Article
世界上不斷增加的連通性正在產生越來越多的數據。如果應用得當,機器學習可以學習提取這些數據中的模式和交互。FPGA 技術可以提供説明。
機器學習是人工智慧 (AI) 的一個分支,其中演算法和數據用於創建可以執行特定任務的系統。隨著處理更多數據(稱為訓練),系統的準確性會慢慢提高。一旦足夠準確,該系統就可以被認為是經過訓練的,然後部署到其他環境中。在這裡,使用相同的學習演算法來推斷結果的統計概率。這稱為推理。
神經網路構成了大多數機器學習任務的基礎。它們由多個計算層組成,其交互基於訓練期間學習的係數。 本白皮書重點介紹神經網路在FPGA器件上的推理,說明它們的優勢和劣勢。
瞭解如何使用 BittWare 的 FPGA 加速器產品加速捲積神經網路
Learn how we used OpenCL to adapt the YOLOv3 machine learning framework to one of our FPGA cards
神經網路的核心是大量的乘法累加計算。這些計算類比了數千個神經元的相互作用,產生了發生某事的統計可能性。對於圖像識別,這是網路正在觀察特定物件的置信因數。這當然可能是錯誤的。例如,人類經常在無生命的物體中看到人臉!因此,任何系統都需要對不正確的結果有一定的容忍度。這些結果的統計性質提供了改變計算動態範圍的機會,只要最終答案保持在應用程式容差定義的令人滿意的精度水準內。因此,推理提供了對所使用的數據類型進行創造性的機會。
數據寬度通常可以減小到8位整數,在某些情況下可以減小到一位。FPGA 可以配置為處理幾乎任何大小的數據類型,計算利用率損失很小或沒有損失。
在神經網路推理方面,ASIC、CPU、GPU 和 FPGA 各有優缺點。定製晶片 (ASIC) 提供最高的性能和最低的成本,但僅適用於目標演算法 - 沒有靈活性。 相比之下,CPU 提供最大的程式設計靈活性,但計算輸送量較低。GPU 性能通常遠高於 CPU,並且在使用大批號(即並行處理許多查詢)時會進一步提高。在延遲關鍵型實時系統中,並非總是能夠批量輸入數據。這是FPGA有些獨特的一個領域,允許神經網路針對單個查詢進行優化,同時仍能實現高水準的計算資源利用率。當 ASIC 不存在時,這使得 FPGA 成為 延遲關鍵型神經網路處理的理想選擇。
