがあります。プロデューサーはブローカー上のトピックにデータを公開し、コンシューマーはトピックにサブスクライブします。図1は、基本的なKafkaのシステムです。
Kafkaアーキテクチャの多くの利点の1つは、プロデューサーとコンシューマーの切り離しです。プロデューサーとコンシューマーのデータレートが大きく異なっていても、お互いに影響を与えることはありません。Kafkaのもう1つの重要な利点は、そのサイズの小ささです。Kafkaのクラスタは、わずか9万行のコードで、Sparkノードが必要なSpark Streamingよりもはるかに小さなハードウェア要件で実装することができる。
図1 - Kafkaの基本システム
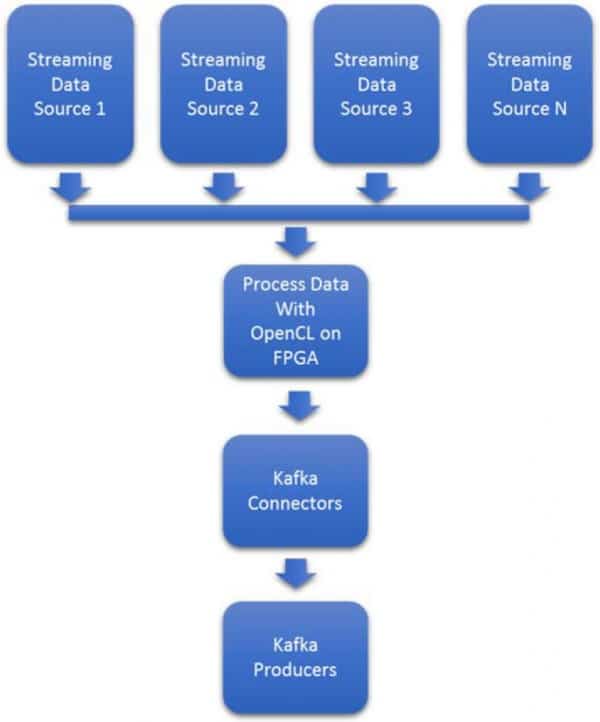
ビッグデータシステムへのデータ取り込みは、単純なものから複雑なものまで様々である。図2において、データソース1はネットワークトラフィックのパケットキャプチャかもしれない。しかし、データソース2は、人工衛星のコンステレーションから得られる複雑な地理空間画像であり、データソース3は、テキサス州西部の風車農場における産業用IoTメンテナンスデータである。
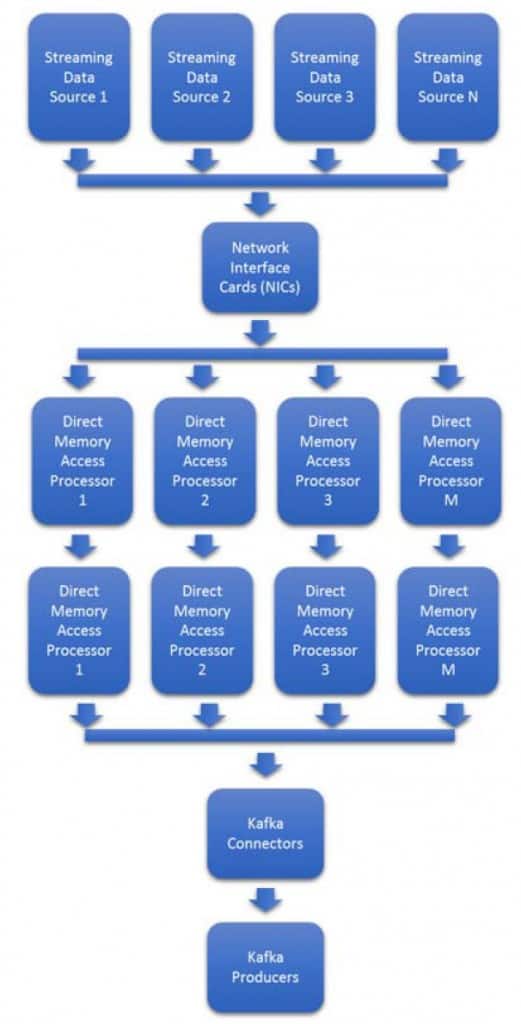
データフォーマットやデータレートが多様であるため、この問題を拡張することは困難です。トラフィックの急増や新しいフォーマットにリアルタイムで対応するためには、NICやプロセッサを追加で用意する必要があり、コストがかかる場合が多い。図3は、多くのKafkaクラスターで使用されている、プロセッサベースの典型的なアーキテクチャを示します。
図2:インテルFPGAによるストリーミングデータインジェストアクセラレーション
データレートの変動は、図3のシステムの計画を難しくしている。多くの場合、最大帯域幅を見積もり、その上でプロビジョニングしなければならない。50%以上の余剰プロセッサとNICは、データレートの上昇を待ってアイドル状態になる。
Intel FPGA ベースのソリューションに移行しても、最大帯域幅は同じと推定されますが、図 4 の簡略化されたシステムでは、アイドル時の電力が大幅に削減され、全体として必要なフットプリントもかなり小さくなります。また、図2のシステムでは、プロセッサベースのシステムで必要なフロー制御やロードバランス管理も不要になります。これは、Intel FPGAベースのアプローチがデータレートやデータ形式に関係なく決定論的であるためです。
