
構建BittWare的數據包解析器,HLS與P4實現
白皮書構建BittWare的數據包解析器,HLS與P4實現概述BittWare的SmartNIC Shell和BittWare的Loopback Example的功能之一是


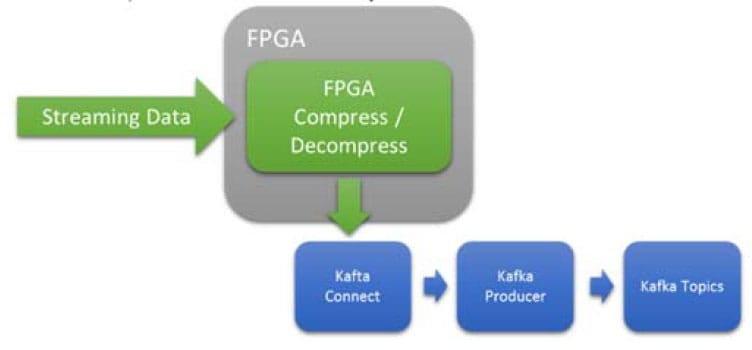
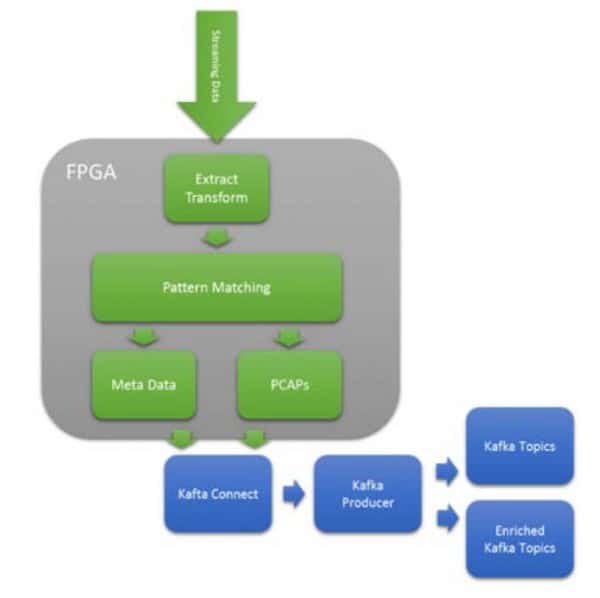
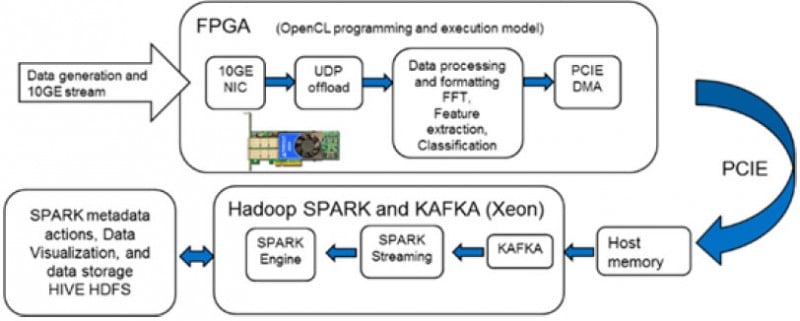
白皮書構建BittWare的數據包解析器,HLS與P4實現概述BittWare的SmartNIC Shell和BittWare的Loopback Example的功能之一是

PCIe FPGA 卡 XUP-VV4 UltraScale+ FPGA PCIe 板,配備 VU13P 4 個 100GbE 和高達 512GB DDR4 需要報價?跳轉到定價表單

返回IP和解決方案 用於10/25/50/100GbE原子規則的UDP卸載引擎UOE IP內核 UDP 卸載引擎 (UOE) 是一個 UDP FPGA IP