圖 1 顯示了 FPGA 的典型加速器卸載配置。在這裡,係數數據被更新到附加的深度DDR或HBM記憶體中,並在處理從主機傳輸的數據時由AI推理引擎訪問。對於高批量數,GPU 的性能通常優於 FPGA,但是如果小批量或低延遲是系統的首要限制,那麼 FPGA 提供了一個有吸引力的替代方案。
圖 1:FPGA 推理卸載
FPGA 特別擅長的地方在於將 AI 推理與其他實時處理要求相結合。 FPGA 的可重新配置 IO 可以針對不同的連接問題進行定製,從高速乙太網到模擬感測器數據。這使得FPGA在不存在ASIC時在邊緣執行複雜推理方面獨樹一幟。設備還可以使用相同的 IO 以最適合應用的配置將多個 FPGA 連接在一起,或者適合現有伺服器連接。連接可以定製或遵循乙太網等標準。
圖 2:在數據管道行中使用推理的示例
對於內聯處理,神經網路只需要能夠以線速處理數據。在這種情況下,FPGA將僅使用必要的資源來跟上所需的輸送量,而不會使用更多資源。這樣可以節省功耗,併為加密等其他任務留出額外的FPGA空間。
在數據隱私很重要的領域,機器學習有很大的機會。例如,醫療診斷可以從雲加速中受益。但是,患者數據是保密的,並且跨多個網站進行分類。網站之間傳遞的任何數據都必須至少加密。FPGA 可以解密、執行 AI 處理和加密,所有這些都以非常低的延遲進行。至關重要的是,任何解密的數據都不會超出FPGA的範圍。
圖 3:使用 FPGA 在雲中使用解密和加密邏輯執行推理
最終,同態加密將是處理此類敏感數據的理想方法,FPGA對此顯示出前景。
有許多不同類型的神經網路。最常見的三種是 卷積 神經網路(CNN), 遞歸神經網路 (RNN)和最近的 基於變壓器的網路 ,如谷歌的BERT。 CNN主要用於圖像識別應用,本質上是矩陣處理問題。RNN 和 BERT 經常用於語音辨識等問題,並且效率低於 GPU 等 SIMD 處理器上的 CNN 模型。
FPGA 邏輯可以重新配置,以最好地適應神經網路的處理需求,而不是圍繞硬體(例如在 GPU 上)擬合演算法。這對於低批數尤其重要,因為增加批大小通常是處理對 GPU 具有尷尬依賴關係的網路的解決方案。
Resnet是一種經常被引用的神經網路,由許多捲積層組成。但是,這些層中的大多數僅使用單個單元格 (1×1) 的範本,這是一個常見的要求。Resnet 的最後一層需要非常高的權重與數據計算的比率,因為小範本尺寸減少了可能的數據重用量。如果嘗試實現盡可能低的延遲,即批量大小為 1,則會加劇這種情況。平衡計算與記憶體頻寬對於實現最佳性能至關重要。幸運的是,FPGA支援廣泛的外部記憶體,包括DDR、HBM、GDDR和內部SRAM記憶體,如果選擇了正確的器件,則可以為給定的工作負載選擇完美的頻寬組合來進行計算。
