전 세계의 연결성이 날로 증가함에 따라 데이터의 양이 점점 더 많아지고 있습니다. 머신러닝을 올바르게 적용하면 이러한 데이터 내에서 패턴과 상호 작용을 추출하는 방법을 학습할 수 있습니다. FPGA 기술이 도움이 될 수 있습니다.
머신러닝은 알고리즘과 데이터를 사용하여 특정 작업을 수행할 수 있는 시스템을 만드는 인공 지능(AI)의 한 분야입니다. 더 많은 데이터를 처리할수록 시스템의 정확도는 서서히 향상되며, 이를 학습이라고 합니다. 이 시스템이 충분히 정확해지면 학습된 것으로 간주하여 다른 환경에 배포할 수 있습니다. 여기서도 동일한 학습 알고리즘을 사용하여 결과의 통계적 확률을 추론합니다. 이를 추론이라고 합니다.
신경망은 대부분의 머신러닝 작업의 기초를 형성합니다. 이는 훈련 중에 학습된 계수를 기반으로 상호 작용하는 여러 컴퓨팅 계층으로 구성됩니다. 이 백서에서는 FPGA 장치에서 신경망 추론에 초점을 맞춰 신경망의 강점과 약점을 설명합니다.
신경망의 핵심에는 엄청난 수의 곱셈 누적 계산이 있습니다. 이러한 계산은 수천 개의 뉴런의 상호작용을 시뮬레이션하여 어떤 일이 일어날 확률을 통계적으로 산출합니다. 이미지 인식의 경우 이는 네트워크가 특정 물체를 관찰하고 있다는 신뢰도 요소입니다. 물론 틀릴 수도 있습니다. 예를 들어, 인간은 무생물에서 사람의 얼굴을 자주 볼 수 있습니다! 따라서 모든 시스템에는 잘못된 결과에 대한 어느 정도의 허용 오차가 필요합니다. 이러한 결과의 통계적 특성은 최종 답변이 애플리케이션의 허용 오차에 의해 정의된 만족스러운 정확도 수준 내에 있는 한 계산의 동적 범위를 변경할 수 있는 기회를 제공합니다. 결론적으로 추론은 사용되는 데이터 유형에 창의력을 발휘할 수 있는 기회를 제공합니다.
데이터 폭은 종종 8비트 정수로 축소될 수 있으며, 경우에 따라서는 단일 비트로 축소될 수도 있습니다. FPGA는 거의 모든 크기의 데이터 유형을 처리하도록 구성할 수 있으며, 컴퓨팅 사용률에 거의 또는 전혀 손실이 없습니다.
신경망 추론과 관련하여 ASIC, CPU, GPU, FPGA는 각기 장단점이 있습니다. 맞춤형 칩(ASIC)은 최고의 성능과 최저 비용을 제공하지만, 특정 알고리즘에만 적합하며 유연성이 없습니다. 이와 대조적으로 CPU는 프로그래밍 유연성이 가장 뛰어나지만 컴퓨팅 처리량이 낮습니다. GPU 성능은 일반적으로 CPU보다 훨씬 높으며 많은 쿼리를 병렬로 처리할 때, 즉 많은 배치 수를 사용할 때 더욱 향상됩니다. 지연 시간이 중요한 실시간 시스템에서는 입력 데이터를 일괄 처리하는 것이 항상 가능한 것은 아닙니다. 이는 FPGA가 다소 독특한 영역으로, 신경망을 단일 쿼리에 최적화하면서도 높은 수준의 컴퓨팅 리소스 활용도를 달성할 수 있게 해줍니다. ASIC이 존재하지 않는 경우 FPGA는 지연 시간이 중요한 신경망 처리에 이상적입니다.
인라인 처리
그림 1은 FPGA의 일반적인 가속기 오프로드 구성을 보여줍니다. 여기서 계수 데이터는 연결된 딥 DDR 또는 HBM 메모리에 로드되어 업데이트되고 호스트에서 전송된 데이터를 처리할 때 AI 추론 엔진에 의해 액세스됩니다. 일반적으로 GPU는 높은 배치 수에서 FPGA보다 성능이 뛰어나지만, 배치 크기가 작거나 지연 시간이 짧은 것이 시스템의 가장 중요한 제약 조건인 경우 FPGA가 매력적인 대안이 될 수 있습니다.
