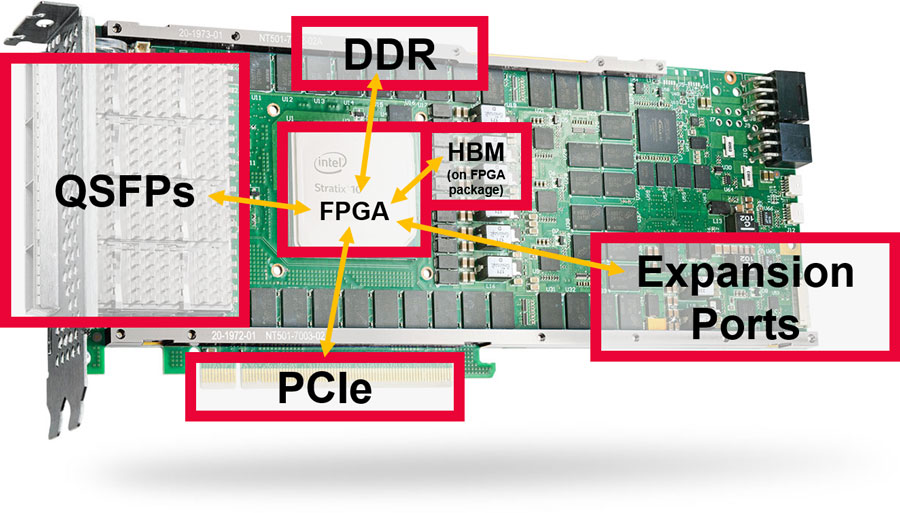
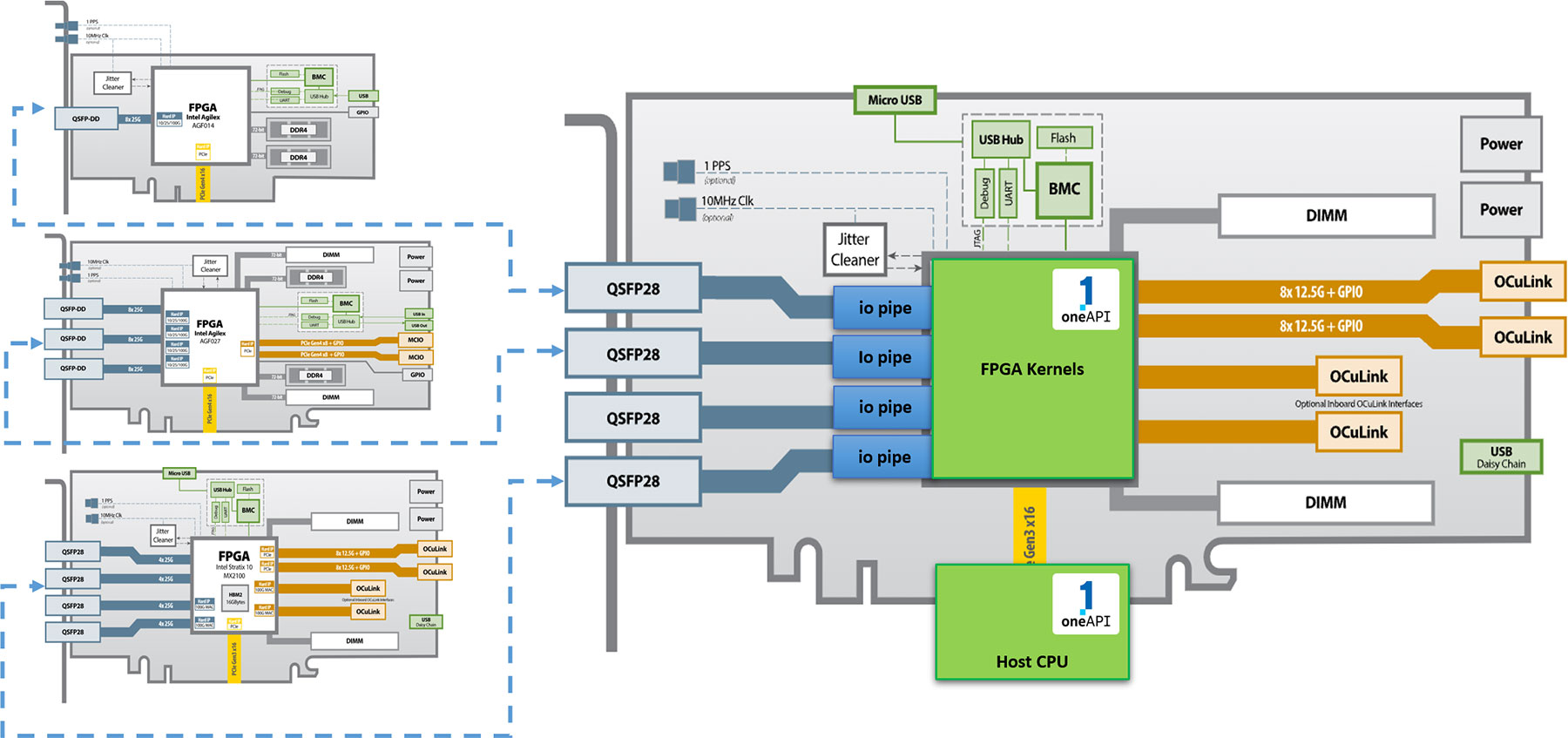
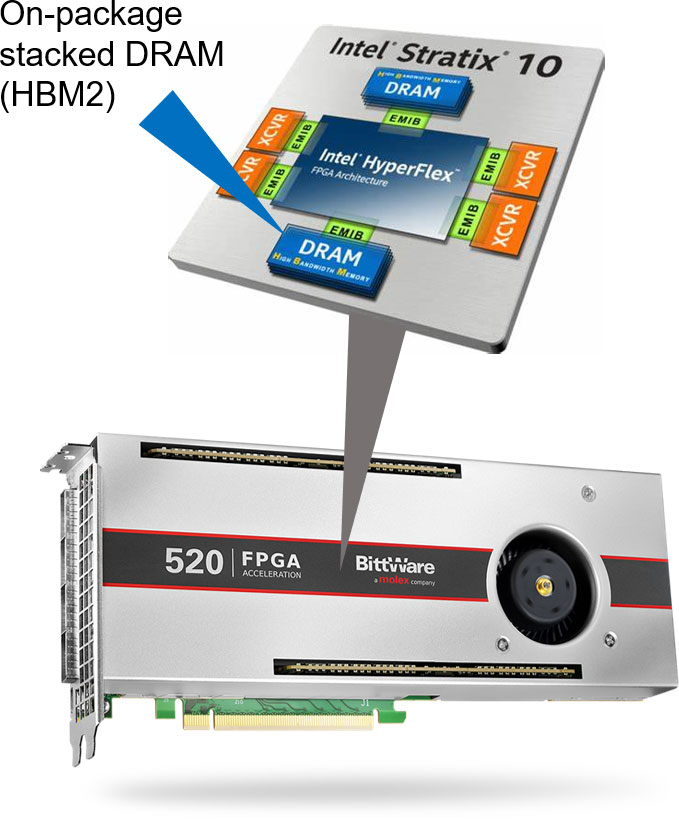
大型 FPGA,如英特爾的 Stratx 10 和 Agilex 系列,具有廣泛的 I/O 介面。BittWare通過提供QSFP,PCIe,卡上DDR4和GDDR6記憶體和擴展埠等功能來提供使用這些卡。我們也有採用封裝上HBM2的FPGA的卡。