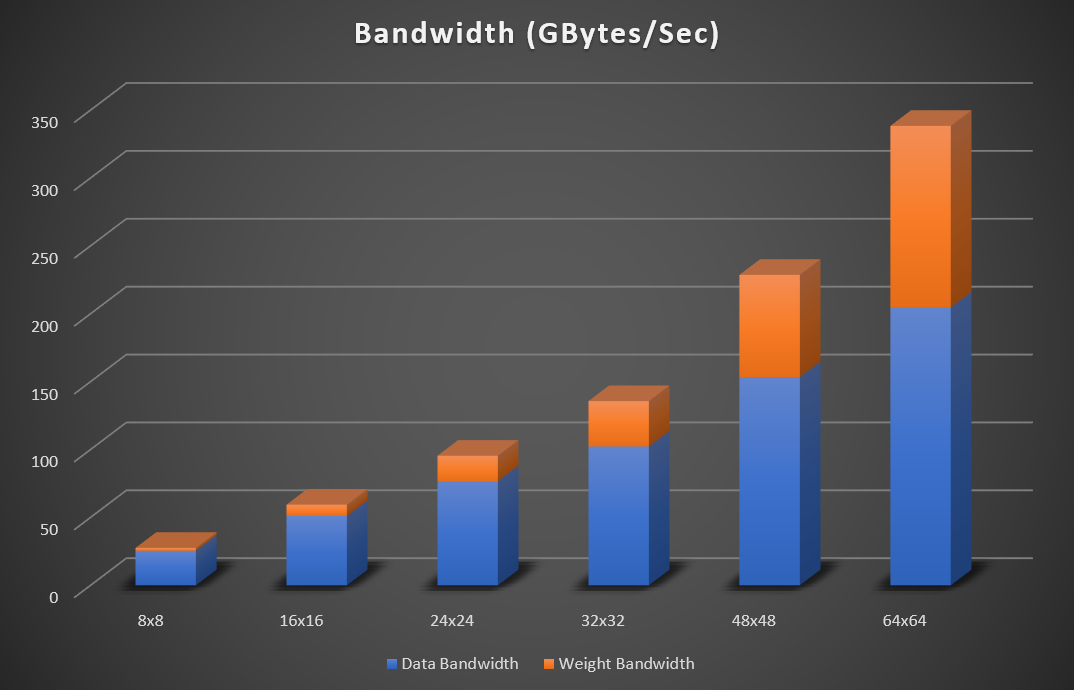
圖 4:增加矩陣大小的 Resnet (224×224) 峰值頻寬要求(32 位浮點數據)
圖 4 說明瞭 Resnet 50 的 8×8、16×16、24×24、32×32、48×48 和 64×64 矩陣大小不斷增加的峰值頻寬要求。帶寬假定重量,輸入和輸出數據被讀取並寫入外部記憶體。片上SRAM記憶體用於存儲臨時累積。如果網路適合FPGA記憶體,則無需始終如一地在記憶體中讀寫特徵數據。在這種情況下,外部數據頻寬可以忽略不計。對於 int8 實現,所需的頻寬數位可以除以 4。
Bittware與供應商無關,支援英特爾,Xilinx和Achronix FPGA技術。所有 FPGA 供應商在低延遲和低批號實現方面都表現良好,但每個元件在可配置邏輯的應用方面都存在細微差異。
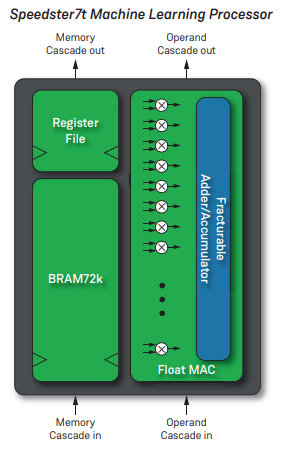
Achronix的最新FPGA還具有旨在加速神經網路處理的IP。每個機器學習處理器 (MLP) 一個設備處理 32 個乘法累加器 (MAC),支援 4 到 24 位計算。支援非標準浮點格式,例如 Bfloat16。Achronix MPL 和英特爾張量元件之間的關鍵區別是緊密耦合的 SRAM 記憶體,旨在確保與去耦 SRAM 相比更高的時鐘速度。
Bittware S7t-VG6採用Speedster7t,具有2,560 MLPS,總理論峰值性能為61 TOps(int8或bfloat16)。
圖5:阿克羅尼克斯MLP 3
圖6:BittWare S7t-VG6
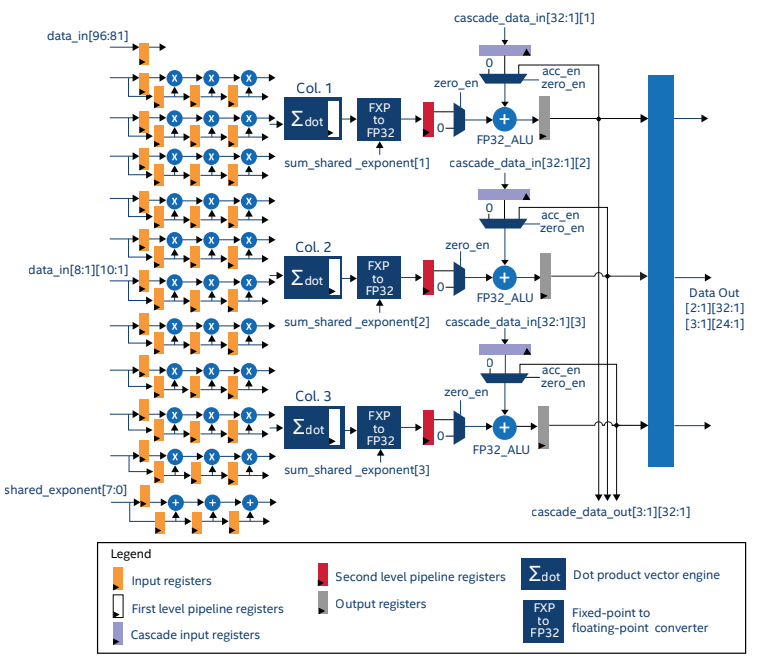
英特爾 Stratix 10 NX 是英特爾首款具有專用張量算術模組的 FPGA。張量IP經過優化,可對10×3的數據塊執行張量運算(圖 5)。該IP可以配置為使用int4、int8、塊 FP12 和塊 FP16 數據類型工作,充分利用。
圖 7:層 10 張量 IP1
Startix10 NX器件的理論峰值輸送量如表1所示。
Stratix 10 NX還具有HBM2記憶體,可提供高達512 GB / s的總頻寬,確保有足夠的頻寬來滿足所有可用的處理。
