





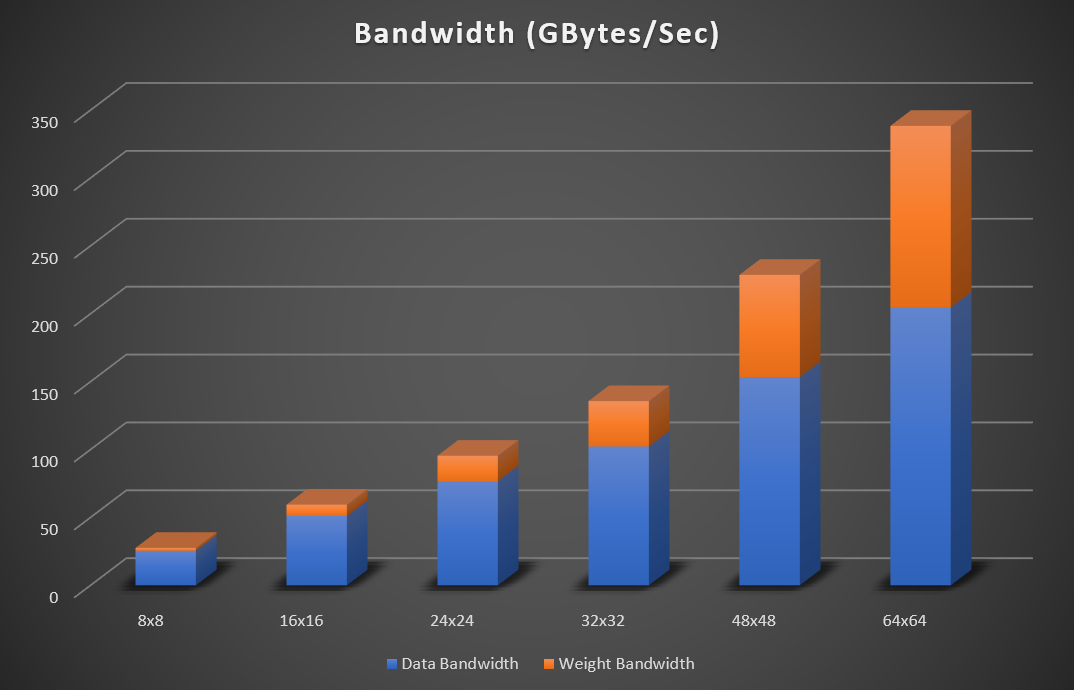
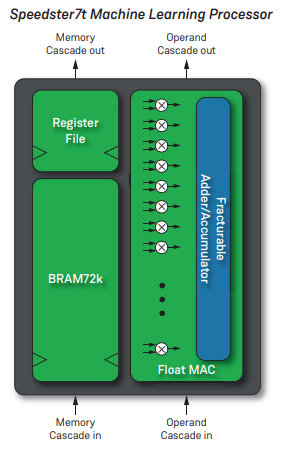


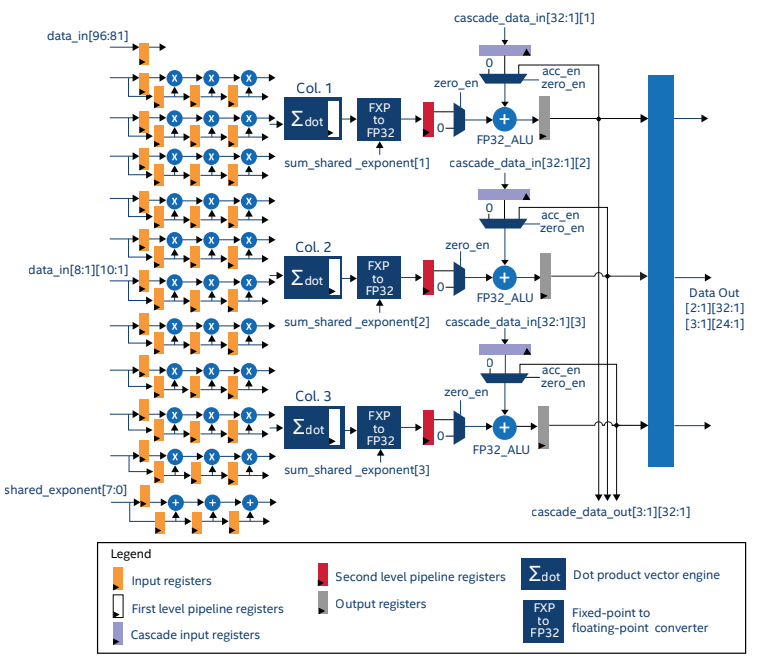


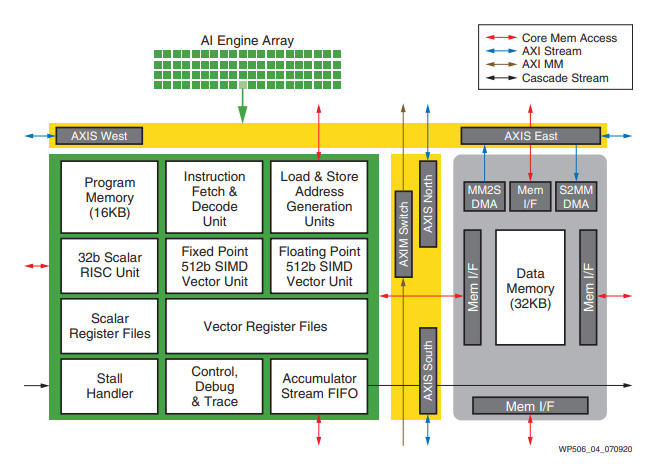



採用英特爾敏捷 7 FPGA 的 IA-780i FPGA 加速器
IA-780i 400G + PCIe Gen5 單寬卡 緊湊型 400G 卡,具有 Agilex 的強大功能 英特爾敏捷x 7 I 系列 FPGA 針對應用進行了優化
IA-780i 400G + PCIe Gen5 單寬卡 緊湊型 400G 卡,具有 Agilex 的強大功能 英特爾敏捷x 7 I 系列 FPGA 針對應用進行了優化
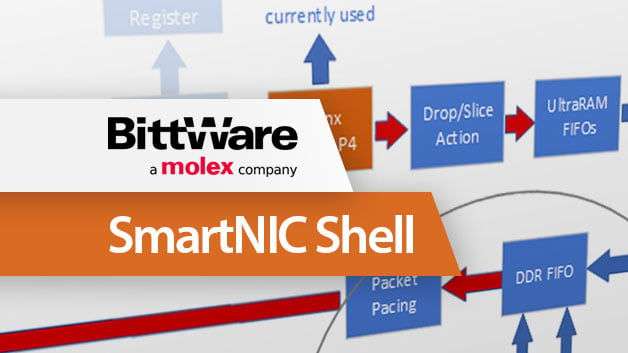
白皮書介紹BittWare的SmartNIC Shell用於網路數據包處理概述SmartNIC Shell是一個完整的工作NIC,在BittWare上實現

BittWare 網路研討會 使用英特爾敏捷 FPGA 的阿克維爾 PCIe 第 4 代數據行動器網路研討會 來自原子規則的阿克維爾 IP 最近進行了更新,以支援英特爾®敏捷 ™

定製產品開發 來自 BittWare(Molex 公司)的設計 + 製造 來自 BittWare(Molex 公司)的定製產品開發設計 + 製造 建立在我們的基礎上