インテルFPGAは、銅線、光ファイバー、光ケーブルに直接接続するストリーミング並列アクセラレータです。従来のGPUやCPUとは異なり、Intel FPGAは、ネットワーク・インターフェイス・カード(NIC)を必要とせず、あらゆるフォーマットのデータをワイヤからメモリまでナノ秒単位で移動することができます。
このアクセラレーション のインジェストにより、Kafka プロデューサーへのデータインジェストのレイテンシを 40 倍に低減することができます。また、機械学習、画像認識、パターンマッチング、フィルタリング、圧縮、暗号化など、流入するデータを同時にリアルタイムで処理するオプションが用意されています。そのため、インジェストされたデータは、データ取得とデータ分析にかかる時間を短縮するために、加速され、強化されることができます。
図3 : 典型的なインジェスト経路
KafkaプロデューサーへのFPGAインジェストの最も基本的なユースケースを図4に示しています。この最も基本的なユースケースでも、FPGAは極端に変動するレートでも低レイテンシーと決定性を提供します。OpenCLでデータを抽出・変換できるため、このユースケースは10~100種類のデータを扱うことができます。
図4 インライン、低レイテンシ、決定論的、抽出と変換
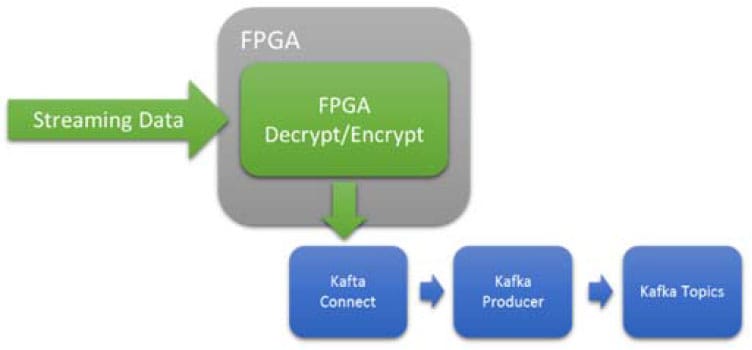
暗号化はプロセッサ・サイクルが非常に高価ですが、インテルFPGAではよく理解できます。FPGAは、データレートに依存することなく、低レイテンシーで確定的な結果を提供します。プロセッサの場合、可変のデータレートはプロセッサのリソースをあふれさせ、ボトルネックやパケットのドロップを引き起こす可能性があります。
図5 インライン、低レイテンシ、決定論的、暗号化または復号化
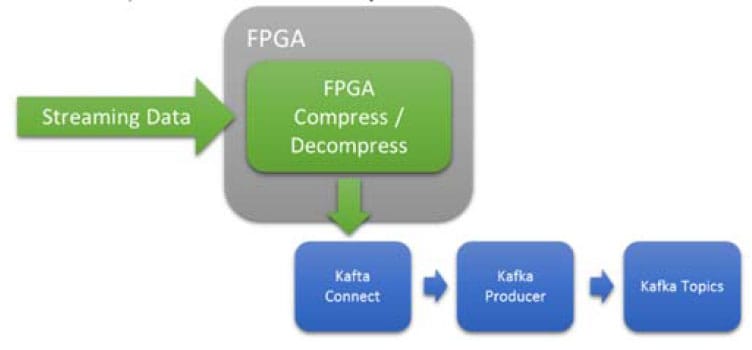
図6 インライン、低レイテンシ、決定論的な圧縮または伸長
FPGAは、圧縮・解凍の効率が非常に高いです。この使用例では、Kafkaシステムに渡す前のデータの圧縮・解凍にFPGAが使用されています。