그림 1 : FPGA 추론 오프로드
FPGA가 특히 뛰어난 분야는 AI 추론과 다른 실시간 처리 요구 사항을 결합할 때입니다. 고속 이더넷부터 아날로그 센서 데이터에 이르기까지 다양한 연결 문제에 맞게 FPGA의 재구성 가능한 IO를 맞춤 설정할 수 있습니다. 따라서 ASIC이 존재하지 않는 엣지에서 복잡한 추론을 수행하는 데 FPGA가 고유한 역할을 합니다. 또한 디바이스는 동일한 IO를 사용하여 애플리케이션에 가장 적합한 구성으로 여러 FPGA를 함께 연결하거나 기존 서버 연결에 맞출 수 있습니다. 연결은 맞춤형으로 만들거나 이더넷과 같은 표준을 따를 수 있습니다.
그림 2: 데이터 파이프라인 라인 내에서 추론을 사용하는 예시
인라인 처리의 경우, 신경망은 라인 속도로만 데이터를 처리할 수 있으면 됩니다. 이 경우 FPGA는 원하는 처리량을 유지하는 데 필요한 리소스만 사용하고 그 이상은 사용하지 않습니다. 이렇게 하면 전력을 절약하고 암호화와 같은 다른 작업을 위한 추가 FPGA 공간을 확보할 수 있습니다.
암호화
데이터 프라이버시가 중요한 분야에는 머신 러닝을 위한 상당한 기회가 있습니다. 예를 들어, 의료 진단은 클라우드 가속화의 이점을 누릴 수 있습니다. 하지만 환자 데이터는 기밀이며 여러 사이트에 분산되어 있습니다. 사이트 간에 전달되는 모든 데이터는 최소한 암호화되어야 합니다. FPGA는 매우 짧은 지연 시간으로 암호 해독, AI 처리, 암호화를 모두 수행할 수 있습니다. 결정적으로 복호화된 데이터는 FPGA의 경계를 벗어나지 않습니다.
그림 3 : 클라우드에서 복호화 및 암호화 로직으로 추론을 수행하기 위해 FPGA 사용
궁극적으로 이러한 민감한 데이터를 처리하는 데는 동형 암호화가 바람직한 접근 방식이 될 것이며, FPGA가 그 가능성을 보여주고 있습니다.
다양한 신경망 토폴로지에 맞게 최적화하기
신경망에는 여러 가지 유형이 있습니다. 가장 일반적인 세 가지 유형은 컨볼루션 신경망 (CNN), 순환 신경망 (RNN), 그리고 최근에는 Google의 BERT와 같은 트랜스포머 기반 네트워크입니다. CNN은 주로 이미지 인식 애플리케이션에 사용되며 본질적으로 매트릭스 처리 문제입니다. RNN과 BERT는 음성 인식과 같은 문제에 자주 사용되며 GPU와 같은 SIMD 프로세서의 CNN 모델에 비해 효율성이 떨어집니다.
FPGA 로직은 GPU와 같은 하드웨어에 알고리즘을 맞추는 대신 신경망 처리 요구 사항에 가장 적합하도록 재구성할 수 있습니다. 이는 배치 수가 적을 때 특히 중요한데, 배치 크기를 늘리면 GPU에 대한 종속성이 어색한 네트워크를 처리할 수 있는 해결책이 되는 경우가 많습니다.
컴퓨팅 및 메모리 대역폭 균형 조정
리셋은 많은 컨볼루션 레이어로 구성된 신경망으로 흔히 인용되는 신경망입니다. 그러나 이러한 레이어의 대부분은 단일 셀(1×1)의 스텐실만 사용하며, 이는 일반적인 요구 사항입니다. 스텐실 크기가 작으면 재사용 가능한 데이터의 양이 줄어들기 때문에 레스넷의 최종 레이어는 데이터 계산에 매우 높은 가중치 비율을 필요로 합니다. 가능한 가장 낮은 지연 시간, 즉 배치 크기 1을 달성하려는 경우 이 문제는 더욱 악화됩니다. 최상의 성능을 달성하려면 컴퓨팅과 메모리 대역폭의 균형을 맞추는 것이 중요합니다. 다행히 FPGA는 DDR, HBM, GDDR 및 내부 SRAM 메모리를 비롯한 다양한 외부 메모리를 지원하므로 올바른 장치를 선택하면 주어진 워크로드에 맞게 컴퓨팅 대역폭을 완벽하게 조합할 수 있습니다.
