












来自Eideticom的查询处理单元IP核用于计算存储加速
BittWare合作伙伴IP查询处理单元(QPU) 建立FPGA驱动的加速器,以PCIe Gen4的速度查询、分析或重新格式化存储或流式数据!Eideticom的查询
BittWare合作伙伴IP查询处理单元(QPU) 建立FPGA驱动的加速器,以PCIe Gen4的速度查询、分析或重新格式化存储或流式数据!Eideticom的查询


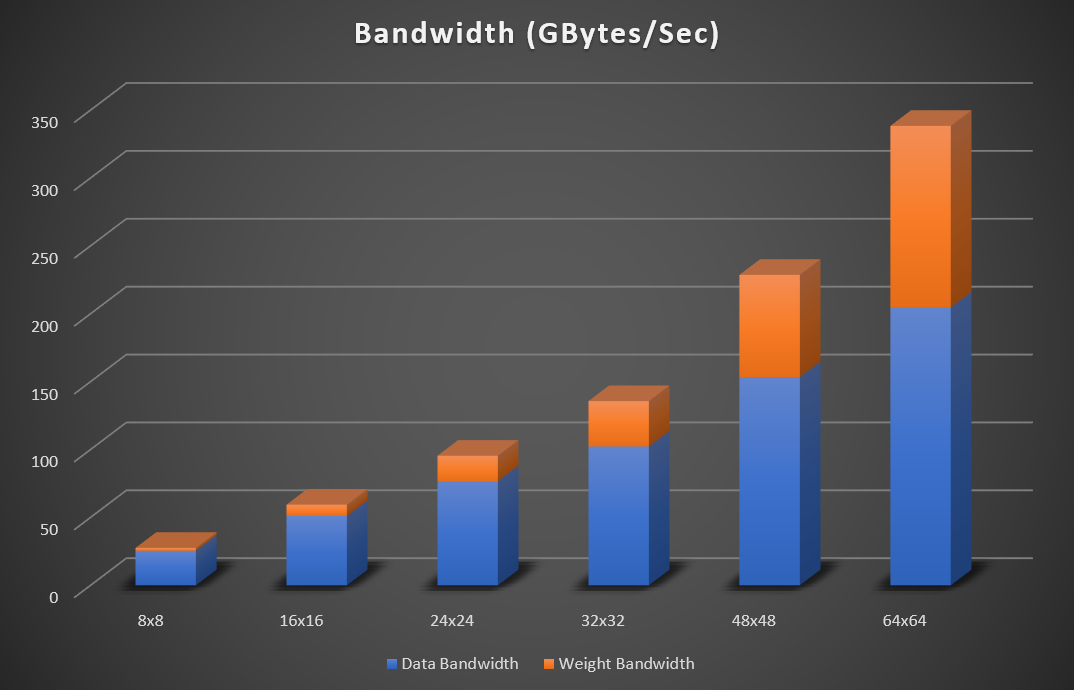
IA-860m 海量内存带宽 下一代PCIe 5.0 + CXL M系列Agilex采用HBM2e 英特尔Agilex M系列FPGA针对吞吐量大的应用进行了优化。