シャノンの法則は、ストリームが暗号化されているかどうかを判断するために、より多くのストリーミングのユースケースに適用されています。シャノンの法則は、パケットのエントロピーを計算し、ランダム性と構造化されたバイトを比較するものです。暗号化されたバイトの多くは、構造化されたデータに似ていますが、すべてではありません。図7は、Kafkaトピックに公開する前に、エントロピーを計算し、復号化を試み、そして解凍する可能性のあるフローを示します。暗号化されたストリームと復号化されたストリームの比較は、金融や医療などの個人を特定できる情報など、多くの産業で応用が可能である。
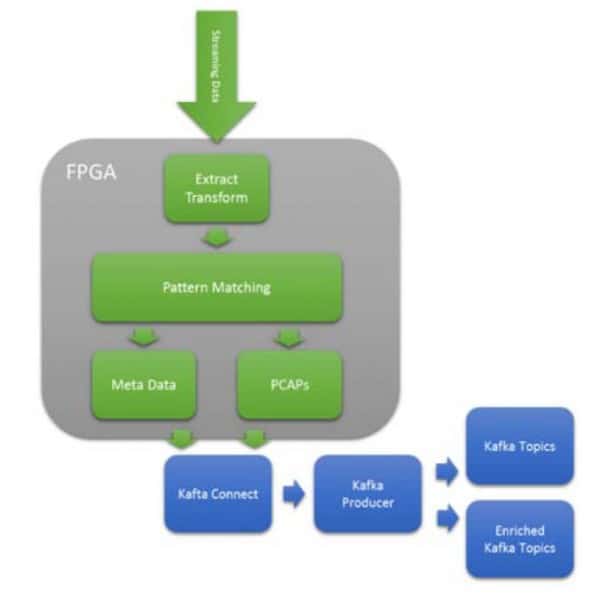
図8 サイバーアナリティクスのためのPCAPのエンリッチド・トピック・ルーティング
Kafkaの柔軟なトピックアーキテクチャにより、取り込まれたデータを多くのトピックに配置することができます。この柔軟性は、機械学習とパターンマッチングを使用して、受信データをルーティング/スイッチングできることを意味します。上の図9は、生のネットワークパケットをキャプチャしているところです(PCAPS)。パケットがキャプチャされると、PCRE式を使用した複雑なパターン・マッチングにより、適切なトピックにルーティングすることができます。これにより、Kafkaコンシューマはエンリッチされたトピックをサブスクライブし、クリーニングステージをバイパスすることができます。DOE Sandia & Lewis Rhodes Labsが発表した研究によると、多くのサイバー分析アプリケーションにおいて、この処理はワットあたりのサイバーオペレーションを1000倍向上させることを実現しています。
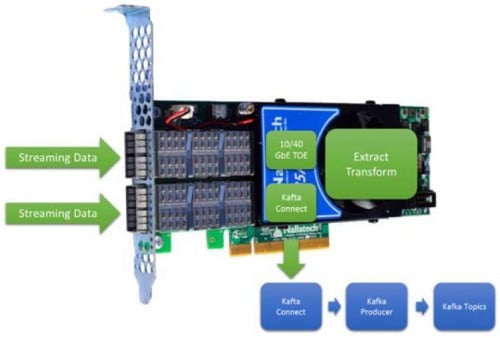
BittWare 385Aは、それぞれ最大40Gbe/secをサポートする2つのネットワークポートを提供します。このNICサイズのカードは、既存のNIC/CPUの組み合わせを置き換えることができ、既存のKafkaネットワークを大幅に高速化し、電力を削減します。
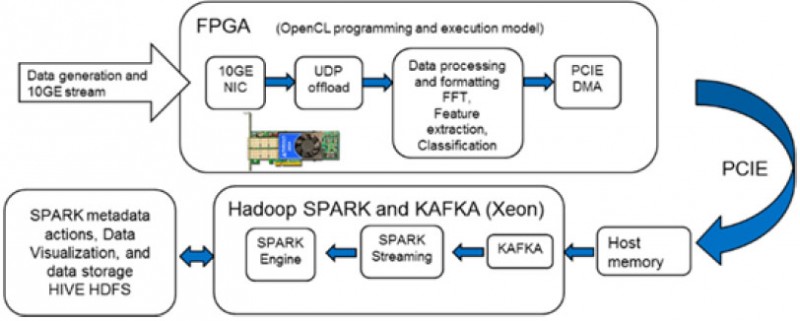