訪問所有這些介面並不簡單,尤其是在需要在多個內核之間共用資源的情況下。FPGA 除了基本記憶體控制器外,沒有內置緩存或仲裁邏輯 — 仲裁是用戶的責任。
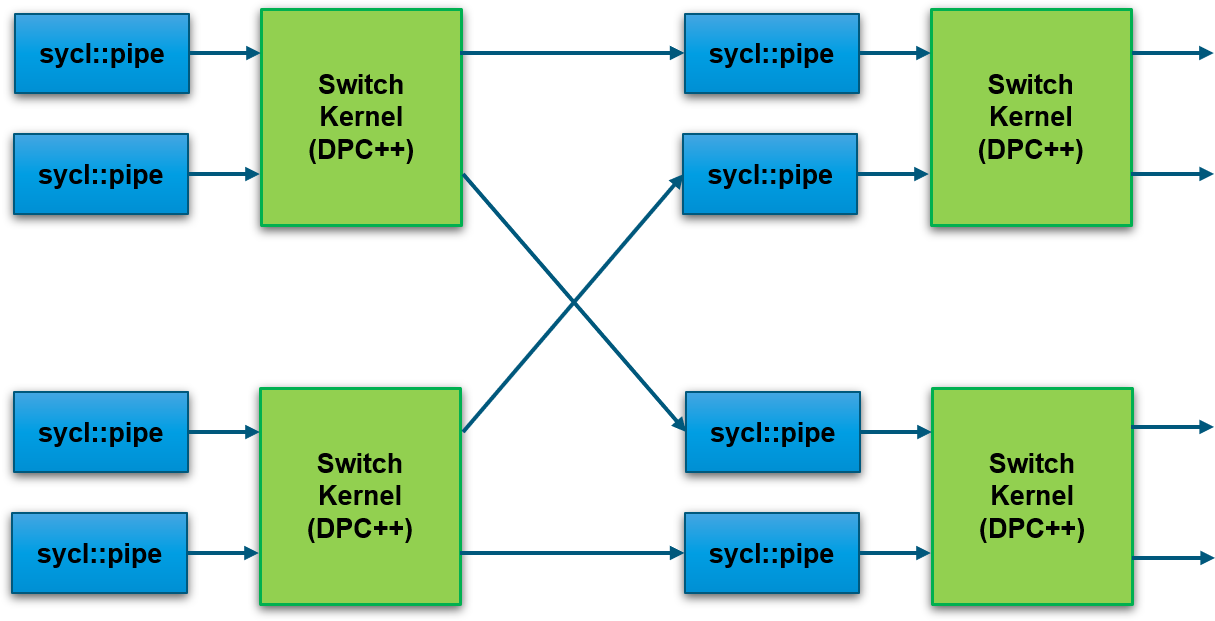
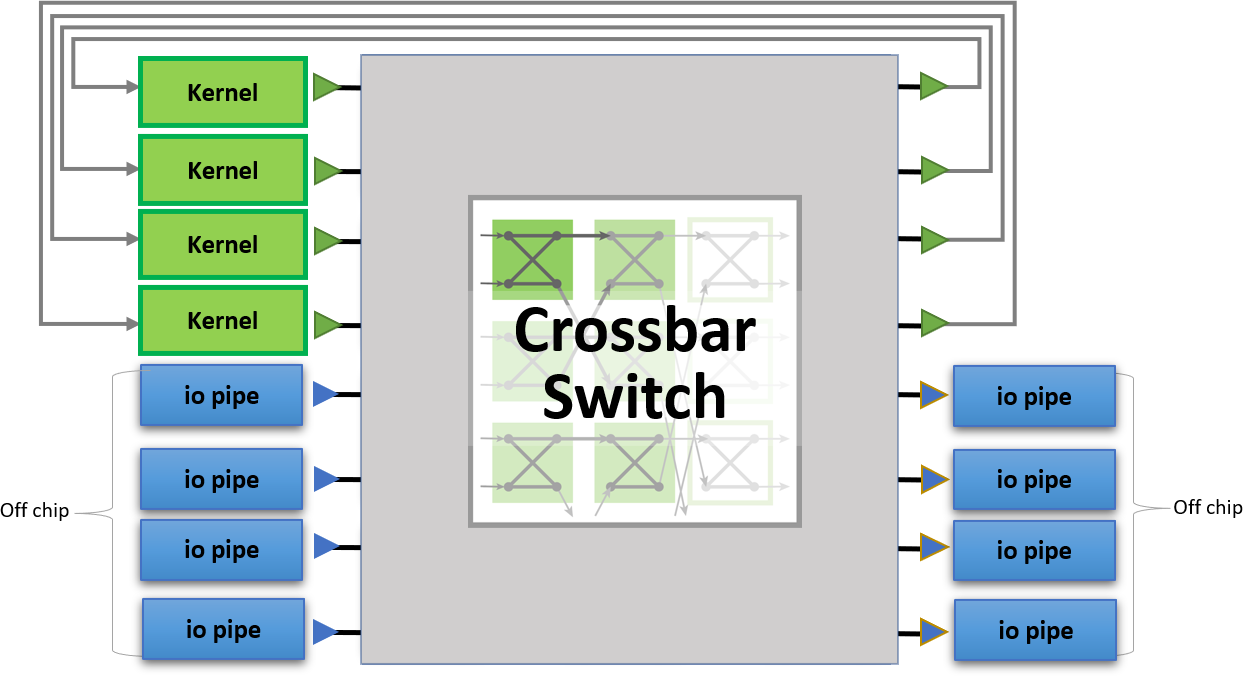