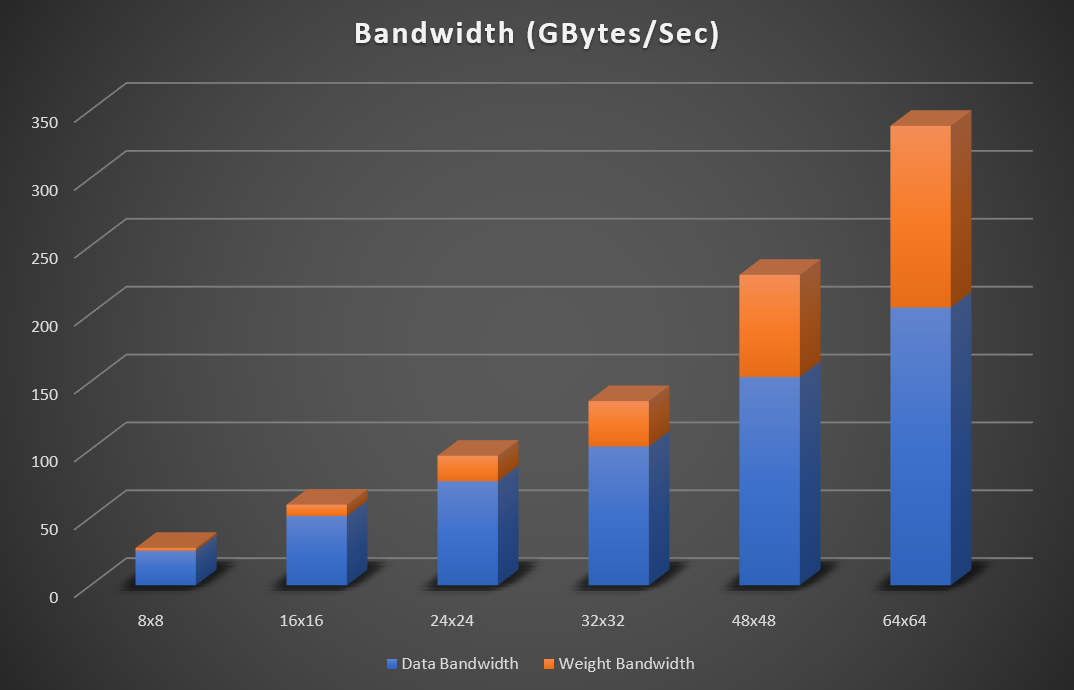
그림 4: 행렬 크기 증가에 따른 리셋(224×224) 피크 대역폭 요구 사항(32비트 부동 소수점 데이터)
그림 4는 Resnet 50의 경우 8×8, 16×16, 24×24, 32×32, 48×48, 64×64의 매트릭스 크기에서 증가하는 피크 대역폭 요구량을 보여줍니다. 대역폭은 가중치, 입력 및 출력 데이터가 외부 메모리로 읽히고 쓰인다고 가정합니다. 온칩 SRAM 메모리는 임시 누적을 저장하는 데 사용됩니다. 네트워크가 FPGA 메모리 내에 적합하면 기능 데이터를 지속적으로 메모리와 읽고 쓸 필요가 없습니다. 이 경우 외부 데이터 대역폭은 무시할 수 있는 수준이 됩니다. int8 구현의 경우 필요한 대역폭 수치를 4로 나눌 수 있습니다.
FPGA 공급업체
비트웨어는 공급업체에 구애받지 않으며 인텔, 자일링스, 아크로닉스 FPGA 기술을 지원합니다. 모든 FPGA 공급업체는 짧은 지연 시간과 낮은 배치 수 구현에서 우수한 성능을 발휘하지만, 각 디바이스마다 구성 가능한 로직의 적용에 미묘한 차이가 있습니다.
