
來自Megh的VAS套件視頻分析解決方案
BittWare合作夥伴解決方案 VAS 套件智慧視頻分析解決方案 Megh Computing的VAS套件是面向安全和系統整合商的智慧視頻分析解決方案



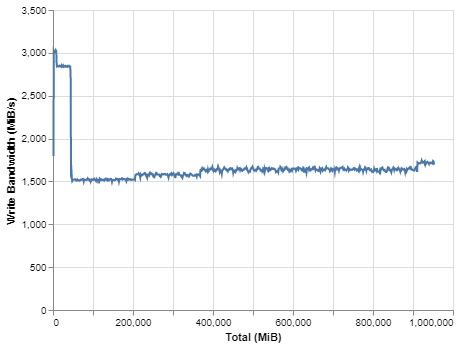
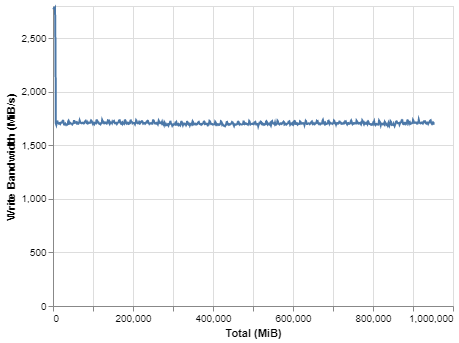
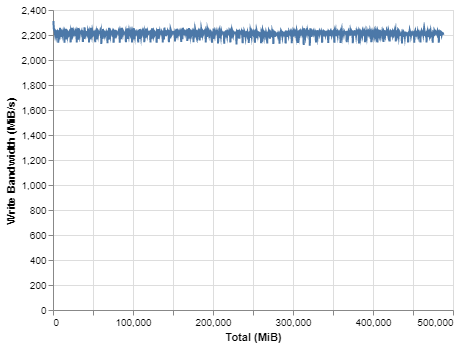
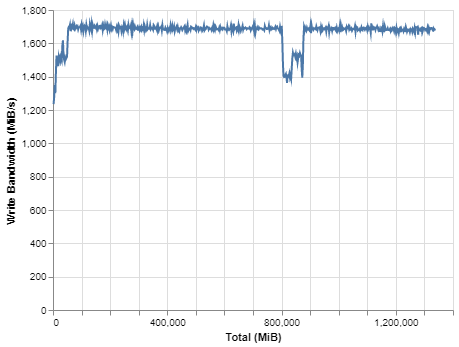

BittWare合作夥伴解決方案 VAS 套件智慧視頻分析解決方案 Megh Computing的VAS套件是面向安全和系統整合商的智慧視頻分析解決方案

BittWare 合作夥伴 IP NVMe 橋接平台 NVMe 攔截 AXI-Stream Sandbox IP 計算存放裝置 (CSD) 允許存儲端點提供計算存儲功能 (CSF)

