
Homomorphic Encryption Acceleration
Article Homomorphic Encryption Acceleration FPGA acceleration enables this unique solution that allows compute on encrypted data without decrypting or sharing keys Traditional Encryption Limits Encrypting
FPGAs are making their way into more high performance computing applications, thanks to their advantages such as power efficiency and adaptability for specific workloads. In this webinar, we will focus on the latest Intel® Agilex™ FPGAs, including next-generation I-Series and M-Series devices.
Our special guest for this webinar is César González, who will explain the use of FPGAs at Barcelona Supercomputing Center in an acceleration project and recently published paper. His research into determining the structure of small molecules utilized OpenCL high-level programming. César will present, along with Intel’s Maurizio Paolini, results of porting of this code to oneAPI the BittWare IA-840f card with an Intel Agilex FPGA, achieving a 233x speedup.

We’ll also look at the next-generation Agilex FPGAs including those with PCIe Gen5, CXL and HBM2e–plus BittWare cards supporting these devices.
If you are working in HPC, or have an interest in how the latest FPGAs are providing new levels of acceleration performance, be sure to join us for this webinar!
Watch immediately on demand, including recorded Q&A with our panelists!


Christian Stenzel | EMEA Technical Sales Specialist, Intel

Craig Petrie | VP Marketing, BittWare

Maurizio Paolini | Field Applications Engineer – Cloud and Enterprise Acceleration Division, EMEA, Intel

César González | Barcelona Supercomputing Center, Institute for Advanced Chemistry of Catalonia – CSIC
(Marcus)
Hello and welcome to our webinar, “High Performance Computing with Next-Generation Intel Agilex FPGAs.” We are featuring an example application from Barcelona Supercomputing Center. I’m your host Marcus Weddle with BittWare.
Let’s start by meeting the presenters and what they’ll cover.
First is Christian Stenzel from Intel. He’s got 16 years of experience at Xilinx in a range of roles from FAE to account management and business development and joined Altera in 2015. After the Intel acquisition, he moved to the position of Technical Sales Specialist for Cloud and Enterprise, driving Intel FPGA acceleration strategies within EMEA Cloud and Enterprise markets. Christian will get us started with why FPGAs for HPC? He’ll also introduce the Intel Agilex family of devices.
Next up is Craig Petrie from BittWare. He brings decades of experience in FPGAs, starting as an engineer and then moving on to lead product management and strategy, and today he’s Vice-President of sales and marketing. Craig will take us through BittWare’s products that feature Agilex FPGAs, support for oneAPI, BittWare’s new partner program, and he’ll conclude with an introduction to CXL.
Our HPC application section will come from two presenters, Maurizio Paulini, an FAE with Intel, and our special guest speaker Cesar Gonzalez. Cesar will explain the application side of his work with FPGAs at Barcelona Supercomputing Center, and Maurizio will give details on oneAPI—including the recent port of Cesar’s application to oneAPI on a BittWare card with Agilex.
If you’re watching this on one of our live sessions, be sure to ask a question using the Questions feature and we’ll put them to our panelists at the end.
Okay let’s get started with Christian Stenzel from Intel!
(Christian)
Thank you, Marcus, and thanks for having me today. First, I need to make you aware of the Intel Legal Disclaimer which you can read at your own convenience.
Now, let’s talk about High Performance Computing. HPC is a broad market and is used to gain a better understanding about the largest but also the smallest things. From exploring the universe, research for cleaner energy, weather and climate modeling to quantum physics, bioinformatics, molecular dynamics, nuclear research and much, much more.
Researchers and scientists are confronted with more complex problems with ever-more increasing amounts of data which are calling for more compute to be able to process data and run simulations. In other words, HPC customers are in a race for performance.
In a typical HPC datacenter, CPUs are used as the default option to run the computations along with GPUs as the number one accelerator for parallel problems. Now, with FPGAs there is a third ingredient to complement an HPC system to solve problems that CPUs and GPUs are not good at, and there are always workloads which run best on an FPGA.
Historically FPGAs have been difficult to program, and special RTL programming skills are required. Maurizio will talk later in his session how oneAPI enables FPGA programming without RTL skills.