아크로닉스 스피드스터 7t
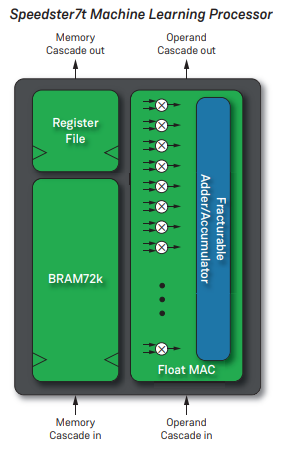
Achronix의 최신 FPGA는 신경망 처리를 가속화하도록 설계된 IP도 갖추고 있습니다. 각 머신 러닝 프로세서(MLP)는 4~24비트 연산을 지원하는 32개의 다중 누산기(MAC)를 처리합니다. Bfloat16과 같은 비표준 부동 소수점 형식도 지원됩니다. Achronix MPL과 인텔 텐서 구성 요소의 주요 차이점은 긴밀하게 결합된 SRAM 메모리로, 디커플링된 SRAM에 비해 더 빠른 클럭 속도를 보장한다는 점입니다.
The 비트웨어 S7t-VG6 는 2,560 MLPS의 Speedster7t를 탑재하여 이론상 총 61 TOps(int8 또는 bfloat16)의 최고 성능을 제공합니다.
그림 5 : Achronix MLP 3
그림 6 : BittWare S7t-VG6
인텔 스트라틱스 10 NX 및 애자일렉스
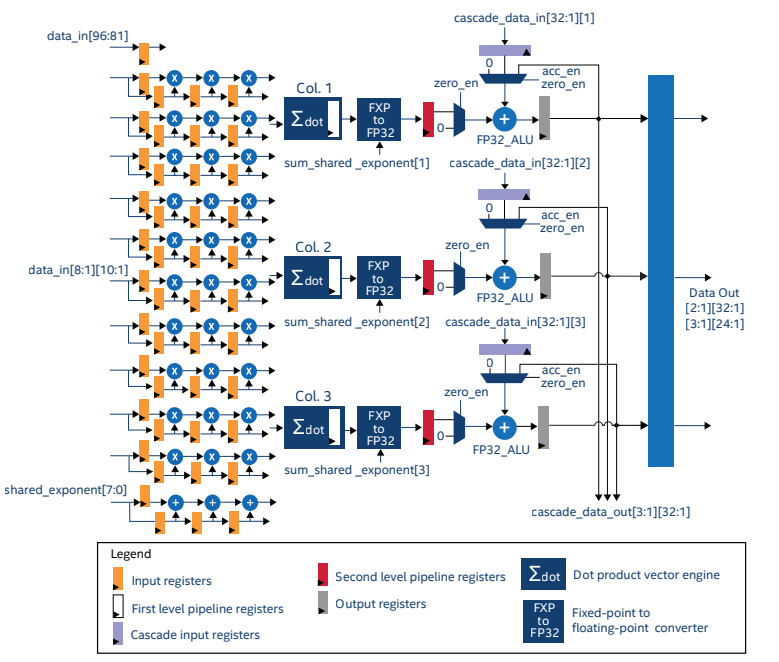
인텔 Stratix 10 NX는 전용 텐서 연산 블록을 갖춘 최초의 인텔 FPGA입니다. 텐서 IP는 10×3 데이터 블록에서 텐서 연산을 수행하도록 최적화되어 있습니다(그림 5). 이 IP는 int4, int8, 블록 FP12 및 블록 FP16 데이터 유형으로 작동하고 완전히 활용되도록 구성할 수 있습니다.
그림 7: 스트라틱스 10 텐서 IP1
Startix10 NX 디바이스의 이론적 최대 처리량은 표 1에 나와 있습니다.
또한 Stratix 10 NX에는 최대 512GB/s의 총 대역폭을 제공하는 HBM2 메모리가 있어 사용 가능한 모든 처리에 충분한 대역폭을 보장합니다.
정밀도
성능
INT4
286 TOPS
INT8
143 TOPS
블록 FP12
286 TFLOPS
블록 FP16
143 TFLOPS
표 1: Stratix 10 이론적 최대 처리량
Stratix 10 NX의 핵심은 비트웨어 520NX 가속기 카드의 핵심입니다. 이 카드는 여러 카드를 함께 연결하거나 센서 데이터와 통신할 수 있는 최대 600Gbps의 보드 간 대역폭을 제공합니다.