在多個內核和多個介面之間共用連接的一種解決方案是交叉開關。當然,這可以使用FPGA本地程式設計進行創建。但是,如果我們使用像 oneAPI 這樣的高級程式設計語言,我們可以輕鬆地根據所需的連接數量和介面寬度對其進行優化以盡可能高效。
BittWare Butterfly Crossbar Switch是在我們的 520N-MX卡上開發的,該卡具有HBM2記憶體和多個網路埠。
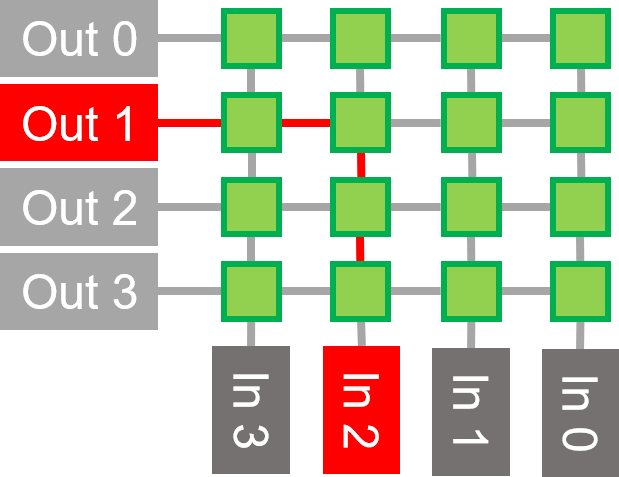