Let’s take a look at the unique capabilities of FPGAs.
As I mentioned, performance is critical in HPC. Unlike CPUs or GPUs with an almost fixed architecture forcing how data is processed, or how a given algorithm needs to be adjusted to the architecture, an FPGA provides full flexibility. The internal FPGA hardware architecture can be built—we say “configured”—to fit best to the algorithm of interest, providing lower latency with high performance. For example, incoming data over Ethernet line, or directly from memory can be processed real time without calling upon the host CPU. That is the inline or “bump in the wire” acceleration use case. Or a complete algorithm can be offloaded to the FPGA and results are written back to the host CPU. That is the look-aside acceleration use case.
Advanced scalability can be achieved by changing the FPGA and/or using field programmability, changing the workload on the fly. FPGAs can also run multiple workloads in parallel without interfering each other. FPGAs by nature provide IO richness and an acceleration card has many different interfaces. Clustering of FPGAs to distribute a workload over multiple FPGAs or enable stages of processing with high-speed inter-chip communication can be used to scale up performance.
Increased productivity is being achieved by (thanks to) our Intel Open Acceleration Stack making it easy to install an FPGA acceleration card in existing servers and provide a simple method for configuring the system to accelerate applications.
In an HPC datacenter power consumption is extremely critical. An FPGA allows the hardware to execute functions in fewer clock cycles and at lower clock frequency compared to CPUs and GPUs resulting in lower power consumption. Lower power consumption means saving energy, which in turn means that one can reduce OpEx and spending of TCO.
Next up is price. There are many options for FPGA Acceleration Cards for the standard cluster. Installing FPGA acceleration cards to boost performance of the cluster can be more cost effective than upgrading or a renewal of a cluster to hit performance targets.
Move to Slide 4 – Agilex: The FPGA for the Data-Centric World
Now, let’s have a look at our FPGA family Agilex which has been built on 10nm process technology. First, we have all been suffering from the global supply constraints. Agilex has been manufactured in Intel fabs. Second, you probably have seen the announcements that Intel is investing in building fabs to reduce dependencies.
Back to Agilex. There are different sub-families of Agilex with different capabilities which I do not have time to go deeper into today. Please reach out to us for more information or go to intel.com/agilex.
There are several features of Agilex, which, when compared to the previous FPGA generation, has up to 40% higher performance and up to 40% lower power, and it can also achieve higher transceiver data rates. Agilex also offers up to 40 TFLOPS of DSP performance. Agilex supports DDR5, the next generation of HBM, along with PCIe Gen5, and Compute Express Link (CXL), which is especially interesting for HPC customers.
Concluding my talk with the key messages I touched on: HPC customers are in a race for performance. FPGAs can complement the system by providing unique capabilities that can boost performance and reduce overall TCO.
Now, the Agilex FPGA alone cannot be used in a datacenter, of course there has to be an enterprise class card hosting the FPGA with all the necessary interfaces and required ingredients on the board like memory for example. With the help of BittWare, Agilex-based acceleration cards are available in the market to boost datacenter performance. Now, Craig, over to you.
(Craig)
Thanks, Christian and welcome to everyone watching the webinar today.
For those who are unaware, BittWare is part of Molex which is one of the world’s largest design and manufacturing companies servicing major customers across a range of markets including high performance computing.
BittWare is part of Molex’s Datacenter Group.
BittWare designs and manufactures enterprise-class acceleration products featuring the latest and greatest FPGAs – for today’s webinar we are focusing on Intel Agilex FPGAs.
These high-performance programmable accelerators enable our customers to develop and deploy Intel FPGA-based solutions q uickly and with low risk.
Our products are used for rapid prototyping and benchmarking, but ultimately are intended for cost-effective volume deployments.
When we think about High Performance Computing, we break that term down into three main application areas: Compute, Network, and Storage.
Within these, there are a multitude of workloads which are well-suited to FPGAs. Examples include natural language recognition, recommendation engines, network monitoring, inference, secure communications, analytics, compression, search, and many, many others.
At BittWare, we try to reduce the cost, effort, and risk of implementing these workloads on Intel FPGAs.
