
來自EdgeCortix的動態神經加速器
返回IP & Solutions Dynamic Neural Accelerator ML Framework EdgeCortix Dynamic Neural Accelerator (DNA),是用於深度學習推理的靈活 IP 內核


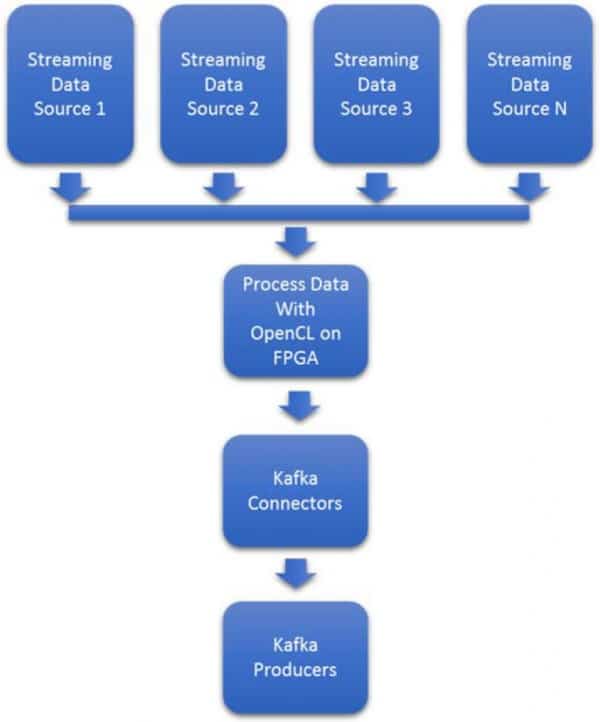
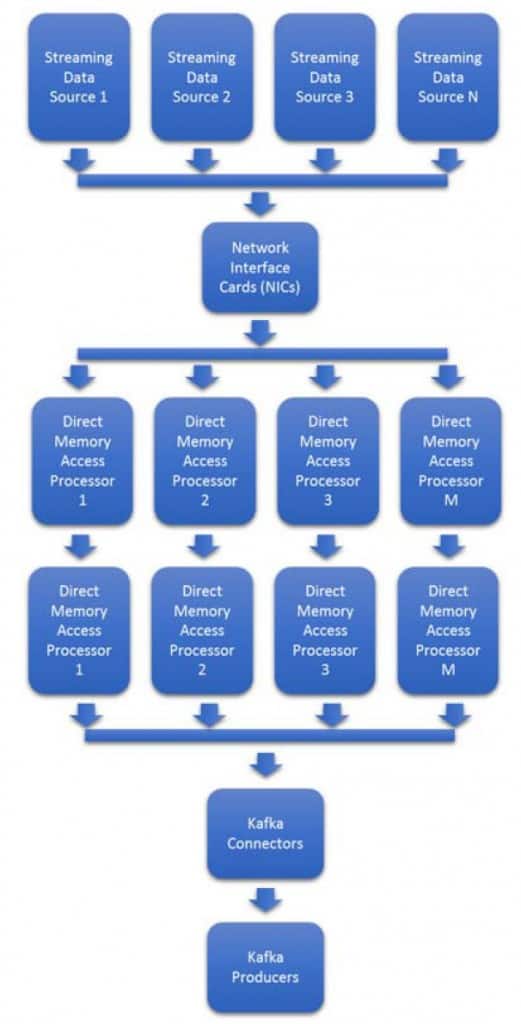
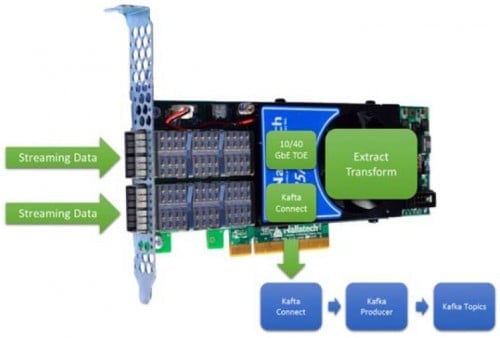
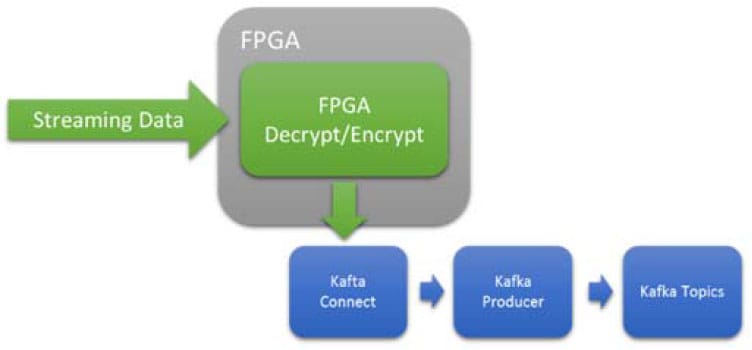
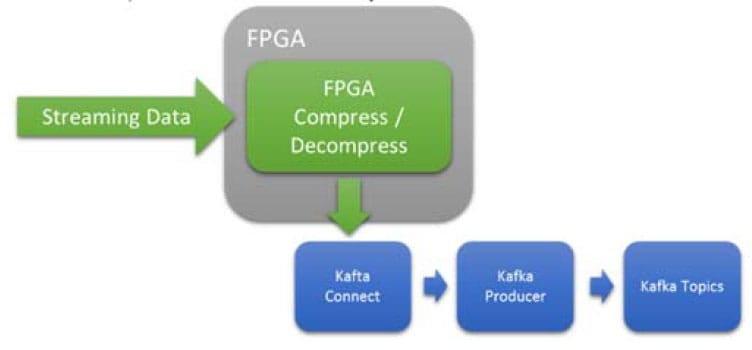
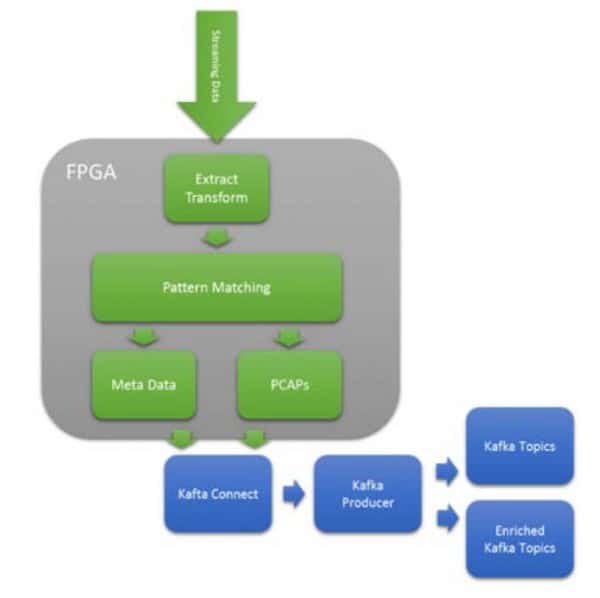