表 1:第 10 層理論峰值輸送量
Stratix 10 NX是 Bittware 520NX 加速卡的核心。該卡具有高達 600 Gbps 的板對板頻寬,用於將多個卡連接在一起或與感測器數據通信。
英特爾敏捷克斯系列沒有張量 DSP 元件;但是,其DSP已從Stratix 10改進,以支援更多數據類型,從而增加了較低精度的算術輸送量。英特爾敏捷 M 系列的理論 Resnet-50 性能為 88 INT TOPS。阿拉伯數位
圖8:BittWare 520NX
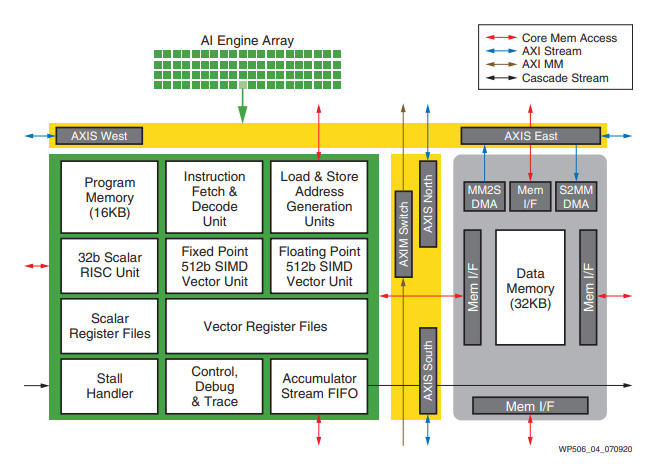
Xilinx Versal 器件具有獨立的 AI 引擎,未整合到 FPGA 可程式設計邏輯中。versal AI 引擎與 FPGA 緊密耦合,但獨立於 FPGA 的其餘部分運行。數據使用片上網路 (NOC) 在 AI 引擎和 FPGA 邏輯之間傳遞。
圖 9:Versal AI 引擎
BittWare目前有一個ACAP早期訪問計劃,其概念包括採用AMD Xilinx®的7nm Versal Premium ACAP器件的雙寬PCIe Gen5加速器卡。 如需瞭解更多資訊,請訪問我們的 Versal 資訊頁面。
AI工程師使用許多不同的高級工具來描述神經網路,例如PyTorch,TensorFlow,Caffe等。幸運的是,有一些API可以將AI代碼編譯為FPGA,允許工程師繼續使用現有的工具流。
Bittware擁有具有此功能的合作夥伴公司:
EdgeCortix 動態神經加速器 (DNA) 是一種靈活的 IP 內核,用於深度學習推理,在採用 Agilex FPGA 的 BittWare 卡上具有高計算能力、超低延遲和可擴展的推理引擎。
Megh Computing 的 VAS Suite 是一款智慧視頻分析解決方案,適用於需要具有企業級性能的可操作見解的安全和系統集成商,同時管理總體擁有成本考慮因素。
現代 FPGA 是非常強大的 AI 處理器,擅長低延遲、小批量大小推理。當與其他處理要求相結合時,它們提供了一個強大的平臺,可以在其上創建具有獨特功能的AI系統。根據系統的需求,一個FPGA供應商可能比另一個供應商更合適。BittWare隨時準備幫助客戶根據功耗、處理和IO要求選擇合適的FPGA系統。
瞭解有關我們的 FPGA 加速卡的更多資訊→