The first way we do this is by taking the FPGA device, in this case the Intel Agilex FPGA, and create platform products.
These are primarily PCI Express cards in form factors including HHHL, FHHL, and dual-slot GPU, however we also support some storage form factors including U.2.
Each card or module adheres to official specifications to ensure compatibility with existing and new infrastructure.
Cards can be purchased individually or delivered p re-integrated in servers which have been optimized for FPGAs—we call these TeraBoxes. Often, we leverage servers from leading providers such as those listed in the slide.
We are currently shipping three Intel Agilex products as shown here.
The GPU-sized IA-840f card is our current flagship. It features the AGF-027, four banks of DDR4 memory, network ports, and expansion ports. We’ve supported oneAPI on our Stratix 10 MX card for a couple of years now, but the ’840f is our first Agilex-based card to support the oneAPI toolflow.
Intel’s oneAPI is a bold, welcome initiative to introduce a unified software programming model. Using oneAPI, our customers are able to program from a single code base with native high-level language performance across architectures.
oneAPI includes a direct programming language: Data Parallel C++ and a set of libraries for API-based programming to make cross-architecture development easier.
Data Parallel C++ is based on familiar C++ and incorporates SYCL from the Khronos Group. This dramatically simplifies code re-use across multiple architectures and enables custom tuning for accelerators.
Fundamentally, it opens up FPGAs to software customers typically using x86 or GPU technologies. Any customer wishing to develop and benchmark with oneAPI on Agilex should consider the BittWare ’840f card.
BittWare pioneered oneAPI support on our Intel Stratix 10 cards. For those implementations we used an OpenCL layer as the Board Support Package. Example designs and whitepapers can be found in the resources section of the website.
For our Intel Agilex-based products, our oneAPI implementation uses the Intel Open FPGA Stack, or “OFS.”
For those customers who want to forgo the programming of the FPGA entirely, you can purchase our FPGA accelerator cards pre-programmed with application code from domain experts such as Atomic Rules, Edgecortix, and Eideticom via the BittWare Partner Program.
As we look ahead to new technologies in 2023 and beyond, there is arguably none more important for the future of High Performance Computing than CXL.
CXL, which stands for Compute Express Link is the new accelerator link protocol. It is based on and adds additional functionality beyond the existing PCIe protocol by allowing coherent communication between the host and the accelerator. In this case, the Intel Agilex FPGA. This allows a CXL link to enable efficient, low-latency, high-bandwidth performance when used with look-aside or inline accelerators for heterogenous computing.
BittWare has announced three new FPGA accelerator cards which support CXL. The ’440i and ’640i are single-width HHHL and FHHL cards with support for the I-Series of Agilex FPGAs.
We’ve taken advantage of the impressive F-Tile support for 400 gigabit Ethernet, and R-Tile support for PCI Express Gen 5 x16.
The GPU-sized ’860m card features the ground-breaking M-series Agilex FPGA, which has support for up to 32GB of HBM2 memory in-package and DDR5 memory externally. This is an incredible device for High Performance Computing, especially applications which are memory-bound.
BittWare is able to support CXL because both the Agilex I-Series and M-Series FPGA families feature hard IP allowing for the full bandwidth of Gen 5 x16 configuration support, with minimal use for FPGA resources.
We are on track to ship our first CXL-capable FPGA cards in Q1 of 2023.
So why is CXL so important? Well, our customers have made it very clear that they need higher performance, better energy efficiency, and compute capabilities with access to different memories within their applications.
Consensus is that CXL will enable a new level of performance for heterogenous computing architectures featuring FPGAs.
Intel Agilex FPGAs provide 4x CXL bandwidth per port and 2x more PCIe bandwidth per port than competing solutions.
As cloud computing becomes more ubiquitous, customers need to evolve their architectures in order deliver faster, more efficient data processing.
This means innovation within the three main application areas I mentioned earlier. Specifically, the tight coupling of accelerator technologies for compute-intensive workloads, SmartNICs within the Network area which can process data on the fly, and Computational Storage which can process vast amounts of data at rest within the storage plane.
Compute, Network, and Storage technologies already connect over PCI Express, however, to achieve a step change in application performance they need to leverage the benefits of CXL.