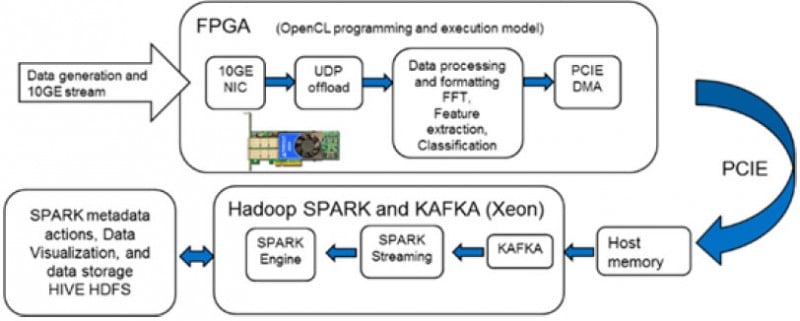
返回IP & Solutions Dynamic Neural Accelerator ML Framework EdgeCortix Dynamic Neural Accelerator (DNA),是用於深度學習推理的靈活 IP 內核
採用PCIe Gen 4 FPGA計算存儲處理器(CSP)的新型IA-220-U2 Gen 4 PCIe NVMe Eideticom NoLoad BittWare的IA-220-U2加速NVMe快閃記憶體固態硬碟

返回IP和解決方案 用於10/25/50/100GbE原子規則的UDP卸載引擎UOE IP內核 UDP 卸載引擎 (UOE) 是一個 UDP FPGA IP

通過我們在採用 HBM2 的 520N-MX 卡上的 2D FFT 演示,探索使用 oneAPI。請務必在頁面底部請求代碼下載!