橫杆是排列在矩陣中的開關的集合。它 減少了 一組輸入/輸出之間所需的 連接 。
矩陣等於輸入數乘以輸出數。
矩陣大小為 N x log2(N) / 2,其中 N 是輸入數。
我們之所以選擇 Butterfly ,是因為它使用的 FPGA 資源更少。但是,在某些情況下,它可能會降低輸送量。
更多詳情:
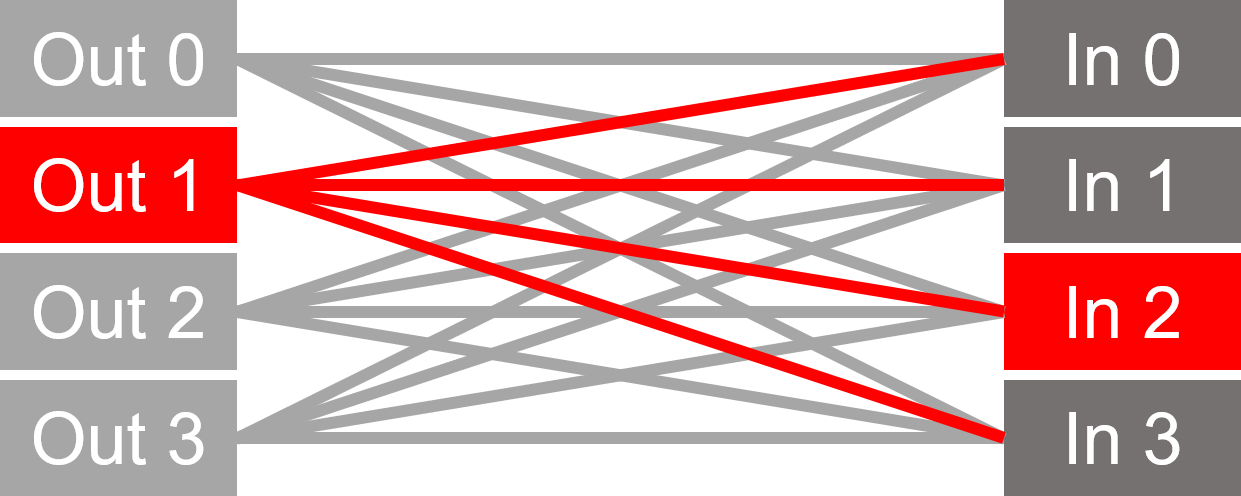
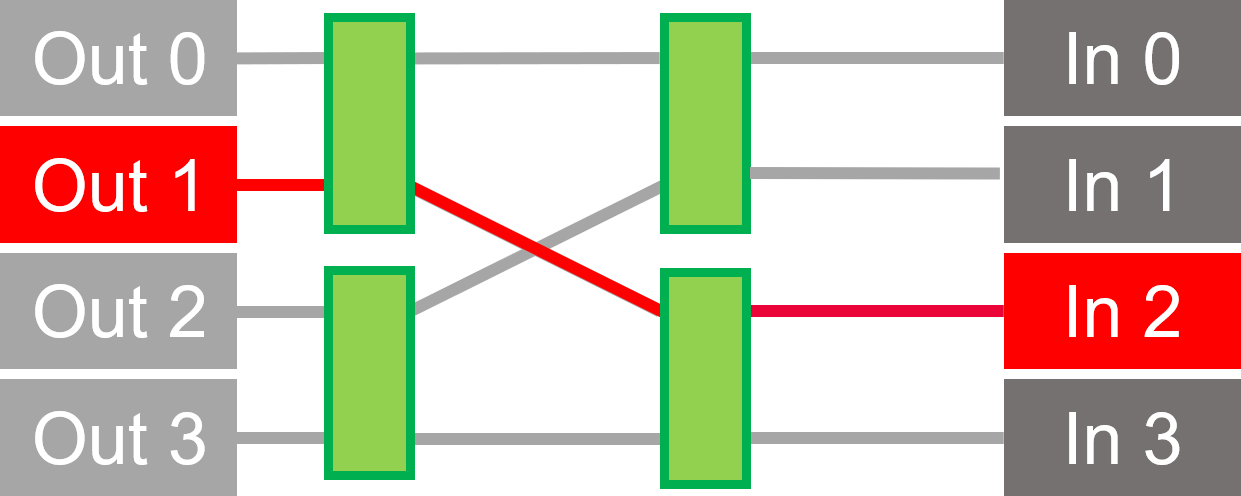