The CXL protocol describes three usage configurations for the CXL-attached device.
A Type 1 device can be used for streaming and low latency applications such as a SmartNIC where the accelerator requires coherent access to the processor’s memory with no host access to its own memory.
A Type 2 device is the most complex implementation since it handles all three CXL sub protocols: CXL.IO, CXL.Cache and CXL.Mem. This type is intended to be used for complex tasks such as AI inferencing, database analytics, or smart storage.
A Type 3 device allows any memory attached to the CXL device to be coherently accessible by the host. In this instance, the FPGA can still provide valuable benefits by allowing implementation of special FPGA logic such as unique compression and encryption algorithms.
For those who are not aware, the Intel FPGA CXL IP comes as a combination of hard IP and soft IP.
In order to design applications using Intel’s CXL IP, customers need to purchase a separate IP license.
Once you have activated the Intel CXL license, you will be able to find the Intel IP inside the Quartus Prime tools.
Once the CXL hard IP for the Agilex R-Tile is activated, then the appropriate soft IP is added to the design.
Note that the Agilex I-Series FPGAs shipping on BittWare’s PCIe cards are CXL 1.1 and 2.0 capable.
Looking further ahead, Intel have a roadmap for supporting CXL 3.0 which ties into the PCIe Gen 6 specification.
So, CXL is going to be important. Anyone watching this webinar whose job involves understanding and evaluating new technologies must consider CXL.
In order to help customers do this, BittWare is putting together a complete CXL development and benchmarking platform.
It comprises a 2U rackmount server featuring Intel Sapphire Rapids Xeon CPUs. BittWare’s Intel Agilex I-Series FPGA cards are also pre-integrated.
A Linux operating system will be pre-installed along with the Intel Quartus and CXL licenses needed to start development.
We want customers to get up to speed extremely quickly, so this bundle will include an application example reference design leveraging CXL.
Technical support and a comprehensive warranty covering the server and FPGA hardware is included along with technical support services.
This is just a sneak peek of what we are offering. Full details will be announced in due course. In the meantime, please contact BittWare for further details.
With that, I will now hand over to Maurizio for the next part of the webinar. Thank you.
(Maurizio)
Thank you, Craig.
Let’s now have a look at oneAPI, the programming model used for this case study.
Programmable acceleration cards like IA-840f are a powerful building block for heterogeneous computing architectures. Heterogeneous architectures are becoming popular in High Performance Computing because not all workloads are the same, and there is no single computing architecture—be it CPU, GPU, FPGA, or dedicated accelerator—that fits them all. The adoption of heterogeneous architectures allows programmers to select the best fit for each workload in terms of throughput, latency, and power efficiency.
However, developing code for heterogeneous architectures is not a simple task and implies significant challenges. Today, each data centric architecture needs to be programmed using different languages and libraries. That means separate code bases must be maintained, and porting across platforms implies a significant effort. In addition, inconsistent tools support across platforms means developers have to waste time learning different sets of tools.
In short, developing software for each hardware platform requires a separate investment, with little ability to reuse that work to target a different architecture.
Intel’s solution to this problem is oneAPI, a project to deliver a unified software development environment across CPU and accelerator architectures.
This is not a proprietary project. Instead, it is based on an open industry initiative for joint development of specifications, aiming at development of compatible implementations across the ecosystem.
The programming model has then been implemented by Intel as a set of toolkits that will be described in the next slides.
The oneAPI programming language is data parallel C++. This is a high-level language designed for data parallel programming productivity. It is based on the C++ language for broad compatibility and simplifies code migration from proprietary languages with a programming model familiar to GPU software developers.
The language starting point is SYCL being developed under the industry consortium Khronos Group. Intel and the community are addressing gaps in language through extensions that we will drive into the standard.
Data parallel C++ allows code reuse across different hardware targets: CPU, GPU, or FPGA. However, there will still be a need to tune for each architecture for maximizing performance.
As I mentioned earlier, Intel’s reference implementation of oneAPI is a set of toolkits.
The toolkits include:
Note that, as of today, API based programming support of FPGA is limited.