인텔 애질렉스 시리즈에는 텐서 DSP 구성 요소가 없지만, 스트라틱스 10에서 더 많은 데이터 유형을 지원하도록 DSP가 개선되어 저정밀도 연산 처리량이 증가했습니다. 인텔 애질렉스 M 시리즈의 이론적 Resnet-50 성능은 88 INT TOPS.2입니다.
그림 8 : BittWare 520NX
AMD 자일링스 버살
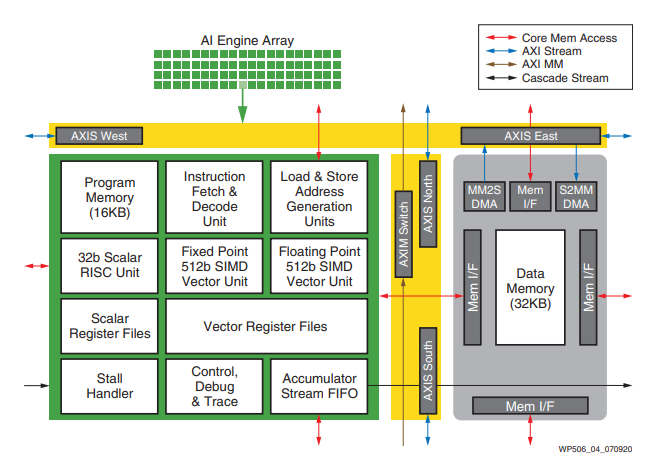
자일링스 Versal 디바이스에는 FPGA 프로그래머블 로직에 통합되지 않은 별도의 AI 엔진이 있습니다. Versal AI 엔진은 FPGA에 밀접하게 결합되어 있지만 나머지 FPGA에는 독립적으로 실행됩니다. 데이터는 네트워크 온 칩(NOC)을 사용하여 AI 엔진과 FPGA 로직 간에 전달됩니다.
그림 9 : Versal AI 엔진
BittWare는 현재 AMD Xilinx®의 7nm Versal 프리미엄 ACAP 디바이스가 탑재된 이중 폭 PCIe Gen5 가속기 카드를 포함한 컨셉의 ACAP 얼리 액세스 프로그램을 운영하고 있습니다. 자세한 내용은 Versal 정보 페이지에서 확인하세요.
신경망용 FPGA 프로그래밍
AI 엔지니어는 신경망을 설명하기 위해 PyTorch, TensorFlow, Caffe 등과 같은 다양한 고급 도구를 사용합니다. 다행히도 엔지니어가 기존 도구 흐름을 계속 사용할 수 있도록 AI 코드를 FPGA로 컴파일하는 API가 있습니다.
비트웨어에는 이러한 기능을 갖춘 파트너 회사가 있습니다:
EdgeCortix
엣지코어텍스 동적 신경 가속기 (DNA)는 높은 컴퓨팅 성능, 초저지연, 확장 가능한 추론 엔진을 갖춘 딥 러닝 추론을 위한 유연한 IP 코어로, Agilex FPGA가 탑재된 BittWare 카드에서 사용할 수 있습니다.
메그 컴퓨팅
VAS Suite 는 엔터프라이즈급 성능으로 실행 가능한 인사이트를 확보하는 동시에 TCO를 관리해야 하는 보안 및 시스템 통합업체를 위한 지능형 비디오 분석 솔루션입니다.
결론
최신 FPGA는 짧은 지연 시간, 작은 배치 크기 추론에 탁월한 성능을 발휘하는 매우 유능한 AI 프로세서입니다. 다른 처리 요구 사항과 결합하면 고유한 기능을 갖춘 AI 시스템을 구축할 수 있는 강력한 플랫폼을 제공합니다. 시스템의 요구 사항에 따라 한 FPGA 공급업체가 다른 공급업체보다 더 적합한 것으로 판명될 수 있습니다. 비트웨어는 고객이 전력, 처리 및 IO 요구 사항에 따라 적절한 FPGA 시스템을 선택할 수 있도록 지원할 준비가 되어 있습니다.