按兩下圖像以動畫顯示埠路由 0-2 和 2-3 上的範例衝突。
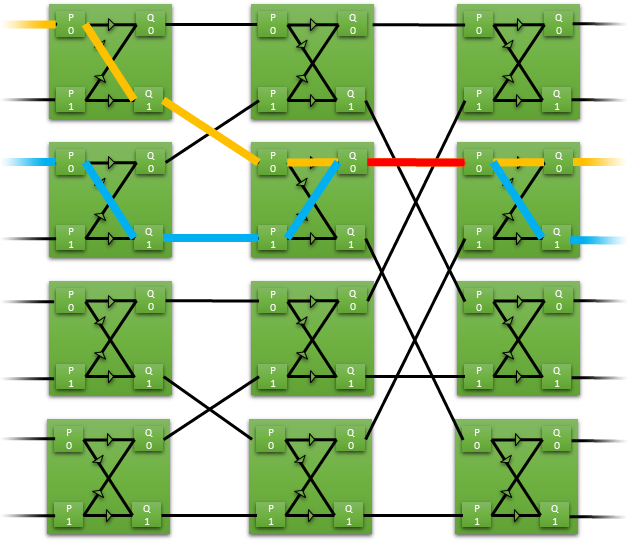
在這個蝶形橫桿的例子中,8個輸入僅使用12個開關就路由到8個輸出。每個開關有兩個輸入和兩個輸出。數據直接路由或切換到相反的路由。
如果只切換一條路徑,則輸出端可能會出現衝突,交換機必須仲裁誰有權訪問該路徑。仲裁預設使用簡單的乒乓球方案,但如果需要,可以輕鬆實施更複雜的方案。