To get started with building and running data parallel C++ code on an FPGA, users need to download and install the development software stack that is composed of:
The oneAPI development stack provides easy access to FPGA platforms to software programmers who are not familiar with the traditional RTL-based design methodology for FPGAs. Designing in RTL implies a deep understanding of the FPGA architectural details and of advanced topics such as timing closure. Using oneAPI, such details are handled by the compiler and the BSP, and the effort required for programming FPGAs becomes equivalent to any other platform.
And now over to Cesar for an introduction to the case study we will cover today.
(Cesar)
Hello, my name is Cesar Gonzalez from Barcelona Supercomputing Center, and I would like to introduce you to our research where are we are using FPGA devices.
First of all, I would like to show you our supercomputer: “MareNostrum.” If you visit Barcelona, you can visit it (and also you can visit our monuments like Sagrada Familia, of course).
What we are trying to do: we’re trying to determine the structure of small molecules that cannot be determined by any other system. How we are going to do that: we’re going to do that using the spectra of these molecules. If we have the spectra of the molecule, how can we find the structure?
So, we use—what is proven in the last century that is—that you can build a model of the molecule in 3D space and then later on, you can build the spectra of this theoretical model and you can compare this spectra with the real one.
If the spectra is the same, you have the structure. If not, you can re-configurate your model to calculate the new spectra to see if it matches to the real one.
OK, so, what were we doing the first time? Just to make a test to check if it was…if it was real. Our test was with two million electrons in double density sphere, and you can see here on the slide.
So, as we know the analytical solution of the spectra of this double sphere, we calculate the theoretical spectra of this sphere and, later on, compare with the analytical solution of the spectra.
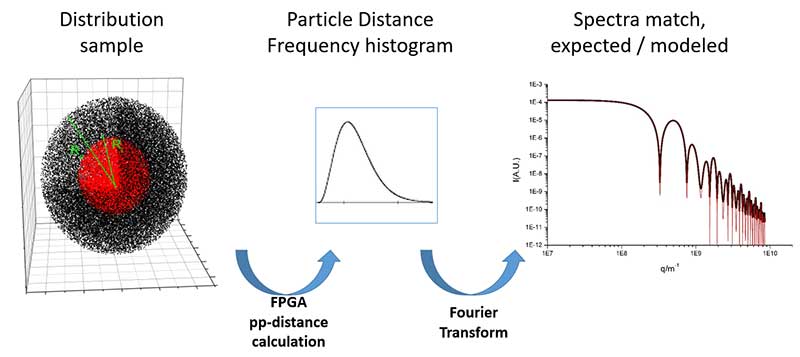
So here is the key of all the things: to calculate the spectra of this model (we use like a test), we have to calculate all the distance of two particles in this model.
Here is where high performance computing comes on, because when the number of particles is very high, the time to perform on all the distance is very, very high. So, we have here the distribution of sample of two million electrons—that is our test.
What we did, we calculated the histogram of these two density spheres model. Okay.
We take two particles, we calculate their distance, and we multiply the density of the [first] one with the electron density of the second one, and we put this weight inside the distance place of the histogram.
Two particles by example, distance 100 angstroms: So, you put the electron weight of this pair in the 100 Angstrom…x [axis]…here in the histogram. Okay.
So, if they have 200 angstroms distance you put in the other side. If you have another one or two of 200 Angstrom distance, you add to the histogram and you take the histogram. And here we are using the FPGA distance calculations.
Later on, when you have the full histogram, you perform the Fourier Transform, you can see if what you have calculated, that is, the red line here, is the same as the analytical solution (that is the other line), and you can see that this matches it. So, we proved that the theory of the last century was true.
So, we enter in another step that was just to take a real one molecule that we know the structure, and we build a theoretical model of this molecule and, later on, see if these really match the spectra of the molecule.
Here is the Silver Behenate cell. This cell has two molecules of Silver Behenate. We build this because we know the real structure of Silver Behenate and later on, we create the model. Here is the model—what did we use? Just to put 25 by 25 by 3 repetitions of the cell. And we perform it—with the FPGA—the theoretical spectra, and here we go.
What do we have here?