これはClouderaとIntelによって検証され、KafkaからSparkへのストリーミングを高速化し、同時にFPGA上でデータのエンリッチメントを実行します(図9)。
図9 385Aを使ったエンリッチデータ
上記のデモでは、入力データストリームとしてエンジンノイズのシグネチャを選択しました。これらのデータは、UDPオフロードエンジンを介して取り込まれ、カードのOpenCL環境に配置されます。カード上で動作するOpenCLコードは、入力されたデータストリームをリアルタイムにフォーマットします。そして、FFT、特徴抽出を行い、既知のエンジンのシグネチャーとの比較に基づいて、信号を「正常」または「異常」に分類します。この余分なデータとエンジン信号のFFTは、さらなる処理のためにKafkaにDMAされます。
この例では、OpenCLで生成されたライブラリが、入力されるストリーミングデータに適用できる柔軟性があることも強調されています。これにより、エンドユーザーは、データエンリッチメントやデータフィルタリングなど、非常にアプリケーションに特化した形式を含めることができる自由度を得ることができます。
BittWare 520Nは、4つのネットワークポートにより、10/25/40/100Gzで動作する一連のシリアルI/Oプロトコルをサポートします。最大400Gbe/secのスループットで、Kafkaフレームワークにオフロードする前に大量のデータをリッチ化することが可能です。
520Nは、圧倒的なパフォーマンスを提供する強力なStratix 10 FPGAを搭載しています。高スループット、大容量演算、OpenCLによるプログラマビリティの組み合わせにより、ストリーミングデータに対する複雑なデータエンリッチメントを1台のデバイスで実行することが可能になっています。
図10 520Nを用いたエンリッチデータ
BittWare アクセラレーション BittWare は、 10 と 10 FPGA を使って Apache Kafka を高速化するための製品を現在および計画中です。お客様のニーズと加速ソリューションの開発について、ぜひArria Stratix 弊社にご相談ください。
FPGAストレージの概要アクセラレーション
使用したカードについて詳しくはこちら
リソースに戻る