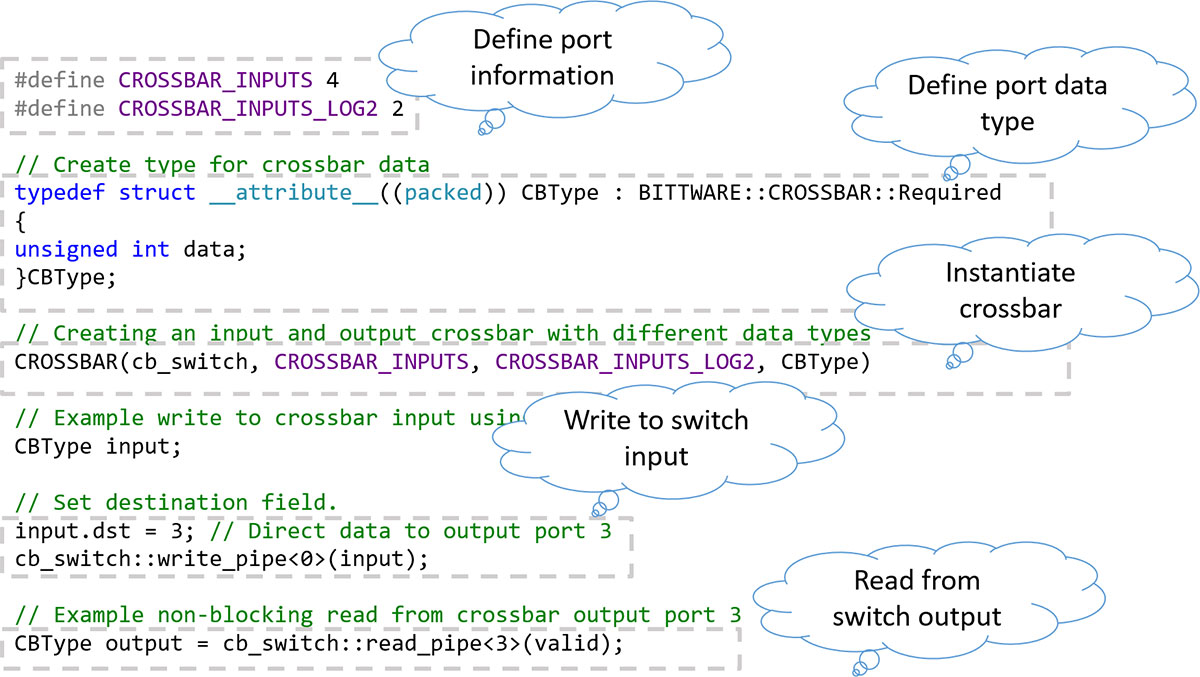
通過使用高級語言 (DPC++),可以針對特定應用要求定製交叉開關,例如:
這允許針對資源優化設計。通過消除對始終處於活動狀態的內置通用開關的需求,將功率保持在最低水準。
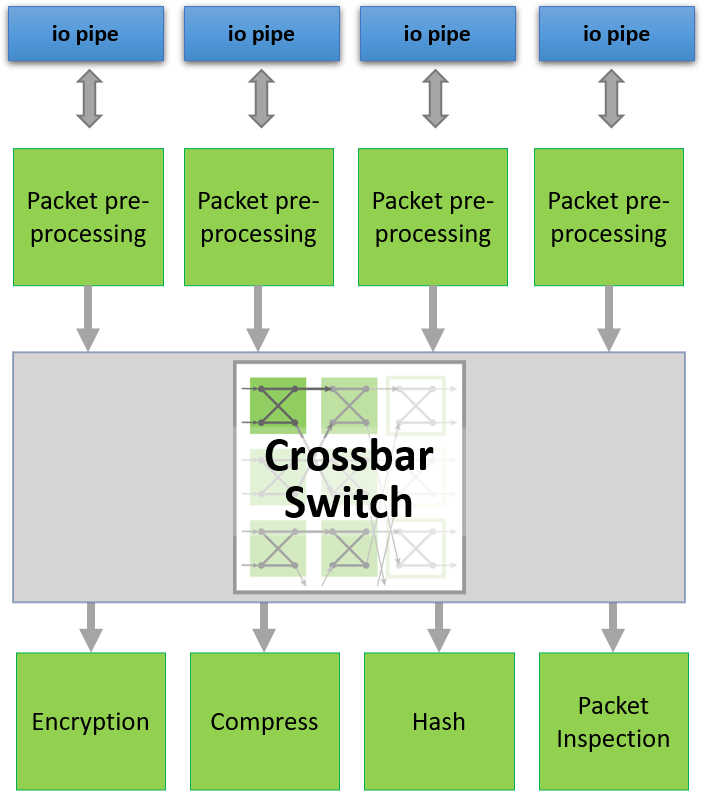
oneAPI 抽象了主機和 FPGA 之間的介面。具有外部 I/O 的介面(例如圖中的 QSFP)也使用 oneAPI I/O 管道進行抽象。