The green line is the real spectra of the Silver Behenate. The blue one is the calculation with the electrons using quantum distribution, by Hartree-Fock.
The black line is with a random distribution of the electrons and the red one is the device that is calculating the performance with the atoms, not the electrons.
What we use also…is another test, just to see if we match the real model. So, you can see, if we use the quantum distribution of Hartree Fock, the match is full like the device.
We shift the green line up just to see that these match because what is important for us is just where the peaks are. If the peaks are in their places, we can know the structure.
As you can see, when we use a random distribution of electrons, there is a difference between the real spectra at the end of the graph that is solved with the distribution from Hartree-Fock that uses the quantum distribution density of electrons.
So, I would like to say thanks to Intel and my Institute for Advanced Chemistry of Catalonia, and, also, thank you to ALBA Synchrotron where we have been doing the spectra of the Silver Behenate.
Thank you all for seeing this presentation and I would like to invite you to see our scientific article that you can see in this DOI reference and also the situation of our research in our book of abstracts in the Barcelona Supercomputing Center. Thank you, bye.
(Maurizio)
Thank you, Cesar.
Now let’s have a look at the algorithm that has been implemented in this case study. This is called the particle pair distance algorithm or pp-distance algorithm and can be described as follows.
Given a set of N particles located in a three-dimensional space, for each possible pair of particles, compute the distance between them.
In our case study, the power density for each pair is then accumulated in a bin corresponding to the computed distance. Distances are computed using single-precision floating point, then converted to integers for binning, while accumulation is performed using double-precision floating point.
The complexity of this problem is N squared, since the number of point pairs in a N-point set scales with the same factor.
This algorithm was originally implemented in OpenCL and tested on two different programmable acceleration cards: the Intel Arria 10 GX card (based on an Intel Arria 10 1150 FPGA) and the Intel D5005 card (based on an Intel Stratix 10 SX 2800 FPGA). The algorithm has then been ported to DPC++ and implemented on the BittWare IA-840f card (based on an Intel Agilex AGF027 FPGA).
The toolchain used for this implementation is oneAPI release 2022.2 and Quartus Prime Pro 21.4. We will take a look at the results we achieved for all the above configurations later in this presentation.
Now let’s take a quick look at a reference implementation for this algorithm. This is an OpenCL kernel that takes as inputs the number of points in the set, the number of bins to be used for the results, and pointers to the arrays storing the point data—coordinates and associated power—and returns the array of accumulated results. The core of the kernel is the set of two nested loops (in red box) in which the distance of the point pairs is computed, and power density accumulation takes place.
The reference implementation in the previous slide has been properly optimized before running it on FPGA. As Christian mentioned earlier, in FPGAs the internal architecture is configured to fit the algorithm to implement.
So, coding for FPGA means shaping the architecture of the computational datapath, and this is different from the CPU and GPU cases, where the compute architecture is fixed. When optimizing for FPGA, the programmer uses the information provided by the oneAPI toolchain—code static analysis and dynamic profiling reports—to identify performance bottlenecks in the implemented datapath and remove or mitigate them using coding techniques. If you are interested in knowing more about optimizing code for FPGAs, documentation, training material, tutorials, and design examples are available on the Intel and GitHub web sites.
In our case several optimizations have been applied to the original code to improve memory access and computation efficiency. The result has been an increase in performance of more than one thousand times against the original code.
I mentioned in a previous slide how this code was originally written in OpenCL and ported to DPC++. Now, porting the code was a quite simple task, and very limited changes were needed. Basically, the kernel code architecture had to be adapted to the DPC++ coding style, and that means a lambda function was used for the kernel itself, accessors for data movements were defined, and the syntax for pragmas and attributes was adjusted to the new language. On the other hand, the host code was greatly simplified, because many details that must be explicitly managed in OpenCL are automatically handled by the runtime in DPC++. As a result, the DPC++ host code is half the size of its OpenCL counterpart.
And now let’s have a look at the results.
Note that the code for FPGA is parametric. That allows users to explore the architectural space of the implementation and find the best trade-off between target kernel clock and frequency and data parallelism—that is the unroll factor.
The results in this table show the best trade-off found for each case.
The first line refers to a sequential implementation of the algorithm running on the host CPU (that is a Xeon Ice Lake processor) as a single-threaded code. This implementation processes a two million points data set in 9,600 seconds—that is two hours and forty minutes.
The DPC++ implementation running on the IA-840f card processes the same amount of data in sixty-one seconds—157 times faster than the sequential implementation—when performing all accumulations in double-precision floating point. If 40-bit integers are used for partial accumulations, processing time drops to 41 seconds, that is 233 times faster.
Also, when compared against the previous generation of high-end FPGAs, Agilex FPGAs allow a higher clock frequency and a higher data parallelism, resulting in twice the performance.
That concludes this presentation. Thanks for following us. And now over to the Q&A session.
(Marcus)
All right, so Marcus back on here for our Q&A, and I just wanted to, before that, recap. We’ve got a lot of information that’s come through and a few questions have come in already. I just want to remind you that if you have a question for our panelists type it out using the question feature and we’ll put it to our panelists.
I definitely wanted to thank Maurizio and Cesar especially for their presentations and details on the work at HPC…their HPC work at Barcelona Supercomputing Center.
You know this new Agilex families of FPGAs bring an excellent combination of performance and features that are well-suited for HPC workloads. And we talked about using the oneAPI programming model as something that really anybody in HPC should at least consider as it allows for code portability, flexibility, and the things that Maurizio talked about.
We saw that the code was ported from an Arria 10 based card to Stratix 10—both using OpenCL and then Maurizio ported oneAPI…using oneAPI on BittWare’s new IA-840f Agilex card and it was just a very quick, smooth workflow change—that’s one of the advantages.
And then performance too as we heard at the very end. Very impressive performance and acceleration numbers on this HPC workload on the Agilex device.
And then we also heard about CXL, so Craig mentioned the new CXL development bundle that’s coming soon from BittWare. Get in touch with us if you’d like to hear more about that.
All right so onto our questions.
I did want to ask, Cesar, first. You know, we talked about FPGAs that you used, but where did you come to the decision to use FPGAs for your particular application?
(Cesar)
Well, in fact, I was programming first with GPUs with C CUDA and we did the FPGAs because all the people of the team understand, directly, the pragmas of the high-performance computing components that are very easy to understand how it works. And for us, it’s very important that all people can understand the kernel, the OpenCL kernel.
Also, all the experience that you have, all the things that you do with the FPGA, later on, you can implement in GPUs. Anyway, we see some restrictions, using restrictions, some convenience or inconvenience using GPU. By example, if the model is 10 times bigger, the time in the GPU is twice. Meanwhile, the time in the FPGA is the same. But that doesn’t mean that the FPGA is better than GPU. There are different environments for us. For us, FPGA is better. It was at the beginning of my Ph.D., I was telling, digital, digital, sorry, telling Intel—one question: “If you go to Mars, what will you carry with you? A GPU or an FPGA.” (laughs)
(Marcus)
Yeah that’s a good question. And yeah, that’s a good analogy there I appreciate that.
And just briefly, could you recap? I know you talked about the process that you used in detail, but what is the end result? I know you spoke about it just at the beginning, but just as far as the…what’s the use case that you will use these results for?
(Cesar)
Well, when you can determine the structure of a molecule—right there—you can build treatments or pills for people that are ill and all those things. So, we are working in the base of the biomedicine and also in the base of the nanotechnology. So, this is very important for the doctors and others when they like to know how we can block this molecule or this other. This is very important for—yeah.
Article Homomorphic Encryption Acceleration FPGA acceleration enables this unique solution that allows compute on encrypted data without decrypting or sharing keys Traditional Encryption Limits Encrypting

Build ultra-low latency apps for fintech using Enyx off-the-shelf solutions and the nxFramework.
White Paper Introduction to BittWare’s SmartNIC Shell for Network Packet Processing Overview SmartNIC Shell is a complete working NIC that is implemented on a BittWare
Meet the Powerful IA-840f: Enterprise-Class Intel Agilex Based FPGA Accelerator > Flexible, Customizable Hardware > oneAPI Software Support Buy at Mouser Tap Into the Power