這允許將設計擴展到支援oneAPI的多個BittWare FPGA卡。
交叉開關可用於將數據包定向到網路埠或從網路埠定向數據包。在這裡,對 DCP++ 代碼的一個小修改將仲裁更改為在網路數據包邊界上。
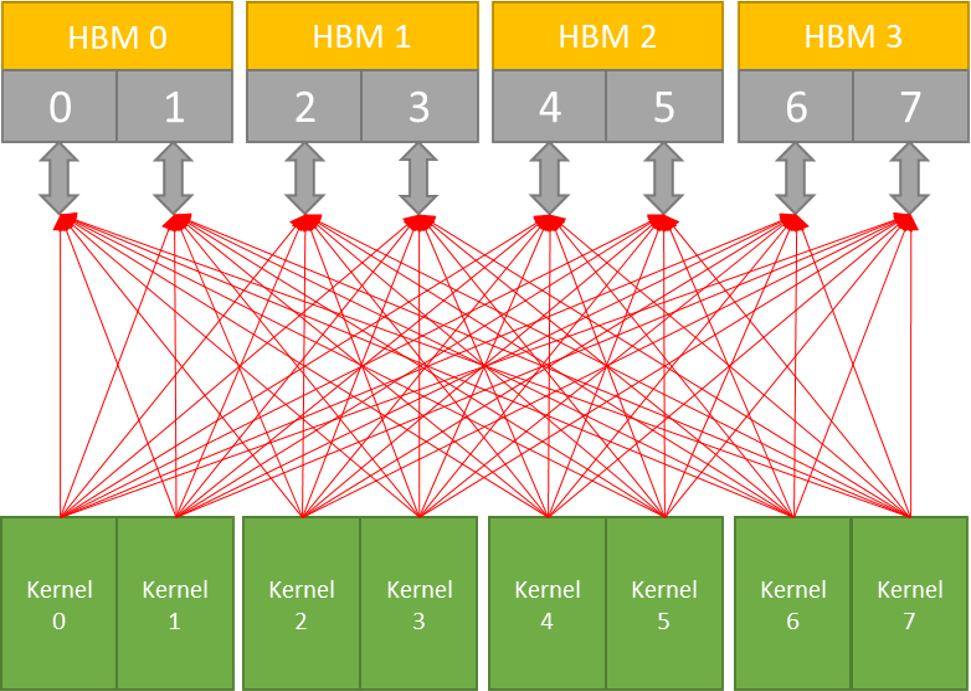
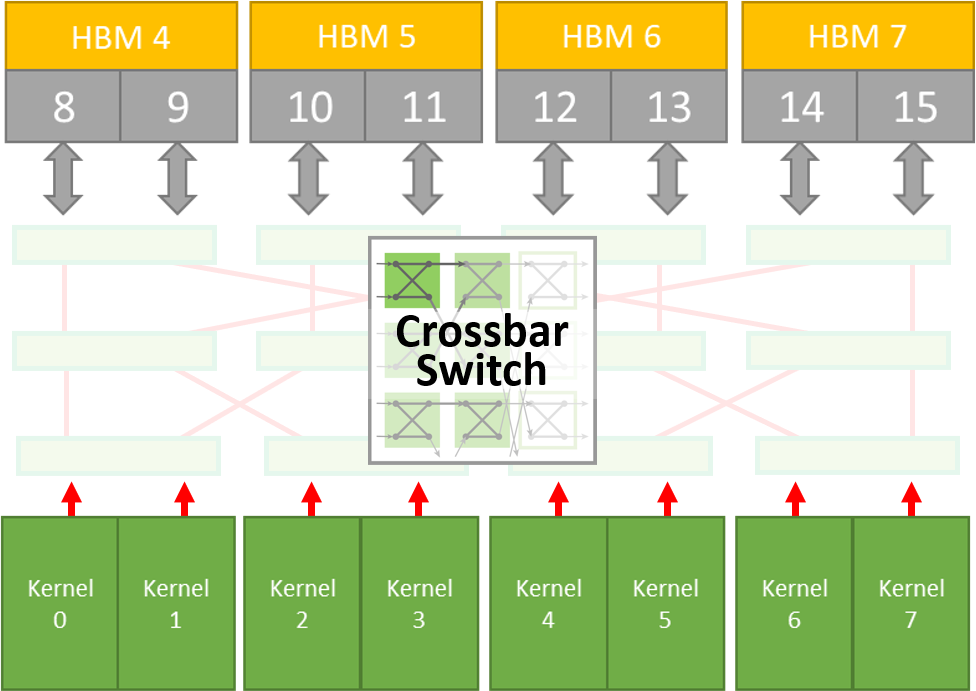
使用交叉開關,我們可以優化需要共用訪問 HBM2 記憶體通道的內核。
每個埠的峰值輸送量為12.8 GB/秒。
每個埠只能訪問 512 MB 記憶體
共 16 GB
我們的橫杆開關可以解決這些問題以提高性能。
沒有 橫杆:使用多路複用方法的大量路由(無仲裁)。
我們的蝶形橫桿開關減少了佈線,並增加了仲裁以提高性能。
您可以通過填寫此表格來請求BittWare蝴蝶橫桿開關。我們的銷售團隊將與您聯繫,以完成後續步驟,以接受許可協定並設置登錄以下載代碼。
“*”表示必填欄位